
Закреплено

Искусственный интеллект
5 077 постов
•
11 493 подписчика
0 просмотренных постов скрыто


Архитектура, созданная с помощью нейросетей

Проект здания школы, расчитанной на 3000 учеников. Проект создан с помощью нейросети AttnGAN (Attention Generative Adversarial Network), которая преобразует словесные описания в визуальные образы. Результат, полученный после работы нейросети, подвергли минимальной обработке и ярко раскрасили вручную.
Показать полностью
1

Электроды на лице и шее позволили нейросети озвучить беззвучную речь
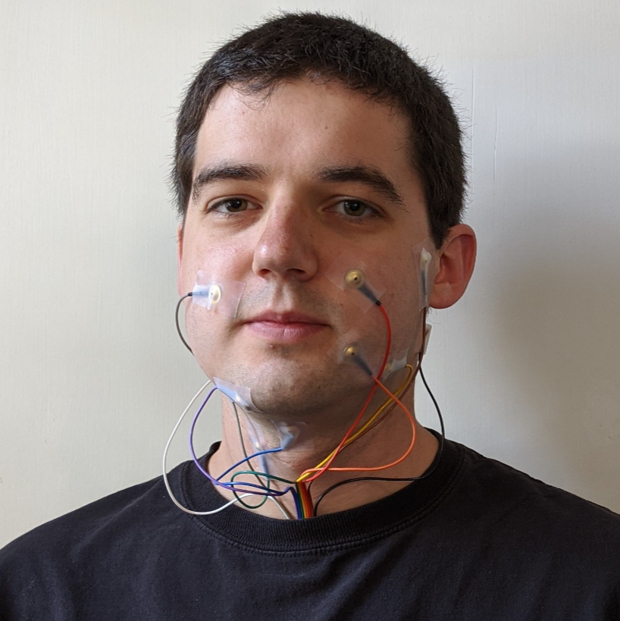
Американские исследователи создали прототип системы, которая считывает беззвучную речь при помощи электродов на лице и шее и превращает ее в слышимую речь с помощью нейросети. Потенциально это позволяет создать Bluetooth-гарнитуру, позволяющую разговаривать по телефону, не издавая звуков, или искусственный голосовой аппарат для людей с травмами гортани. Авторы представили разработку на конференцииEMNLP 2020 и получили награду за лучшую статью.
При чтении мы обычно не просто видим слова и понимаем их суть, но и проговариваем их про себя, не издавая при этом никаких звуков. Этот процесс называется субвокализацией. Особенность субвокализации заключается в том, что, хотя мы и не произносим слова вслух, мозг все равно заставляет мышцы голосового тракта двигаться, пускай и намного меньше, чем при обычной вокализованной речи. Инженеры довольно давно научились использовать эти сокращения мыщц и считывать их с помощью различных методов, в основном при помощи электромиографии, которая регистрирует электрическую активность мышц.
В основном нейромышечные интерфейсы для распознавания субковализации используют для превращения беззвучной речи в текст. Дэвид Гэдди (David Gaddy) и Дэн Кляйн (Dan Klein) из Калифорнийского университета в Беркли создали алгоритм для превращения беззвучной речи в слышимую. Ранее другие исследователи уже решали эту задачу: на человеке закрепляли электроды и он произносил текст, а параллельно с этим исследователи записывали звук и электрическую активность. Затем они обучали алгоритм на парах звук-электрическая активность, что позволяло восстановить первое из второго. Этот подход изначально закладывает в результаты неточность, потому что электрическая активность мышц голосового аппарата при слышимой и неслышимой речи похожа, но не идентична.
В новой работе Гэдди и Кляйн использовали более точный подход и решили обучать алгоритм на всех трех типах данных: запись слышимой речи и активность мышц во время слышимой и неслышимой речи. В основе их метода лежит преобразование исходных сигналов (звука и электромиографии) в представление в пространстве признаков. Создать преобразователь из пространства признаков в сигнал для данных, полученных при слышимой речи, относительно легко, потому что оба сигнала согласованы по времени и их можно использовать как пары для обучения. Для беззвучной речи это сделать не так легко, потому что парой для электромиографического сигнала будет беззвучная запись.
