Использование PG_EXPECTO для выявления проблемных SQL запросов при анализе инцидента производительности СУБД PostgreSQL
Взято с основного технического канала Postgres DBA (возможны правки в исходной статье).

«База данных «тормозит». В логах — сотни выполняемых запросов. Где та самая иголка в стоге сена, что заставляет СУБД стонать под нагрузкой? PG_EXPECTO — это магнит, который её находит.»
Расследование инцидентов производительности в PostgreSQL часто напоминает поиск иголки в стоге сена. Десятки тысяч запросов , и определить, какой именно из них стал «слабым звеном» системы, без специальных инструментов — крайне сложная задача.
В этой статье рассмотрим, как использование PG_EXPECTO позволяет кардинально ускорить этот процесс. Мы не будем гадать на основе снимков pg_stat_statements. Вместо этого мы научимся проактивно создавать «ловушки» на проблемные паттерны производительности. Когда инцидент происходит, PG_EXPECTO позволяет быстро найти проблемные SQL-запросы , предоставляя инженеру готовый список «подозреваемых» для дальнейшей оптимизации.
Новый инструмент с открытым исходным кодом для статистического анализа, нагрузочного тестирования и построения отчетов доступен в репозитории GitFlic и GitHub
Задача
Практическое применение представленных ранее методик использования pg_expecto :
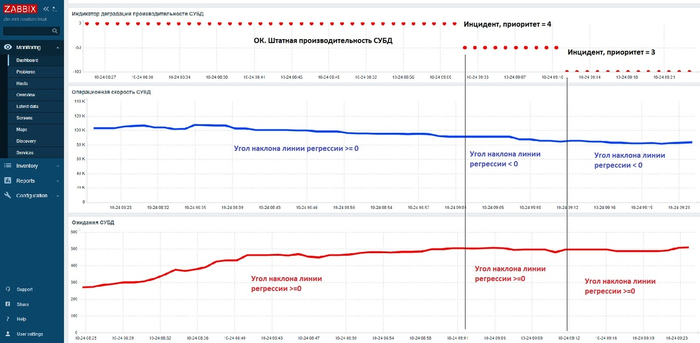
Инцидент производительности СУБД в мониторинге Zabbix
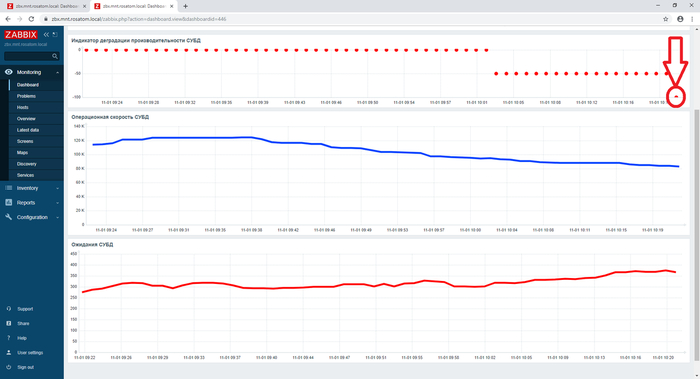
Дашборд Zabbix
Шаг 1 - сформировать сводный отчет по метрика оценки производительности СУБД и инфраструктуры
cd /postgres/pg_expecto/sh/performance_reports/summary_report.sh '2025-11-01 10:22'
Шаг 2 - импортировать текстовые файлы в таблицы Excel
Действия аналогичны описанным ранее:
Раздел : Импортирование данных отчетов в Excel
