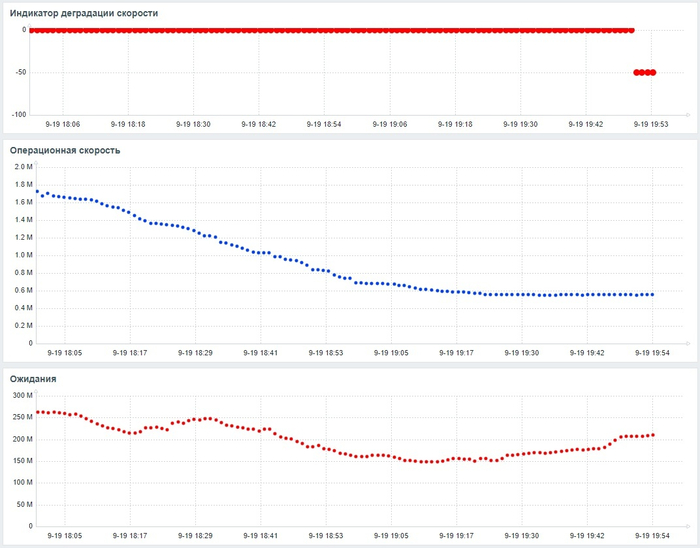
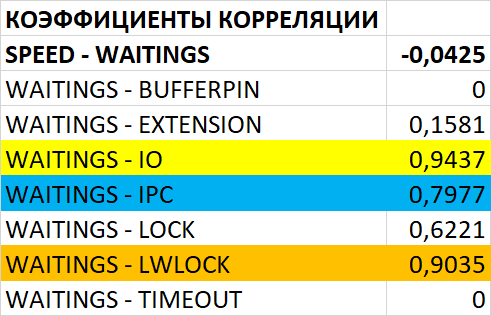
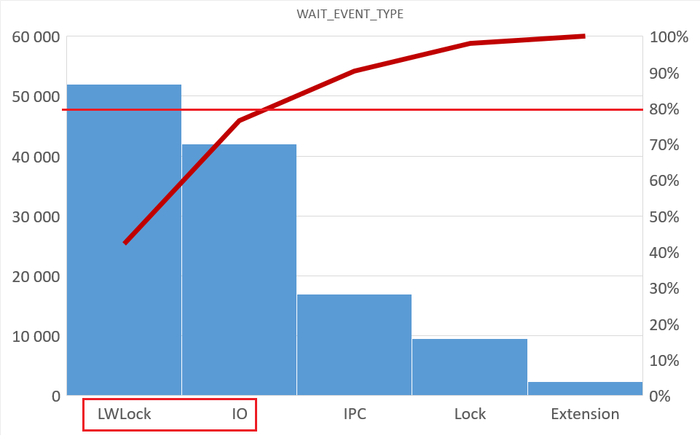
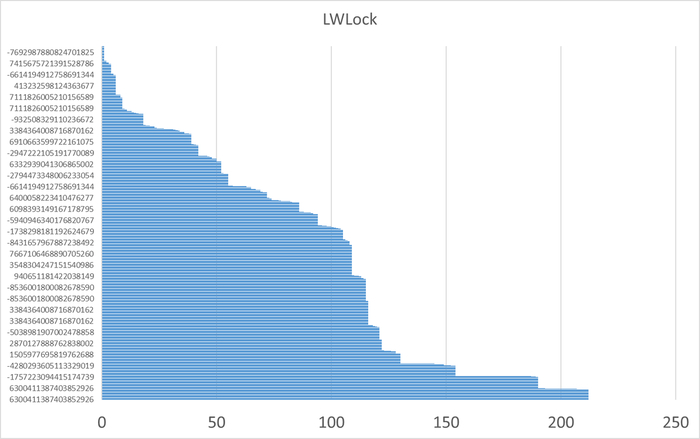
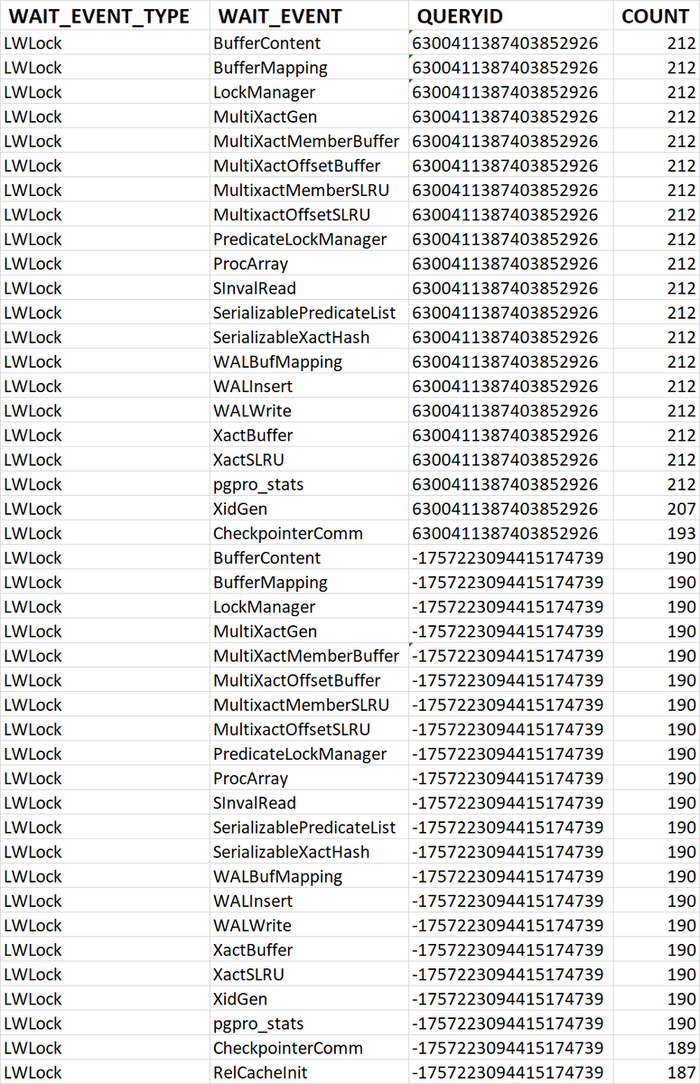
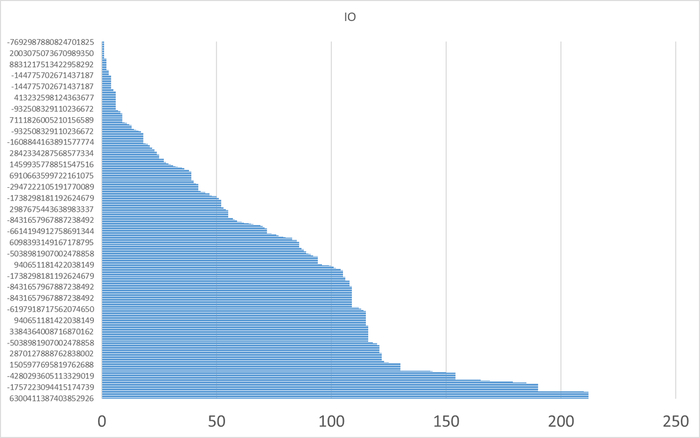
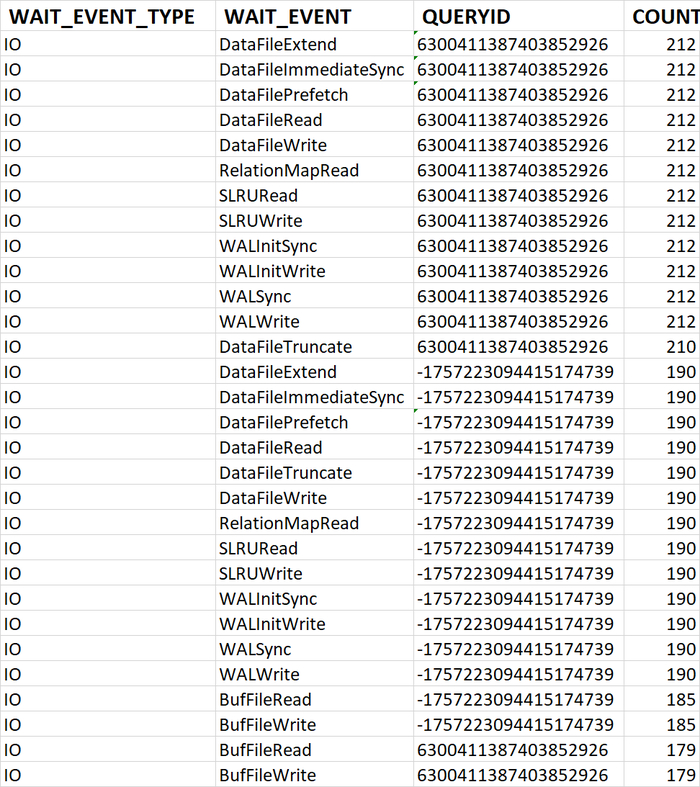
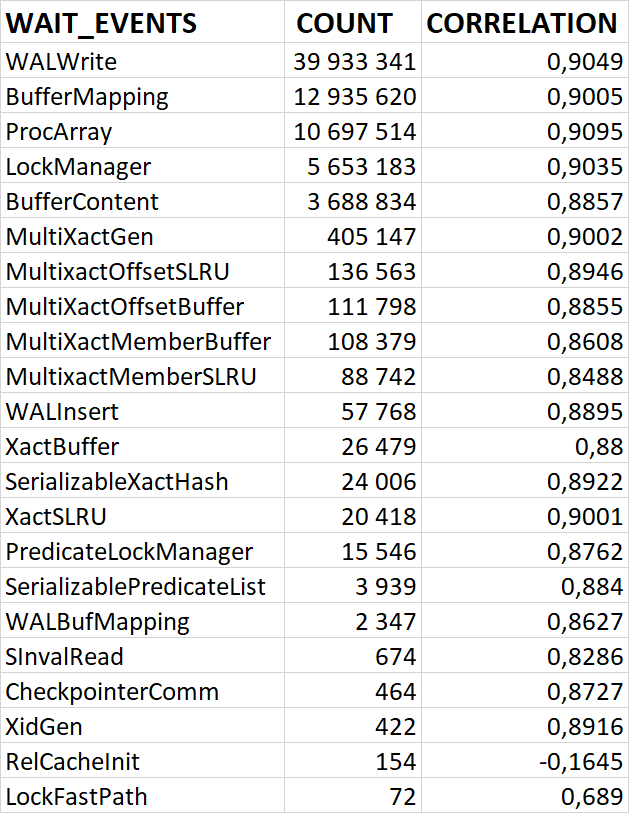
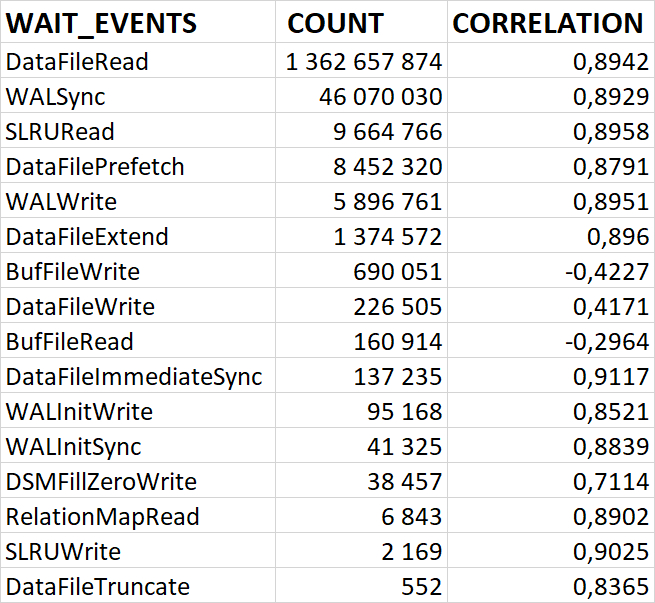
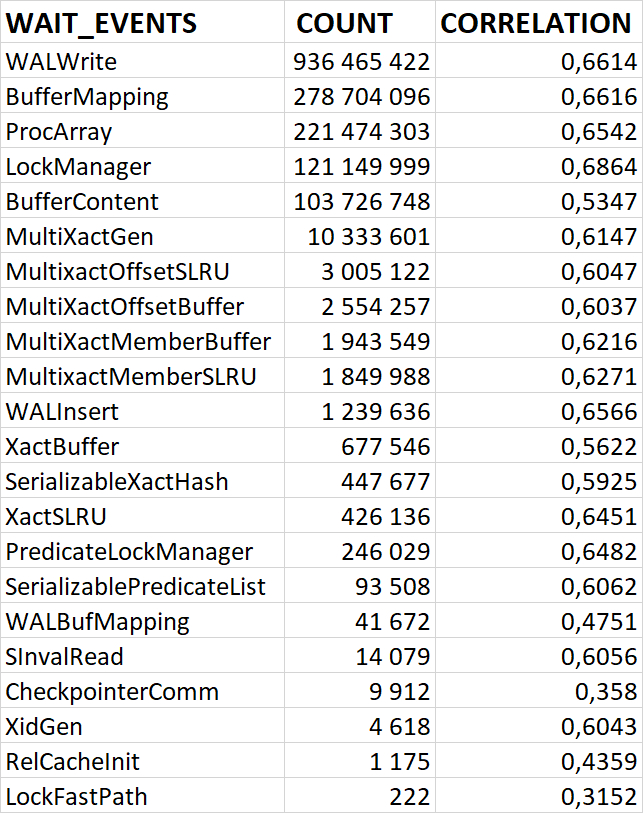
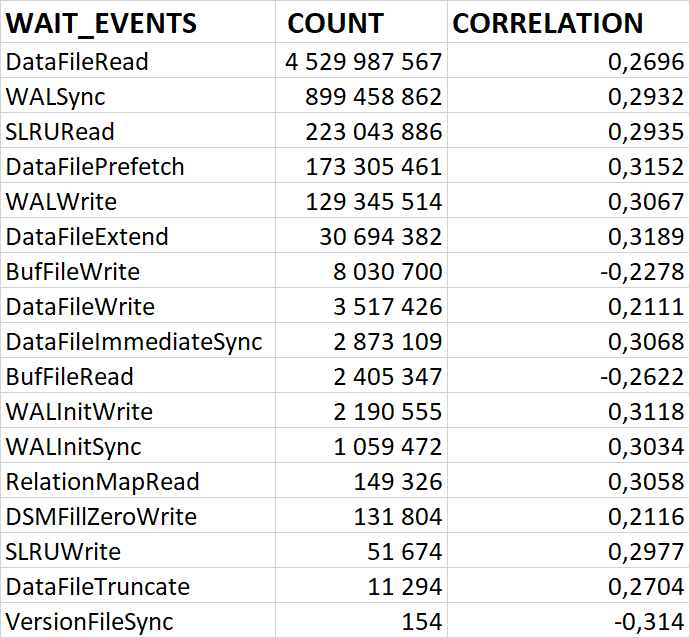
80% ожиданий СУБД вызваны ожиданиями типа LWLock и IO.
Характерные события ожидания типа LWLock
BufferContent: Ожидание при обращении к странице данных в памяти.