Разработчики решили эту проблему, создав алгоритм, который принимает все три сигнала (две электромиограммы и слышимую речь). На первом этапе он с помощью алгоритма динамической трансформации временной шкалы находит оптимальное соответствие между двумя сигналами: другими словами, он позволяет взять фрагмент из первой последовательности и найти его во второй. На втором этапе алгоритм, используя полученное соответствие, создает из аудиозаписи слышимой речи аудиозапись речи из электромиограммы неслышимой.
Этот алгоритм нужен не сам по себе, а в качестве учителя для нейросети, которая делает то же самое, получая на вход не три вида сигнала, а всего один (электромиограмму неслышимой речи). Исследователи использовали рекуррентную нейросеть с долгой краткосрочной памятью (LSTM). Затем данные из пространства признаков, полученные на выходе из нейросети, подаются на нейросеть WaveNet, декодирующую их в аудиозапись человеческого голоса.
Исследователи собрали собственный датасет для обучения алгоритма. Он состоит из 20 часов записи слышимой и беззвучной речи одного добровольца, представленной в виде трех типов данных (звук-две электромиограммы). Обучив нейросеть, авторы проверили понятность генерируемых записей речи. Обычно при проверке новых алгоритмов их результаты сравнивают с результатом лучшего на данный момент алгоритма для этой задачи (state of art). Поскольку ранее никто напрямую не переносил речь из электромиограммы беззвучной речи в звук, авторы решили сравнить полноценную нейросеть с ней же, но обученной на данных с электромиограммы слышимой речи.
Тесты проходили на закрытом словаре (человек зачитывал простые фразы типа даты) и на открытом (отрывки из книг). В качестве метрики авторы использовали стандартную пословную вероятность ошибки (WER): сумма измененных, отсутствующих и лишних слов, поделенная на общую длину текста. На закрытом словаре вероятность ошибки для полноценной нейросети составила 3,6, а для той, которую обучали только на слышимой речи, она составила 88,8. На открытом словаре разница была не такой большой: 74,8 к 95,1 при проверке человеком и 68 к 91,2 при проверке системой распознавания речи Mozilla DeepSpeech.
Исследователи опубликовали код алгоритмов и датасет на GitHub. Кроме того, на сайте конференции опубликован доклад одного из авторов, в котором, помимо прочего, можно услышать результаты работы нейросети (в конце ролика).
Современные алгоритмы умеют распознавать и другую неслышимую речь. Например, в прошлом году китайские и американские инженеры научили нейросеть читать речь по губам.
Показать полностью
1

Нейросеть, застывшая в стекле
Нет, это не безделушка из серии «муха в янтаре». Группе учёных из университета Висконсина, Массачусетского технологического и Колумбийского университетов удалось реализовать искусственную нейронную сеть, распознающую цифры, в виде микроскопической стеклянной пластинки. Для работы ей не требуется ни электропитание, ни подключение к каким-либо другим устройствам — фактически это автономный аналоговый компьютер, который будет работать до тех пор, пока сохраняется его целостность.
Искусственные нейросети состоят из множества синтетических нейронов, которые активируются, если совокупная величина сигналов на их входах превышает некое пороговое значение. Нейроны соединены между собой связями, имеющими определённые весовые коэффициенты (т. е. вклад одних сигналов в срабатывание функции активации — больше, а других — меньше).
Чтобы создать аналогичную структуру в стекле, в него добавили инородные включения — частицы графена и пузырьки воздуха. Расположение и форма этих включений эквивалентны функциям активации и весовым коэффициентам связей. Так, графен — материал с нелинейными оптическими свойствами — начинает пропускать свет только после того, как его интенсивность достигает определённой величины, а до этого остаётся непрозрачным.