Шаг 3 - Выявление аномалий инфраструктуры
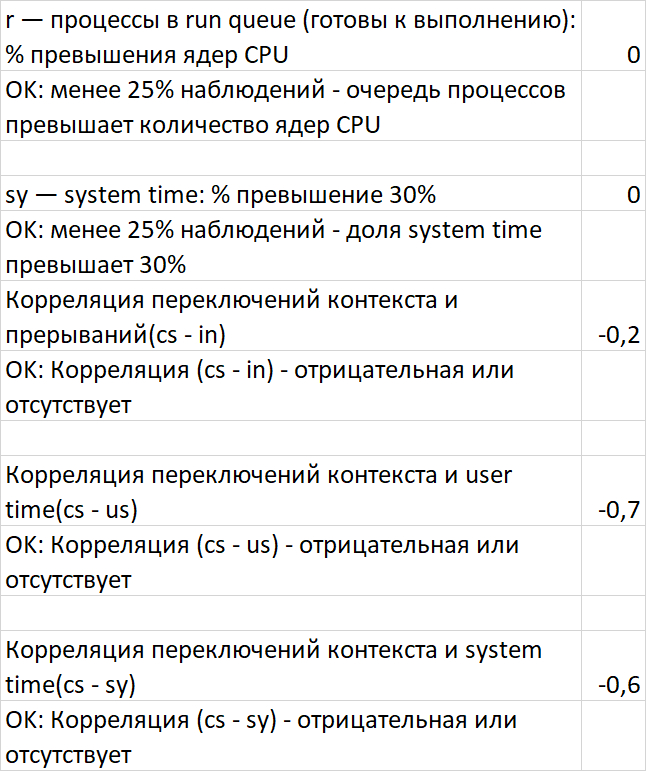
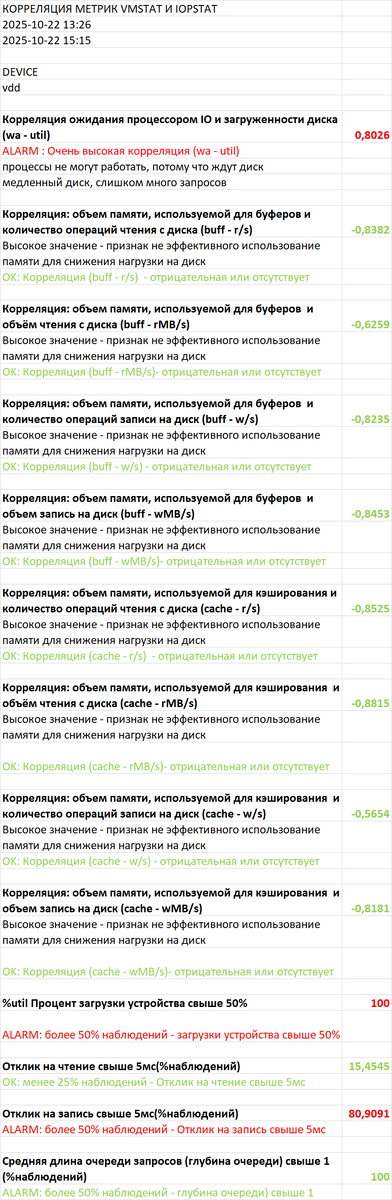
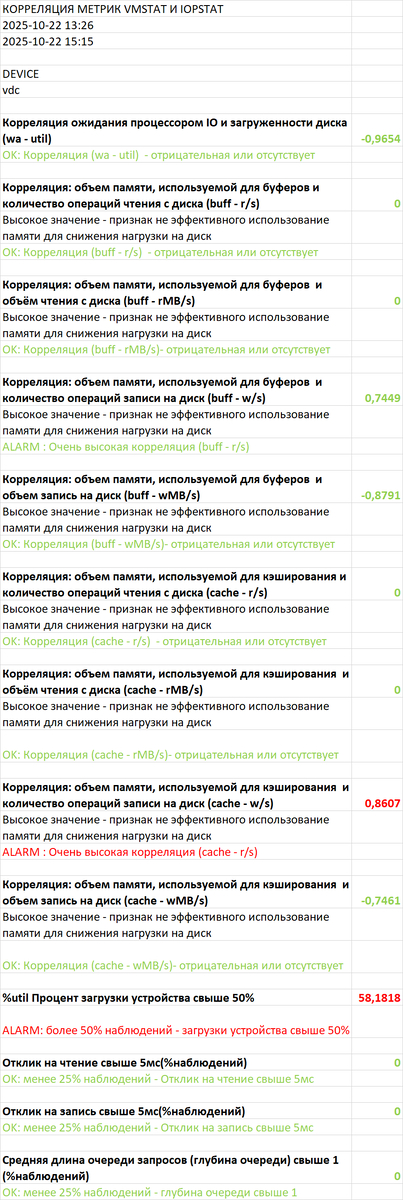
1.Корреляция "Ожидания СУБД - vmstat"
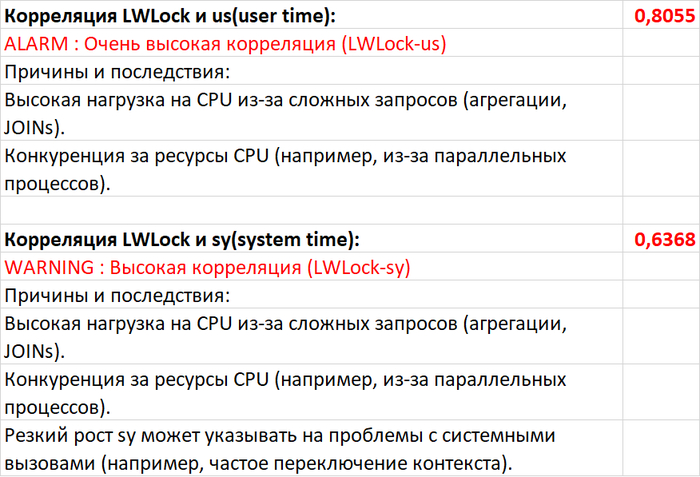
Результат отчета:
SQL запросы создают нагрузку на инфраструктуру
2. Статистика vmstat+iostat по файловой подсистеме /data

Результат отчета:
Имеются проблемы производительности на запись для дискового устройства используемого для файловой системы /data
3. Статистика vmstat+iostat по файловой подсистеме /wal
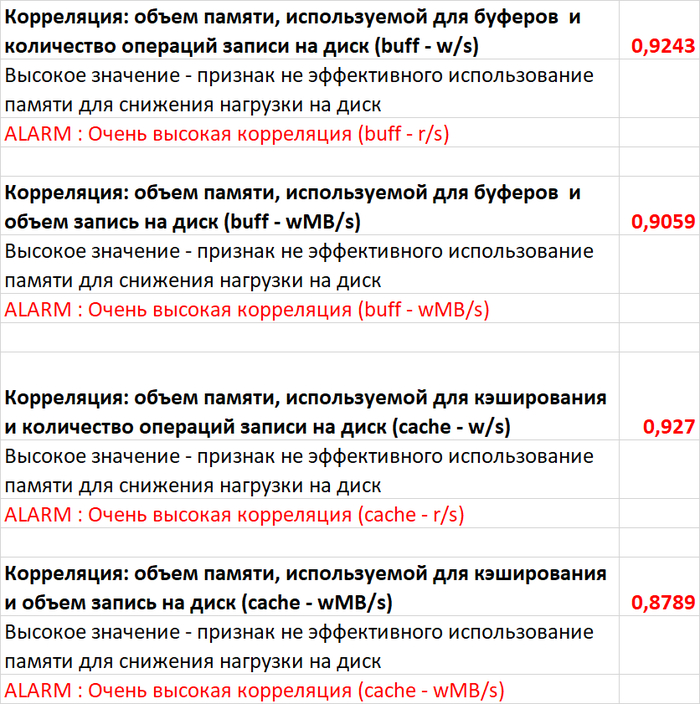
Результат отчета:
Существенных аномалий нет, но возможно, имеются перспективы для оптимизации.
4. Чек-лист IO
Результат отчета:
Аномалий - не обнаружено.
5. Чек-лист CPU
Результат отчета:
Аномалий - не обнаружено.
6. Чек-лист RAM
Результат отчета:
Аномалий - не обнаружено.