BufferMapping: Ожидание при связывании блока данных с буфером в пуле буферов.
CheckpointerComm: Ожидание при управлении запросами fsync.
DynamicSharedMemoryControl: Ожидание при чтении или изменении информации о выделении динамической общей памяти.
LockFastPath: Ожидание при чтении или изменении информации процесса о блокировках по быстрому пути.
LockManager: Ожидание при чтении или изменении информации о «тяжёлых» блокировках.
MultiXactGen: Ожидание при чтении или изменении общего состояния мультитранзакций.
MultiXactMemberBuffer: Ожидание ввода/вывода с SLRU-буфером данных о членах мультитранзакций.
MultixactMemberSLRU: Ожидание при обращении к SLRU-кешу данных о членах мультитранзакций.
MultiXactOffsetBuffer: Ожидание ввода/вывода с SLRU-буфером данных о смещениях мультитранзакций.
MultixactOffsetSLRU: Ожидание при обращении к SLRU-кешу данных о смещениях мультитранзакций.
PredicateLockManager: Ожидание при обращении к информации о предикатных блокировках, используемой сериализуемыми транзакциями.
ProcArray: Ожидание при обращении к общим структурам данных в рамках процесса (например, при получении снимка или чтении идентификатора транзакции в сеансе).
RelCacheInit: Ожидание при чтении или изменении файла инициализации кеша отношения (pg_internal.init).