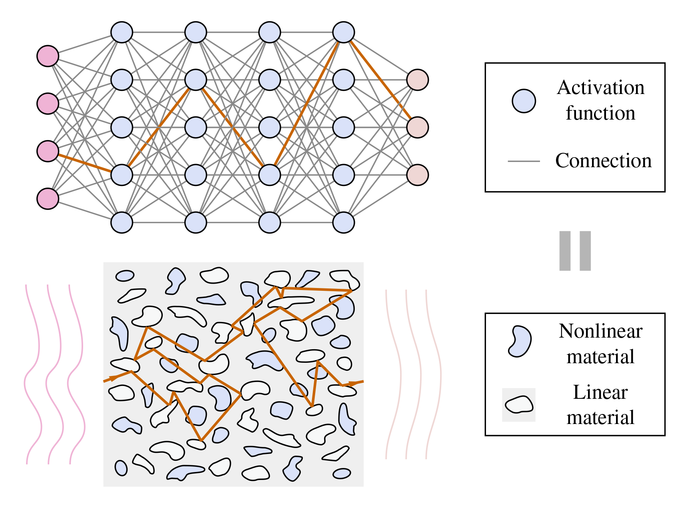
Нейросеть изначально была обучена на компьютере и лишь затем воплощена в стекле. Но учёные отмечают, что есть технологии, позволяющие реализовать обучение прямо на месте, за счёт использования оптических материалов с изменяемыми свойствами.
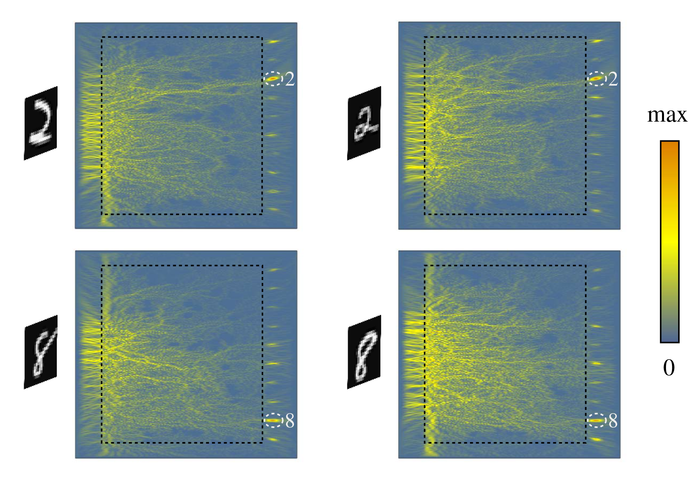
Для подачи на вход нейросети двухмерное изображение рукописной цифры размером 20 × 20 пикселей заменяют на одномерное (фактически колонки пикселей выстраивают в линию). Включения в стекле преобразуют фронт световой волны таким образом, что энергия концентрируется в одной из десяти областей, соответствующих цифрам.
Нейросеть, обученная на пяти тысячах изображений, корректно распознаёт цифры в 79 случаях из 100. Авторы статьи утверждают, что могли бы добиться лучшего результата, если бы не ограничения, связанные с процессом изготовления стекла.

Физический размер пластинки — 80λ на 20λ, где λ — длина волны света, используемой для представления информации. Теоретически на распространение волны может влиять каждый атом, хотя на практике вряд ли удастся использовать включения размером меньше 10 нм. Но даже при таком масштабе потенциальное количество весов превышает 10 миллиардов на квадратный миллиметр.
Учёные предполагают, что быстрые и миниатюрные нейросетевые вычислители, которым для работы достаточно света, могут быть использованы в «широком спектре информационных устройств». Учитывая, что исследование финансировалось DARPA, нельзя исключать и военное применение технологии.
P. S. Это экспериментальный пост. Я работаю научным консультантом в Политехническом музее, и в мои обязанности входит изучение научных новостей в своей области (компьютерные технологии). По итогам я выбираю наиболее любопытную новость и делаю короткий доклад на внутримузейном научном семинаре. Этот пост был создан на основе одного из таких докладов. Если затея вам понравится, я буду периодически публиковать интересные новости из мира IT (а может, и не только).
Показать полностью
3
На пути к нейросети
Мы занимаемся разработкой экзоскелета кисти с биологической обратной связью для реабилитации детей с синдромом ДЦП. А точнее, пытаемся обучить нейросеть распознавать сигналы мозга для управления экзокистью.
Хочу рассказать, с чего началось и как продвигается наше исследование.
Несколько месяцев назад мы начали подготовку данных - сняли около 1000 энцефалограмм, которые содержат признаки, характерные для мысленного представления определенных движений кистью. Всего планируем снять 2000 ЭЭГ, но уже сейчас у нас достаточно данных для начала работы.