7. Результат анализа инфраструктуры
Аномалии инфраструктуры, оказывающая влияние на производительность СУБД:
Превышение времени отклика на запись для дискового устройства используемого для файловой системы /data
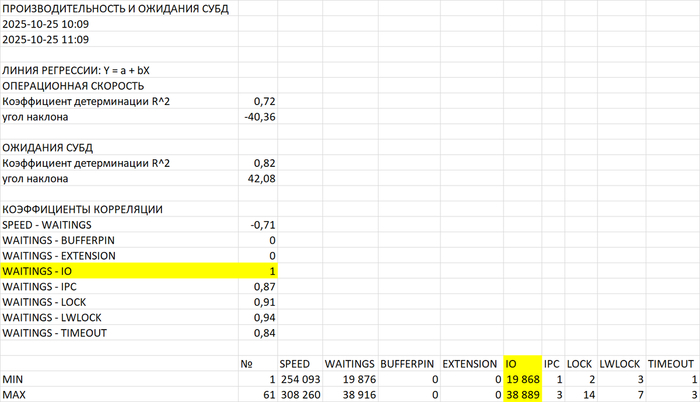
Шаг 4 - корреляционный анализ производительности СУБД
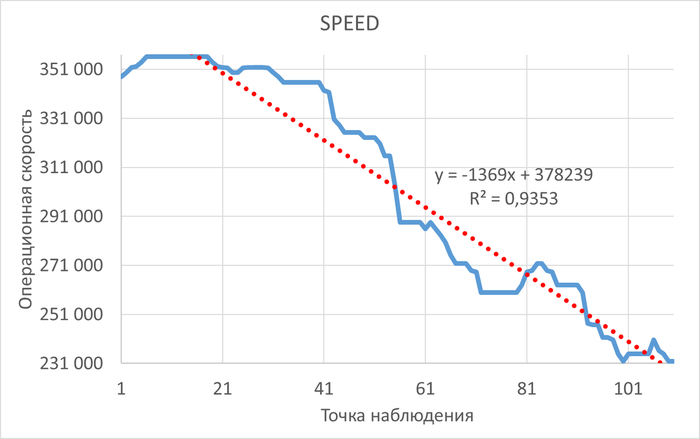
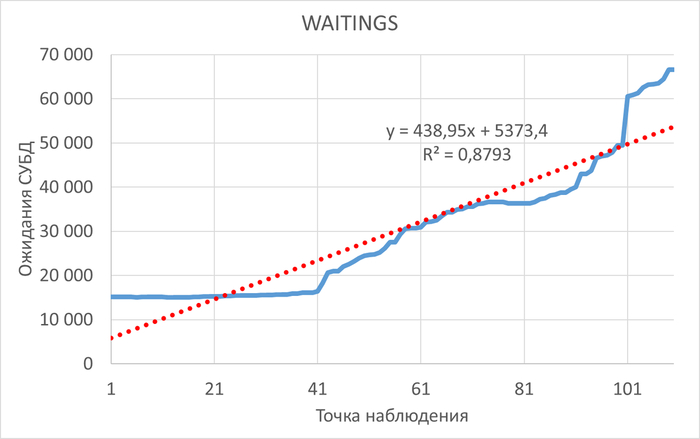
Операционная скорость и ожидания СУБД в период, предшествующий инциденту
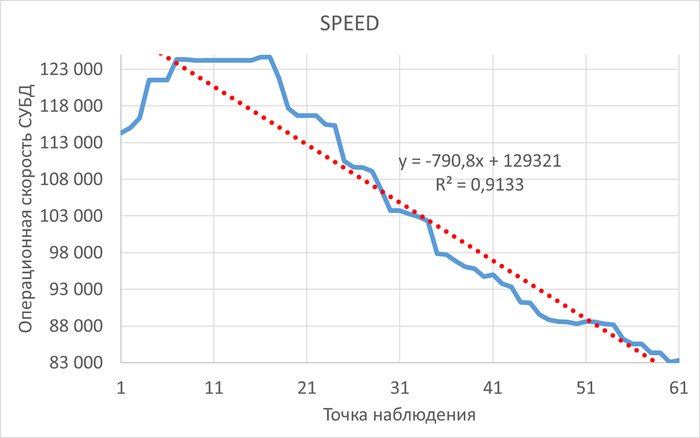
График операционной скорости СУБД. Красная линия - линия регрессии.