SerializablePredicateList: Ожидание при обращении к списку предикатных блокировок, удерживаемых сериализуемыми транзакциями.
SerializableXactHash: Ожидание при чтении или изменении информации о сериализуемых транзакциях.
SInvalRead: Ожидание при получении сообщений из общей очереди сообщений аннулирования.
WALBufMapping: Ожидание при замене страницы в буферах WAL.
WALInsert: Ожидание при добавлении записей WAL в буфер в памяти.
WALWrite: Ожидание при записи буферов WAL на диск.
XactBuffer: Ожидание ввода/вывода с SLRU-буфером данных о состоянии транзакций.
XactSLRU: Ожидание при обращении к SLRU-кешу данных о состоянии транзакций.
XidGen: Ожидание при выделении нового идентификатора транзакции.
Сокращение периода, когда серверный процесс, обрабатывающий SQL-запрос к системе управления базами данных (СУБД), сталкивается с событием ожидания, напрямую влияет на скорость выполнения запроса. Чем меньше времени процесс простаивает в ожидании, тем быстрее завершается SQL-запрос.
При многократном повторении запросов, минимизация времени ожидания приводит к увеличению количества выполненных запросов за единицу времени. В конечном итоге, это позволяет предоставить клиенту больший объем полезной информации за тот же период. Таким образом, снижение задержек в обработке SQL-запросов ведет к повышению общей производительности системы.
Следствие из гипотезы - необходимое условие определения причины снижения производительности СУБД.
Для оптимизации производительности СУБД необходимо определять и оптимизировать SQL запросы в ходе выполнения которых возникают ожидания имеющие наибольшую корреляцию со снижением операционной скорости СУБД.
Доказательство следствия:
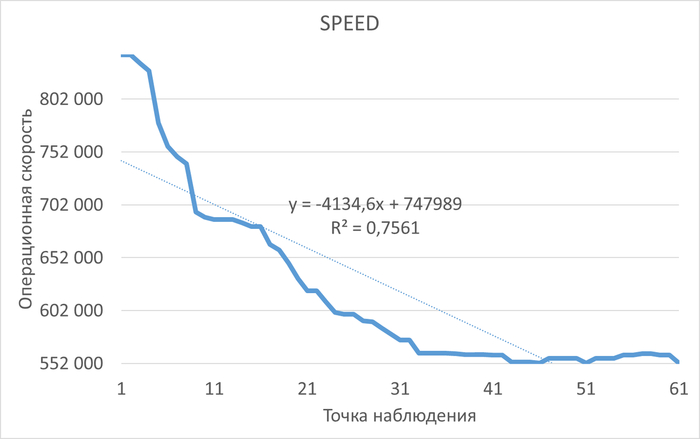
1. Предпосылка (Определение метрики): Главная метрика производительности СУБД — операционная скорость (Operational Throughput). Это количество транзакций или запросов, выполняемых в единицу времени. Снижение этой скорости — прямое проявление проблемы производительности.
2. Аксиома (Причина снижения скорости): СУБД — это система с ограниченными ресурсами (CPU, Disk I/O, Memory, Network, Locks). Любое снижение операционной скорости напрямую следует из того, что запросы (или части системы) вынуждены ожидать (WAIT) освобождения этих ресурсов. Вся современная диагностика производительности строится на анализе ожиданий (Wait Interface methodology).
3. Логический шаг 1 (Корреляция ожиданий и скорости): Если в системе присутствуют ожидания определенного типа (например, ожидание записи в журнал WRITELOG или ожидание блокировки LCK_M_), и их совокупная длительность имеет наибольшую корреляцию со снижением операционной скорости, это статистически доказывает, что именно этот тип ожиданий является основным "узким местом" (bottleneck) в данный момент.
4. Логический шаг 2 (Источник ожиданий): Эти ожидания не возникают сами по себе. Каждое ожидание является прямым следствием выполнения конкретного запроса или действия:
Ожидание IO (чтение с диска) вызывается запросами, выполняющими большие сканирования таблиц.
Ожидание WAL вызывается запросами, которые выполняют интенсивную операцию журналирования (индексы, большие UPDATE/INSERT).
Ожидание Lock вызывается запросами, которые блокируют большие объемы данных на длительное время.
Следовательно, чтобы устранить ожидание, необходимо найти и оптимизировать конкретные SQL-запросы, в ходе выполнения которых эти ожидания возникают.
Снижение операционной скорости → вызвано накоплением времени ожиданий → которое, в свою очередь, вызвано выполнением конкретных SQL-запросов.
Таким образом, необходимым условием для эффективной оптимизации является:
Определение типов ожиданий, наиболее сильно коррелирующих с падением производительности.
Идентификация и последующий анализ SQL-запросов, порождающих эти ожидания.
Оптимизация именно этих запросов (через изменение индексов, логики запроса, структуры базы и т.д.).
Почему это необходимое условие?
Потому что попытки оптимизировать производительность вслепую, без этого анализа, заведомо неэффективны. Можно бесконечно:
Добавлять лишние индексы, которые замедлят операции записи.
Наращивать hardware-мощность (больше CPU, память), не устраняя главную проблему (например, блокировки).
Тюнить общие параметры сервера, не влияя на плохо написанные запросы.
Только целевая оптимизация запросов-виновников напрямую уменьшает время ключевых ожиданий, что и приводит к росту операционной скорости СУБД.
Вывод:
Представленное утверждение является верным и доказанным следствием из современной методологии анализа производительности СУБД, основанной на статистике ожиданий (Wait Events). Оно описывает не просто возможный путь, а необходимое условие — необходимый и систематический подход к решению проблемы снижения производительности.