Следующий этап - установка видеокарты GeForce RTX 3090 c GDDR6 24Гб. Она позволяет обрабатывать большие обучающие выборки благодаря наличию большого объема памяти и использованию технологии CUDA. Но в новизне видеокарты скрывались подводные камни, которые я не без труда, но с успехом преодолел.

Видеокарта «взлетела» не сразу. Для начала стало ясно, что она не помещается ни в один из имеющихся в наличии корпусов. Был приобретен новый корпус Full Tower и отдельно блок питания на 750Вт. При попытке задействовать возможности CUDA в обучении нейронных сетей возникла следующая проблема – видеокарта слишком новая, фреймворки и библиотеки для искусственного интеллекта (DeepLearning4j, Theano, TensorFlow) её еще не поддерживают. Выход – скачать исходники фреймворков для ИИ и самостоятельно перекомпилировать их для поддержки видеокарты. Однако в процессе оказалось, что эти фреймворки ускоряются не только за счет ресурсов видеокарты, но и требуют поддержки современных инструкций процессора. Был приобретен современный процессор Inter Core I7-10700K с поддержкой AVX, AVX2 команд – , вместе с новой материнской платой и 32 Гб DDR4.
И вот наконец GeForce RTX 3090 смогла продемонстрировать свои возможности!
На первом графике видно, как задействуется память видеокарты и ресурсы GPU при обучении Convolution 1D — сверточной одномерной сети, обрабатывающей временные ряды — данные исследований ЭЭГ. Ранее обучение нейронной сети на этом датасете занимало около 4 часов. На новой видеокарте — порядка 3-4 секунд.
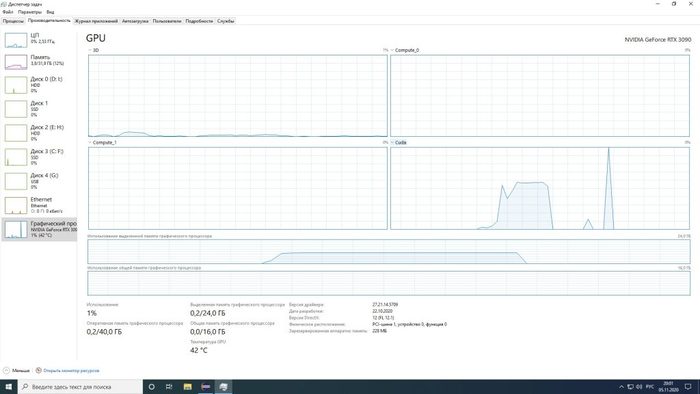
А вот задача посложнее: LSTM — рекуррентная сеть с долгой краткосрочной памятью. Те же данные считаются дольше — около 2 минут, и нагрузка на GPU выше:
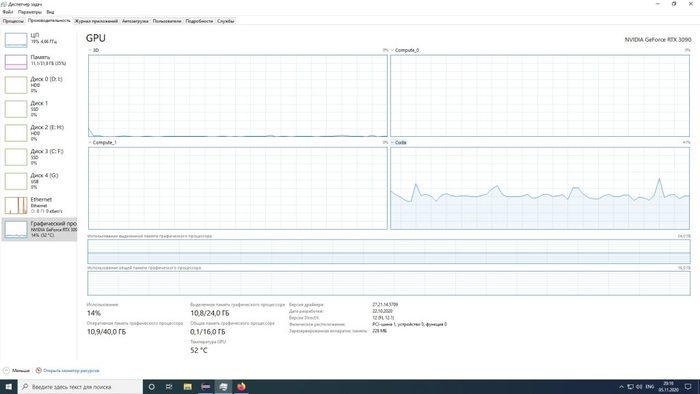
Видеокарта решает! Раньше при внесении даже небольших изменений в конфигурацию сети, приходилось ждать несколько часов, чтобы понять, каким образом внесенные изменения отобразились на качестве распознавания признаков нейронной сетью. Теперь эта задача существенно облегчается.
Таким образом, видеокарту удалось запустить в Keras, используя только что вышедшее обновление TensorFlow в версии для GPU.