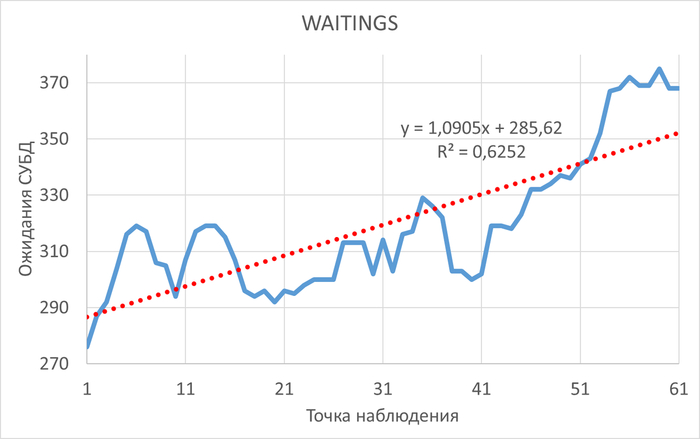
График ожидания СУБД. Красная линия - линия регрессии.
Корреляционный анализ ожиданий СУБД
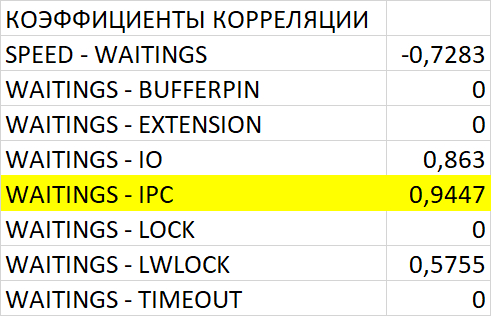
Тип ожидания, имеющий наибольший коэффициент корреляции с ожиданиями СУБД - IPC
IPC: Серверный процесс ожидает взаимодействия с другим процессом. В wait_event обозначается конкретное место ожидания;
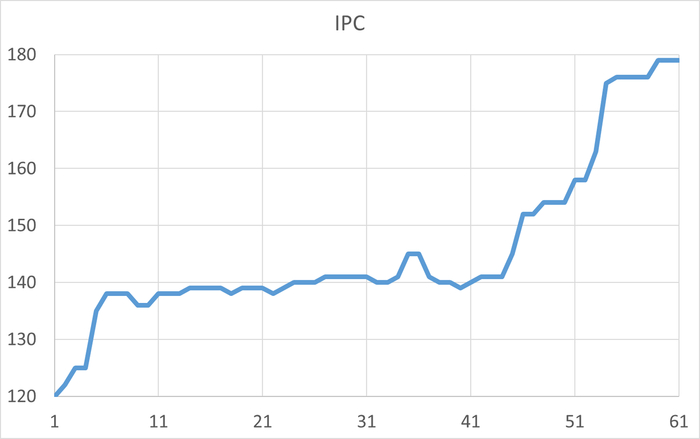
График ожиданий типа IPC
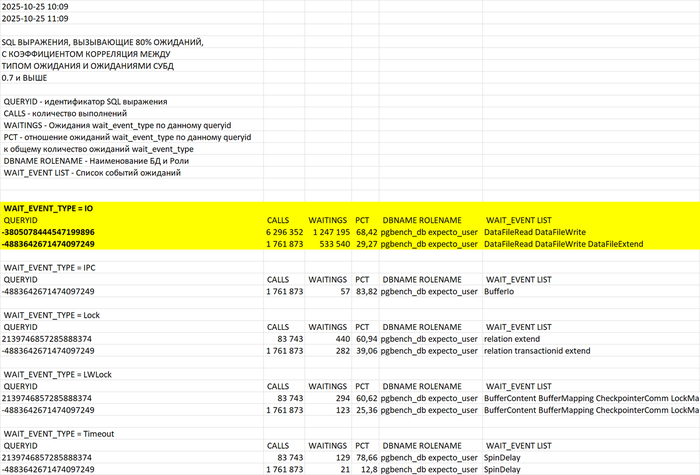
Диаграмма Парето по событиям ожидания СУБД - для типа ожидания IPC
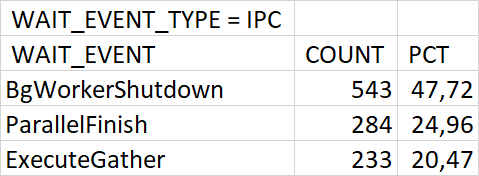
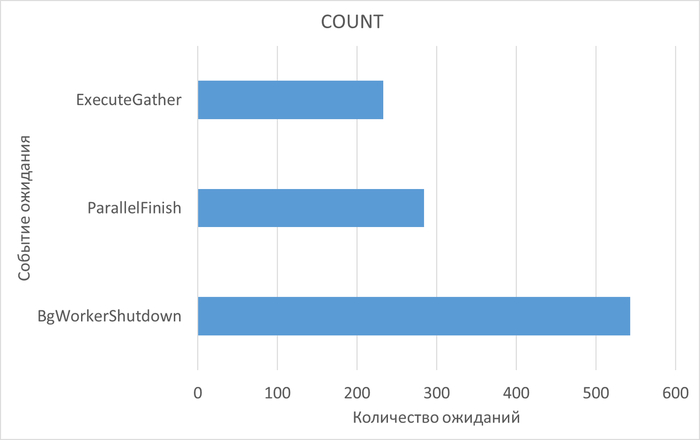
Гипотеза(спойлер)
Можно сразу предположить , что причина - отсутствие индексов.