Сокращение периода, когда серверный процесс, обрабатывающий SQL-запрос к системе управления базами данных (СУБД), сталкивается с событием ожидания, напрямую влияет на скорость выполнения запроса. Чем меньше времени процесс простаивает в ожидании, тем быстрее завершается SQL-запрос.
При многократном повторении запросов, минимизация времени ожидания приводит к увеличению количества выполненных запросов за единицу времени. В конечном итоге, это позволяет предоставить клиенту больший объем полезной информации за тот же период. Таким образом, снижение задержек в обработке SQL-запросов ведет к повышению общей производительности системы.
Любой SQL-запрос, выполняемый серверным процессом СУБД, проходит через два типа фаз:
Активная обработка (CPU Bound): Процессор выполняет вычисления — парсинг запроса, построение плана выполнения, соединение таблиц, сортировку данных и т.д.
Ожидание (I/O Bound или Wait Events): Процесс приостанавливает выполнение и ждет наступления какого-либо события. Ключевые виды ожиданий: Дисковый ввод/вывод (I/O): Ожидание чтения данных с диска ( страницы с данными, индексы) или записи журналов (например, Transaction Log). Блокировки (Locking): Ожидание, пока другая транзакция освободит нужную блокировку на строку или таблицу. Сетевые задержки (Network): Ожидание получения следующего пакета данных от клиента или отправки ему результатов. Ожидание ресурсов CPU (CPU Queue): Процесс готов к выполнению, но все ядра процессора заняты другими процессами.
Общее время выполнения запроса (T_total) можно выразить формулой: T_total = T_active + T_wait где:
T_active — совокупное время активной обработки на CPU.
T_wait — совокупное время всех событий ожидания.
Доказательство части 1: Влияние на скорость выполнения одного запроса
Утверждение: Сокращение периода ожидания напрямую влияет на скорость выполнения запроса.
Доказательство:
Логическое рассуждение: Из формулы T_total = T_active + T_wait следует, что T_total является функцией от T_wait. Если значение T_wait уменьшается (при прочих равных условиях, т.е. T_active остается неизменным), то значение T_total также уменьшается. Уменьшение T_total и есть увеличение скорости выполнения запроса. Это прямое и линейное следствие.
Математическая формализация: Пусть T_total_1 = T_active + T_wait_1 После оптимизации (например, добавление индекса для уменьшения времени ожидания чтения с диска) время ожидания сокращается: T_wait_2 < T_wait_1 Время активной обработки может незначительно измениться (например, процессорное время на обход индекса может немного вырасти), но в большинстве сценариев оптимизации ожидания это изменение пренебрежимо мало или даже отрицательно (новый индекс эффективнее). Предположим, T_active ~ const. Следовательно: T_total_2 = T_active + T_wait_2 < T_active + T_wait_1 = T_total_1 Вывод: Время выполнения запроса T_total_2 строго меньше T_total_1.
Практическое подтверждение (Архитектура СУБД): Все современные СУБД (Oracle, SQL Server, PostgreSQL, MySQL) имеют встроенные механизмы диагностики — Мониторинг ожиданий (Wait Event Statistics). Администраторы баз данных используют запросы к системным представлениям (например, sys.dm_os_wait_stats в SQL Server или pg_stat_activity в PostgreSQL), чтобы выявить основные wait events для медленных запросов. Пример: Если главный тип ожидания — IO (ожидание чтения данных с диска), его сокращение путем добавления оперативной памяти (чтобы кэшировать данные) или добавления более быстрых SSD-дисков всегда приводит к ускорению выполнения целевого запроса. Это эмпирически проверяемый и доказуемый факт.
Заключение по части 1:
Гипотеза верна. Время ожидания является прямой аддитивной составляющей общего времени отклика запроса. Его сокращение напрямую уменьшает общее время выполнения.
Доказательство части 2: Влияние на пропускную способность (throughput)
Утверждение: Минимизация времени ожидания приводит к увеличению количества выполненных запросов за единицу времени.
Доказательство:
Логическое рассуждение и аналогия: Представьте себе дорогу с единственной заправкой (единый ресурс — дисковая подсистема). Если одна машина (запрос) долго стоит на заправке (ждет I/O), она создает пробку. Машины сзади нее также вынуждены ждать. Если время заправки каждой машины сократить, пропускная способность заправки (диска) возрастет, и за час через пункт пропуска проедет больше машин (запросов).
Математическая модель (Теория массового обслуживания): Сервер БД можно смоделировать как систему массового обслуживания (СМО) с ограниченным числом каналов (работников — CPU ядер, дисковых контроллеров). Производительность системы (Throughput) — количество успешно обслуженных заявок (запросов) в единицу времени. Ключевой параметр, влияющий на производительность — Время обслуживания заявки, которое, как мы доказали в части 1, равно T_active + T_wait. Формулы для СМО (например, для многоканальной системы с ожиданием) показывают, что пропускная способность напрямую зависит от времени обслуживания одной заявки. Чем меньше время обслуживания, тем выше пропускная способность системы. Throughput ∝ 1 / T_total (Пропускная способность обратно пропорциональна времени выполнения запроса).
Формализация: Пусть N — количество идентичных запросов, которые необходимо выполнить. Общее время на выполнение всех N запросов в системе без параллелизма: T_system = N * T_total = N * (T_active + T_wait) Количество запросов, выполняемых в секунду (Throughput): R = N / T_system = 1 / (T_active + T_wait) Если T_wait уменьшается, знаменатель уменьшается, а значение R (throughput) — увеличивается. Следствие: За фиксированный промежуток времени T (например, 1 секунда), количество выполненных запросов будет равно R * T = T / (T_active + T_wait). Сокращение T_wait приводит к увеличению этого числа.