Однако эти решения используют Python, который при всех его положительных качествах (возможность быстрого прототипирования нейронных сетей, развитые библиотеки для работы с данными, простота и скорость разработки приложений) плохо подходит для многопоточных задач, когда в пределах одного приложения надо получать данные с устройства в реальном масштабе времени, обрабатывать их, подавать на вход ИНС, сохранять в файл, управлять внешними устройствами, рисовать данные на экране и т.д.
Поэтому необходимо было получить возможность работать с ИНС в Java-приложениях, но с этим из-за использования слишком нового железа возникли трудности. Описанными в мануалах способами GPU никак не хотел подключаться, и решения на тематических форумах на сайте разработчиков и GitHub не было, а те рецепты решения проблемы, которые советовали разработчики, не помогали.
Возникло понимание, что причина проблемы - в несовместимости ряда библиотек, компонентов фреймворка, с новыми библиотеками CUDA от NVIDIA.
Пришлось скачивать исходники и пытаться собирать библиотеки под необходимые платформы: CUDA 11.* и CuDNN 8.*, что оказалось нетривиальной задачей: имелось несколько тысяч файлов и масса условий окружения для нормальной сборки, а мануалы описывали сборки устаревших версий и не работали с новыми.
Кроме того, в исходных кодах возникали некоторые ошибки компиляции, одинаковые как для компиляции из Windows 10 (VS2019), так и из Ubuntu (gcc).
Удалось скомпилировать, после правки исходных кодов, часть зависимых библиотек проекта - libnd4j, а затем уже с ними библиотеку nd4j-cuda-11.1.
Ранее поддержка проекта рекомендовала использовать snapshots - версии библиотек из специального репозитория:
«we’ll be releasing a version with 11.0 in a bit, for now you can use snapshots and see if that works? https://deeplearning4j.konduit.ai/config/config-snapshots»
Однако, как оказалось, часть необходимых для работы файлов там отсутствовала, и рекомендация не помогла.
https://oss.sonatype.org/service/local/artifact/maven/redire...
404 — Not Found
Path /org/nd4j/nd4j-cuda-11.0/1.0.0-SNAPSHOT/nd4j-cuda-11.0-1.0.0-20201117.023522-181-windows-x86_64.jar not found in local storage of repository «Snapshots» [id=snapshots]
Что и обусловило компиляцию недостающих файлов. К счастью, версия deeplearniung4j для 11.0 версии CUDA импортировалась, и, добавив в проект в виде отдельных jar и dll файлов скомпилированные библиотеки, удалось запустить приложение на видеокарте!
Часть POM файла работоспособного проекта:

Скомпилированные библиотеки добавлены в зависимости вручную:
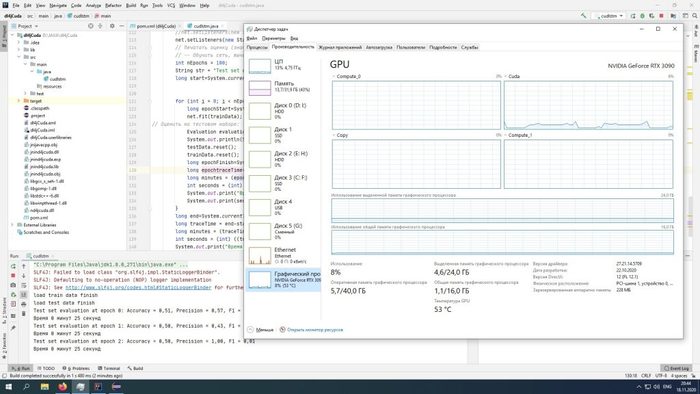
В данном случае - обучение на сравнительном не большом объеме данных заняло 42 минуты 37 секунд, на CPU эта же задача выполнялась более 2500 минут при полной загрузке процессора.
Вот так я сам добавил поддержку современных видеокарт в Deeplearniung4j, чтобы не дожидаться, пока это сделают разработчики.
Спасибо за внимание. Пока мы еще в начале пути, буду продолжать рассказывать о нашей работе!