Диаграмма Парето по ожиданиям SQL запросов для типа ожидания IPC
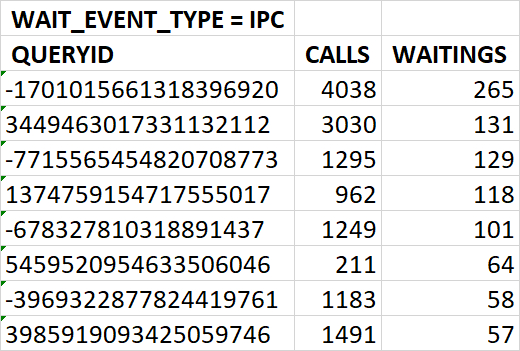
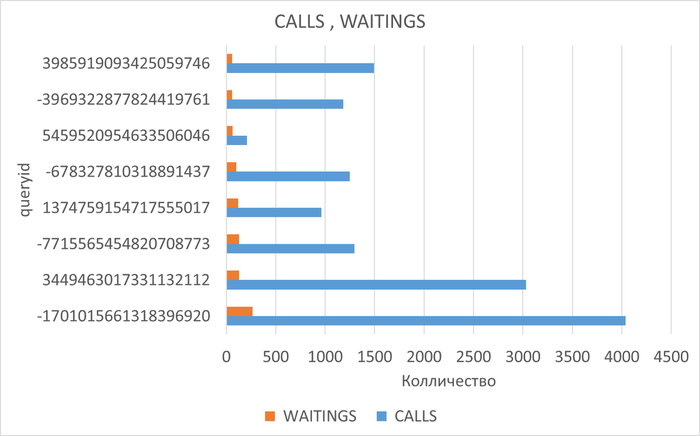
Шаг 5 - формирование списка проблемных SQL запросов для последующей оптимизации
Список queryid SQL-запросов для оптимизации:
-1701015661318396920
3449463017331132112
-7715565454820708773
1374759154717555017
-678327810318891437
5459520954633506046
-3969322877824419761
3985919093425059746
Шаг 6 - получение рекомендации нейросети по снижению ожиданий типа IPC
Запрос нейросети
Файл сформированный отчетом : net.1.wait_event.prompt.txt
Выдели общие части из текста и найти смысловые совпадения. Сформируй краткий итог по необходимым мероприятиям в виде сводной таблицы.
Входной файл для нейросети сформированный отчетом : net.1.wait_event.IPC.txt
Результат работы нейросети DeepSeek


Шаг 7 - анализ проблемных SQL запросов нейросетью
Запрос нейросети
Файл сформированный отчетом : net.2.sql.prompt.txt
Выдели ключевые паттерны SQL запросов , с уточнением - сколько раз встречается паттерн. Сформируй итоговую таблицу - какие паттерны используются для каждого queryid. Выдели ключевые особенности SQL запроса, использующего наибольшее количество паттернов.