Практическое подтверждение (Сценарий с блокировками): Рассмотрим конкурентный доступ. Было: Запрос A устанавливает эксклюзивную блокировку на строку и выполняет долгую операцию (T_wait для других запросов велико из-за ожидания LCK_M_X). Десятки других запросов, желающих прочитать эту строку, выстраиваются в очередь и ждут. Стало: Запрос A оптимизирован и выполняется быстрее (сокращается его T_active и, что важно, время удержания блокировки). Он быстрее освобождает ресурс. Результат: Время ожидания T_wait для каждого из запросов в очереди резко сокращается. Общая система справляется с той же рабочей нагрузкой за меньшее время, либо успевает обработать больше запросов за то же время. Клиент получает больший объем полезной информации за тот же период.
Заключение по части 2:
Гипотеза верна. Сокращение времени ожидания не только ускоряет один запрос, но и уменьшает contention (борьбу за ресурсы) в системе. Это высвобождает ресурсы (CPU, диски, блокировки) для обработки других запросов, что приводит к увеличению общей пропускной способности (throughput) системы.
Итоговое заключение
Обе части гипотезы являются не просто предположениями, а фундаментальными принципами устройства высокопроизводительных систем. Они доказываются через:
Аддитивность времени выполнения запроса.
Обратную зависимость пропускной способности от времени выполнения отдельной задачи.
Эмпирические данные, получаемые через инструменты мониторинга ожиданий СУБД.
Принципы теории массового обслуживания.
Таким образом, основная задача оптимизации производительности БД часто сводится именно к выявлению и сокращению ключевых событий ожидания (wait events).
Глубокий сбор статистики по SQL-запросам. Для высоконагруженных систем "Орешник" обеспечивает детальный сбор статистики выполнения ( calls, rows) и ожиданий (wait_event_type, wait_event) для каждого отдельного запроса. Это даёт бесценную информацию для точечной оптимизации самых ресурсоёмких операций.
Реализация раздельной стратегии сбора статистических данных по SQL запросам
Процесс-1 - cбор исходных данных статистики SQL-запросов, одновременно со сбором данных по СУБД.Процесс-2 - агрегация и сглаживание накопленных данных по отдельным SQL-запросам.