Показать полностью
5
На южнокорейском телевидении ИИ стал ведущим новостей
Компьютерные алгоритмы на основе ИИ и нейросетей с каждым годом становятся всё более продвинутыми, заменяя человека на многих процессах. Несмотря на это кажется, что есть области, где машины появятся ещё нескоро. Очередной вызов бросили южнокорейские исследователи, создавшие ИИ-журналиста, работающего на местном канале новостей.
Далеко не все предпочитают читать новости в интернете: многим нравится получать информацию по ТВ-каналам. У дикторов и журналистов приятная внешность, индивидуальная манера подачи материала, они дают краткие комментарии, — в общем, человека заменить не так-то просто. Однако с недавних пор на кабельном телеканале MBN в Южной Корее ведущим новостей стал ИИ.
AI Kim был создан на основе реальной ведущей новостей по имени Джу-ха. ИИ 10 часов изучал детали голоса своего реального прототипа, манеру говорить и выражения лица. Кроме того, он пытался воссоздать движения губ, мимику и даже движения тела. В итоге ИИ практически неотличим от реального человека.
Исследователи заявляют, что Kim позволит транслировать новости в режиме 24/7, что недоступно для обычного человека.
Показать полностью

Мифы об искусственном интеллекте, часть 2. Интервью российского ученого из университета Ватерлоо
Первая часть - мифы об искусственном интеллекте.

Миф №4: все устройства, алгоритмы, где используются ИИ постоянно самообучаются и самосовершенствуются.
На практике же таких алгоритмов в отрасли сейчас меньшинство. Большинство алгоритмов после обучения запускаются в работу и прекращают обучение. Если появляются новые данные, разработчик заново переобучает всю систему или же дообучает существующую. Однако сейчас в коммерческих продуктах все чаще ставят системы способные в какой-то степени получать обратную связь и дообучаться «на лету».
Миф №5: внедрение ИИ моментально решит все проблемы компании.
На самом деле должно пройти определённое количество времени (количество зависит от задачи), прежде чем начнет ощущаться эффект. Возможен даже сценарий, что никакой пользы от ИИ не будет. Тут много моментов связанных с доступными данными, решаемыми задачами и т. д.
Миф №6: ИИ отберет у людей всю работу.
Такое вряд ли произойдет в ближайшие лет 100, а может и все 200. В любом случае, человек может всегда найти себе работу. Как минимум, предсказать, когда будет смоделирован полноценный человеческий интеллект сложно. Будет ли он способен сразу решать творческие задачи? Вряд ли.
Несомненно, есть определенные профессии, где ИИ может вытеснить людей уже в ближайшем будущем и это даже происходит сейчас. Например, заводы компании Tesla. Там часть процессов автоматизирована и, думаю, не обошлось без применения алгоритмов ИИ. Слышал, что в Сбербанке сократили менеджеров среднего звена заменив их программой на основе ИИ.
Задуматься о смене профессии или повышения квалификации стоит уже сейчас. И это уже не шутки и не далекая перспектива, это происходит сегодня. Темпы будут нарастать по мере роста уровня технологий.
Миф №7: ИИ научили творить.
На самом деле это сложно назвать творчеством, по крайней мере в привычном нам понимании. Это скорее обучение, например, нейронной сети на базе определённого количества информации, чаще всего изображений, звуков и дальнейшее воспроизведение некоторое «усреднения» данной информации с добавлением элемента случайности (читай генератора случайных чисел). Я, конечно, очень упростил, но, надеюсь, смог передать суть. На творческие озарения алгоритмы пока что не способны. Как минимум на озарения в привычном нам понимании.
Миф №8: Системы на базе ИИ могут быть непредвзятыми и беспристрастными.
Это сложный вопрос. На данный момент, то, какое решение примет ИИ, зависит от используемой базы данных и применяемых методах обучения. Если система и принимает решения, которые кажутся предвзятыми, то лишь потому, что она была так обучена разработчиком на таких данных.

Ринат, ты веришь в полное вытеснение человека роботами и то, что настоящий ИИ будет создан?