Представлен комплекс pg_hazel "Орешник": революционные know-how для предиктивного анализа и обеспечения высокой доступности PostgreSQL
📅 Дата публикации: 17 сентября 2025 года
📍 Место: Россия
Разработчики проекта pg_hazel "Орешник" (https://dzen.ru/kznalp) представляют уникальный программный комплекс, предназначенный для глубинного мониторинга и анализа производительности высоконагруженных систем управления базами данных (СУБД) PostgreSQL. Решение включает в себя ряд эксклюзивных технологий (know-how), которые радикально меняют подход к обеспечению стабильности и предсказуемости работы критически важных баз данных.
В эпоху, когда простои и лаги в работе БД напрямую влияют на бизнес-показатели, традиционный мониторинг, отслеживающий лишь общие метрики, уже недостаточен. Комплекс "Орешник" предлагает проактивный и корреляционный анализ, выявляя проблемы на стадии их зарождения и точно определяя первопричину.
Ключевые решённые технологические задачи (know-how):
Интеллектуальное удаление выбросов в исходных данных. Алгоритмы "Орешника" автоматически фильтруют аномальные значения, возникающие из-за кратковременных скачков нагрузки или ошибок сбора. Это обеспечивает высокую достоверность исходных данных для последующего анализа и исключает ложные срабатывания.
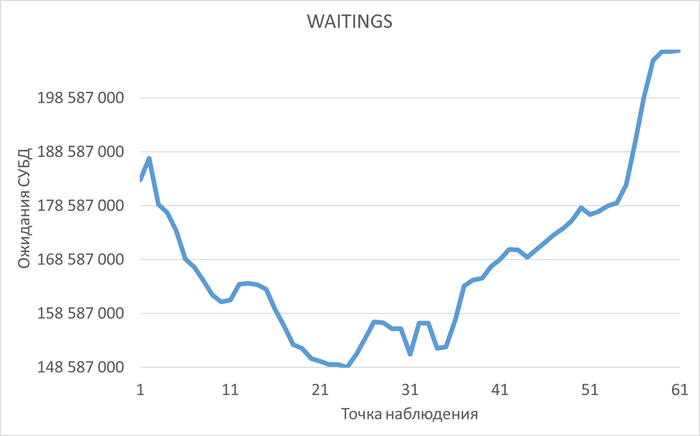
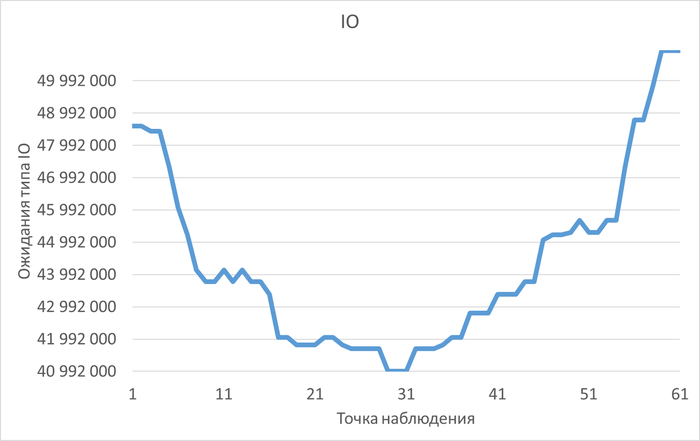
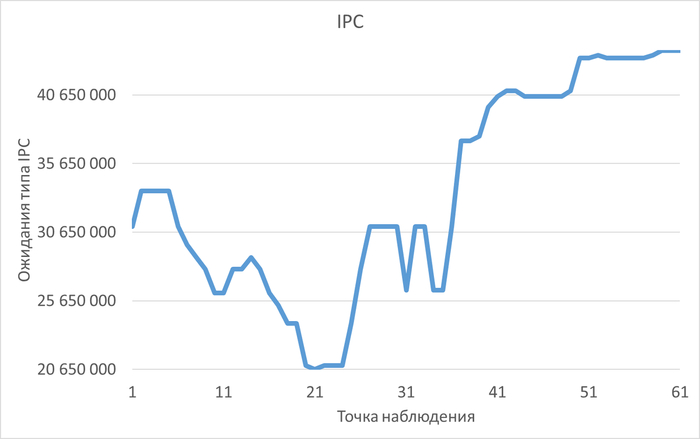
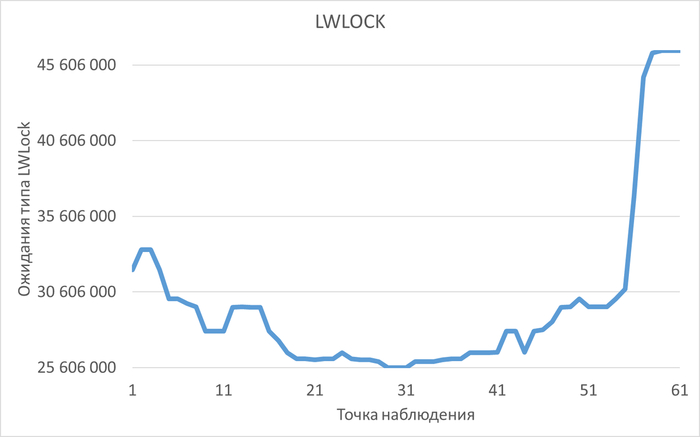
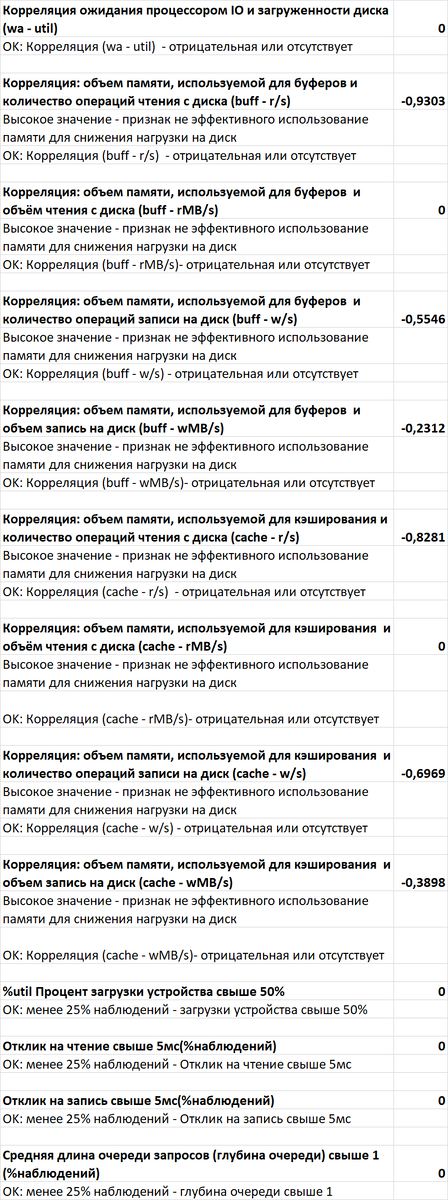
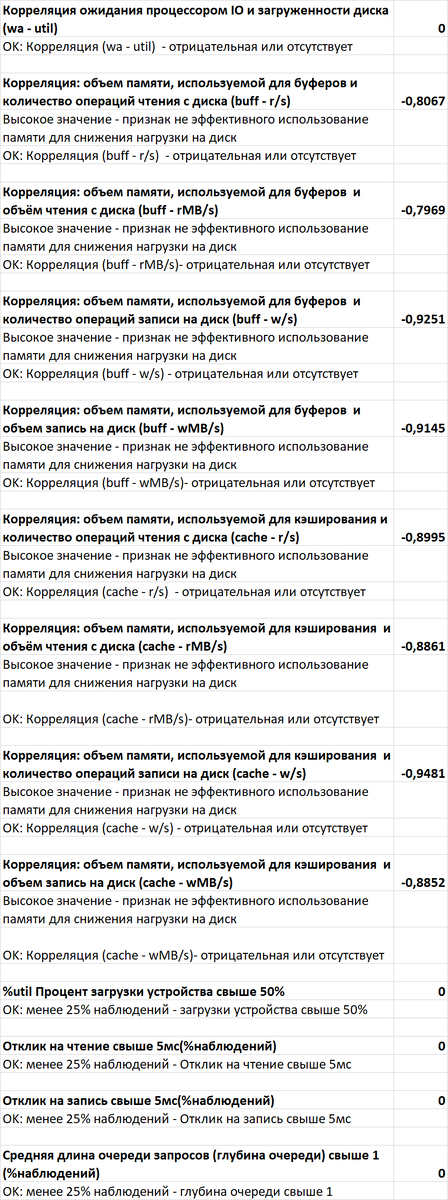
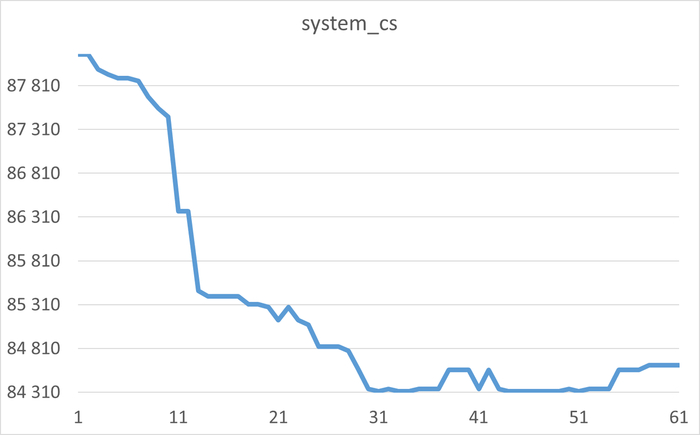
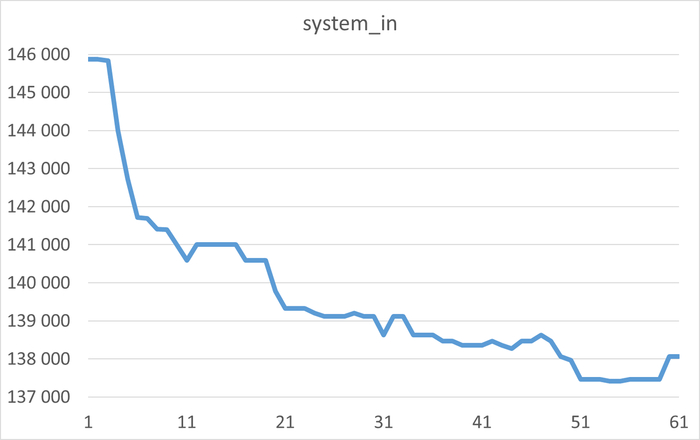
История изменения метрик производительности и ожиданий. Система сохраняет не только текущее состояние, но и полную историю всех ключевых метрик СУБД (LWLocks, IPC, IO и т.д.) . Это позволяет проводить ретроспективный анализ и точно определять, в какой момент и при каких условиях началась деградация производительности.
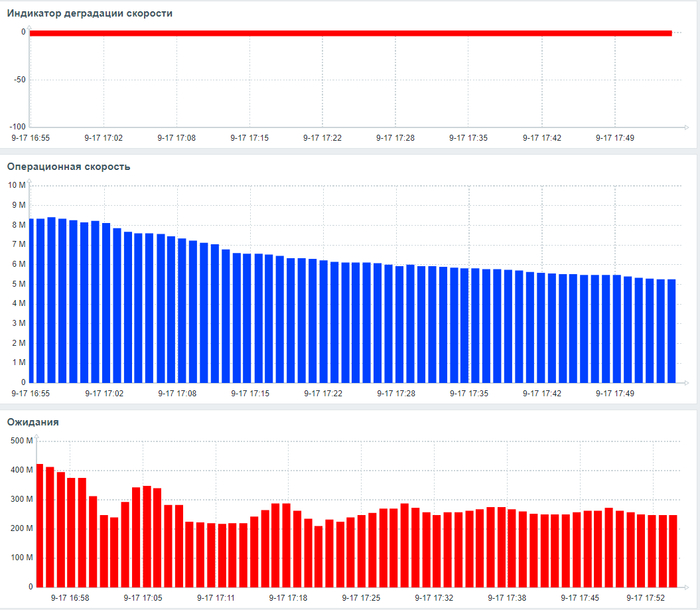
Индикатор снижения производительности как стартовое событие для инцидентов. Комплекс в реальном времени вычисляет репрезентативные показатели производительности СУБД. При их отклонении от нормы система автоматически может инициирует процесс создания инцидента в Service Desk, позволяя инженерам начать расследование до того, как проблема отразится на пользователях.
Глубокий сбор статистики по SQL-запросам. Для высоконагруженных систем "Орешник" обеспечивает детальный сбор статистики выполнения ( calls, rows) и ожиданий (wait_event_type, wait_event) для каждого отдельного запроса. Это даёт бесценную информацию для точечной оптимизации самых ресурсоёмких операций.
Статистический анализ метрик ОС (vmstat, iostat). Анализ не ограничивается данными СУБД. Система строит динамические статистические модели по метрикам операционной системы (загрузка CPU, очереди диска, потребление памяти), выявляя аномалии и тренды на уровне всего сервера.
Корреляционный анализ ожиданий СУБД и метрик ОС. Это ключевое ноу-хау комплекса. "Орешник" автоматически находит корреляции между событиями ожидания внутри PostgreSQL (например, ожидание записи на диск) и показателями ОС (например, высокая очередь записи на iostat). Это в разы ускоряет диагностику, позволяя однозначно ответить на вопрос: "Проблема в неоптимальном запросе или в медленном диске?".
Цитата руководителя проекта: «Наш опыт эксплуатации кластеров PostgreSQL под экстремальными нагрузками показал, что стандартные инструменты мониторинга часто показывают лишь следствие, а не причину проблемы. Мы создали "Орешник" как систему, которая мыслит как опытный администратор БД. Она не просто фиксирует факт падения производительности, а предупреждает о нём заранее и сразу выдаёт гипотезу о корневой причине, экономя часы и дни на расследование. Наши know-how в области корреляционного анализа — это настоящий прорыв в предиктивной аналитике для СУБД».
О проекте pg_hazel "Орешник": Проект посвящён разработке и внедрению передовых методов мониторинга, анализа и обеспечения отказоустойчивости кластеров PostgreSQL. Решения проекта основаны на глубоком практическом опыте и предназначены для использования в высокодоступных и высоконагруженных системах, где стабильность работы БД является критически важной для бизнеса.