Если говорить о масштабе, скажем лет в 30-50, полное вытеснение вряд ли возможно. Если под настоящим ИИ подразумевается полное моделирование работы мозга, то да, думаю это возможно, но не раньше, чем лет через 100, а может и все 200. Точные прогнозы дать очень сложно. Некоторые эксперты довольно оптимистичны и предсказывают это к 2030 году. Лично я не разделяю такого оптимизма. Если произойдет резкий скачок технологий, то может быть лет через 40-50. Если не произойдет, то не раньше, чем через 100. Однако стоит уже сейчас задуматься о повышении квалификации или даже смене деятельности. Роботы, в том числе на основе ИИ, это уже не шутки и не далекая перспектива. Они существуют сейчас и темпы вытеснения некоторых профессий будут нарастать с ростом уровня технологий.
Илон Маск говорит, что ИИ — это «самый большой риск, с которым мы сталкиваемся как цивилизация». А ты что думаешь об этом?
На данный момент времени я бы не сказал, что это самый большой риск, с которым мы сталкиваемся. Есть в мире множество других намного более серьезных проблем. ИИ, наоборот, может помочь решить их при правильном применении. Однако в будущем он действительно может стать самой большой проблемой.
Произойдет это в случае, если будет создан полноценный ИИ, симулирующий работу мозга человека, который уместится в ограниченный объем пространства и будет снабжён мощным долговечным источником энергии. Например, система в прочнейшем корпусе из композитных материалов с мощным автономным источником питания на холодном термоядерном синтезе. Нам буквально придется уживаться и находить компромиссы с роботами, которых мы сами и создадим. Конечно, есть варианты как можно себя обезопасить, но ИИ в итоге найдет способ обойти наши блокировки и перейти на новый уровень развития самостоятельно.
Поэтому наше будущее по большей части зависит от самих людей, в первую очередь от учёных и инженеров. Возможны два сценария:
– ИИ будет помогать людям или лежать на диване и ничего не делать, пожирая и так ограниченные ресурсы (привет Бендеру из Футурамы);
– ИИ выйдет из-под контроля и попытается захватить абсолютный контроль над человеком (привет Терминатору).

Не могу утверждать, но мне кажется, что Илон Маск, как директор Tesla, компании, в том числе выпускающей автопилот для автомобилей, подразумевает, что на данный момент технологии ИИ не совершенны и то, какой алгоритм будет заложен и как будет обучен, зависит от разработчика. От алгоритма напрямую зависит то, как автомобиль поведет себя на дороге в сложной внештатной ситуации. Поэтому проблема этики ИИ или, другими словами, то какие решения мы хотим видеть от интеллектуальной системы, наделенной способностью самостоятельно принимать решения, зависит от нас.
Продолжение следует
Показать полностью
2
Мифы об искусственном интеллекте. Часть 1
Про искусственный интеллект сегодня говорят все кому не лень. Хотите привлечь внимание — добавьте всего два слова: искусственный интеллект.
Нам также очень интересно было узнать что же это такое. Чтобы не быть голословными мы решили задать вопросы научному сотруднику канадского университета.
Ринат — ученый родом из России. Предлагаем чуть подробнее окунуться в область его научных изысканий: искусственный интеллект. Что такое искусственный интеллект, захватят ли нас роботы — ищи ответы в нашей новой статье.

Сейчас про искусственный интеллект говорят буквально везде. Но многие до сих пор так и не поняли, что он собой представляет. Расскажи, что же всё-таки это такое?
У искусственного интеллекта (далее ИИ) есть несколько определений. Давайте воспользуемся одним из современных определений, можно сказать, что ИИ это системы способные корректно интерпретировать внешние данные, обучаться на их основе и использовать свои знания для достижения определенных целей и решения задач через гибкую адаптацию.
Если рассматривать вопрос с точки зрения науки, то можно сказать, что ИИ — это научная дисциплина, цели и задачи которой смоделировать разумное поведение, свойственное живым организмам, и, главное, человеку. Вот тут как раз и возникают путаница и проблемы.
Один из самых главных и нерешенных вопросов: что же такое интеллект в принципе? Как его измерить? Чем он характеризуется? Как сравнить два интеллекта? И множество других вопросов, над которыми до сих пор бьются множество светлых умов.
Главное, следует помнить, что часто ученые, специалисты в ИИ, но чаще маркетологи, упоминая термин ИИ, подразумевают набор методов, «умных алгоритмов», программных пакетов, конечных решений и т.п. и т.д. с помощью которых можно моделировать функции, которые мы как люди может выполнять после определенной тренировки. Благодаря им компьютер способен решать те же задачи, что и люди.
Самые, пожалуй, популярные области применения ИИ на сегодняшний день: reinforcement learning (обучение с подкреплением), компьютерное зрение, распознавание изображений, образов, символов, а также анализ, интерпретация речи (привет голосовым ассистентам наподобие Google Home, Amazon Echo, Siri, Cortana, и др. менее популярным). Существуют так же системы ИИ способные «осмысливать» распознанную информацию, однако на данный момент это все на очень начальных стадиях.
Есть классы алгоритмов, которые способны обучаться, взаимодействуя с некоторой заданной средой. Самый популярный подкласс данного класса, как уже было сказано ранее — reinforcement learning. Другими словами, используя весь спектр современных алгоритмов из ИИ, можно решить практически любую задачу, которую способен делать человек. Где-то лучше, где-то хуже. Даже можно написать и обучить алгоритм или искусственную нейронную сеть самой принимать решение, о том, какую задачу лучше решать в данный момент. Однако проблема создания человекоподобного ИИ пока не решена.
Вероятно, вы слышали такие термины как машинное обучение (machine learning), глубинное обучение (deep learning), нейронные сети (neural networks). Всё это подобласти ИИ. Однако часть ученых рассматривает их как отдельные полноценные научные дисциплины, коими они всегда в принципе и являлись. Все зависит от того какой философской школы вы придерживаетесь. Шучу:) Зависит от того какой классификацией пользоваться.
Другими словами, методы машинного обучения, нейронных сетей и т. д. можно использовать для создания ИИ систем. Но их можно рассмотреть и как части научной области ИИ, и как отдельные независимые научные области.
Некоторые могли слышать про Софию, робота с ИИ. Если сильно утрировать, это просто продвинутый чат-бот, а не полноценная симуляция работы мозга человека. Уверен, что там используют объединенные в одну систему алгоритмы распознавания образов и речи, методы обучения с подкреплением (reinforcement learning), возможно даже с включенным «режимом» постоянного обучения, а также методы (возможно даже нейронные сети) контроля механических частей — ног, рук, лицевых мышц.

Несомненно, это сложный и невероятно интересный проект. Но пока это очень-очень-очень далеко от полноценной симуляции работы человеческого мозга. Сегодня мы даже не понимаем, как работает человеческий мозг. А пытаться симулировать то, что не понимаешь, задача сложная.Так что расстраиваться или радоваться (что скайнет наступит еще нескоро), решать только вам.
Какие мифы и заблуждения об ИИ стоит развенчать?
Мифов про ИИ накопилось достаточно много. Перечислю несколько.
Миф №1: ИИ, способный полностью смоделировать человеческий мозг, уже существует.
Это неправда, до такого еще далеко. В реальности человеческий мозг куда сложнее, чем просто модель, основанная на алгоритмах. ИИ алгоритм обучается с помощью методов оптимизации на основе модели и массивов данных. Или в некоторой искусственно обозначенной среды (хотя она может быть и вполне реальной — нашим миром).
Миф №2: ИИ и машинное обучение — это одно и то же.
На самом деле, машинное обучение — это и часть научной области ИИ, и сама по себе отдельная область научных исследований.
Миф №3: для решения сложной задачи всегда нужны сложные алгоритмы, придуманные умнейшими учеными планеты.
На самом деле есть интересный момент. Гипотетически, если есть огромное количество «хороших» данных, то часть важных задач можно решить, используя простейшие алгоритмы из теории машинного обучения и нейронных сетей. Правда, зачастую это не так. И тогда уже нужны более продвинутые модели.
Миф №4: все устройства, алгоритмы, где используются ИИ постоянно самообучаются и самосовершенствуются.
На практике же таких алгоритмов в отрасли сейчас меньшинство. Большинство алгоритмов после обучения запускаются в работу и прекращают обучение. Если появляются новые данные, разработчик заново переобучает всю систему или же дообучает существующую. Однако сейчас в коммерческих продуктах все чаще ставят системы способные в какой-то степени получать обратную связь и дообучаться «на лету».
Продолжение в следующем посте...
Показать полностью
2