Входной файл для нейросети сформированный отчетом : net.2.sql.IPC.txt
Результат работы нейросети DeepSeek



Шаг 8 - Примерный план получения рекомендаций нейросети по оптимизации проблемного запроса queryid = 1374759154717555017
Проблемный запрос для оптимизации
Текст запроса
SELECT
"Table-1"."col1",
"Table-1"."col2",
"Table-2"."col1" AS "Table-2.col1",
"Table-2"."col3" AS "Table-2.col4",
"Table-2"."col6" AS "Table-2.col5",
"Table-3"."col1" AS "Table-3.col1",
"Table-3"."col6" AS "Table-3.col5",
"Table-3"."col7" AS "Table-3.col7",
"Table-3"."col8" AS "Table-3.col8"
FROM "public"."Table-1" AS "Table-1"
INNER JOIN "public"."Table-4" AS "Table-2" ON "Table-1"."col1" = "Table-2"."col6"
INNER JOIN "public"."Table-1_Table-3" AS "Table-3" ON "Table-1"."col1" = "Table-3"."col6" AND "Table-3"."col7" = 'ipr_training_id' AND "Table-3"."col8" = 'XXX'
Таблицы участвующие в запросе
Table "public.Table-1"
Column | Col2 | Collation | Nullable | Default
--------+---------------+----------+---------+---------------------
col1 | col1 | | not null | col1_generate_v1mc()
col2 | enum_task_col2 | | not null |
Indexes:
"Table-1_pcol7" PRIMARY COL7, btree (col1)
Referenced by:
TABLE "Table-4" CONSTRAINT "Table-4_col6_fcol7" FOREIGN COL7 (col6) REFERENCES Table-1(col1)
TABLE "Table-1_Table-3" CONSTRAINT "Table-1_Table-3_col6_fcol7" FOREIGN COL7 (col6) REFERENCES Table-1(col1)
TABLE "Table-1_meta" CONSTRAINT "Table-1_meta_col6_fcol7" FOREIGN COL7 (col6) REFERENCES Table-1(col1)
TABLE "templates_Table-1" CONSTRAINT "templates_Table-1_col6_fcol7" FOREIGN COL7 (col6) REFERENCES Table-1(col1)
Table "public.Table-4"
Column | Col2 | Collation | Nullable | Default
-----------+-----+----------+---------+---------------------
col1 | col1 | | not null | col1_generate_v1mc()
col3 | col1 | | not null |
col6 | col1 | | not null |
Indexes:
"Table-4_pcol7" PRIMARY COL7, btree (col1)
"Table-4_col3_col6_col7" UNIQUE CONSTRAINT, btree (col3, col6)
Foreign-col7 constraints:
"Table-4_col3_fcol7" FOREIGN COL7 (col3) REFERENCES plans(col1)
"Table-4_col6_fcol7" FOREIGN COL7 (col6) REFERENCES Table-1(col1)
Referenced by:
TABLE "Table-1_statuses" CONSTRAINT "Table-1_statuses_plan_col6_fcol7" FOREIGN COL7 (plan_col6) REFERENCES Table-4(col1)
Table "public.Table-1_Table-3"
Column | Col2 | Collation | Nullable | Default
-----------+------------------------+----------+---------+---------------------
col1 | col1 | | not null | col1_generate_v1mc()
col6 | col1 | | not null |
col7 | enum_task_attribute_col7 | | not null |
col8 | text | | not null |
Indexes:
"Table-1_Table-3_pcol7" PRIMARY COL7, btree (col1)
"col6_col7" UNIQUE CONSTRAINT, btree (col6, col7)
Foreign-col7 constraints:
"Table-1_Table-3_col6_fcol7" FOREIGN COL7 (col6) REFERENCES Table-1(col1)
План выполнения запроса
EXPLAIN ( ANALYZE , VERBOSE , COSTS , BUFFERS , TIMING , SUMMARY )
SELECT "Table-1"."col1", "Table-1"."col2", "Table-2"."col1" AS "Table-2.col1", "Table-2"."col3" AS "Table-2.col4", "Table-2"."col6" AS "Table-2.col5", "Table-3"."col1" AS "Table-3.col1", "Table-3"."col6" AS "Table-3.col5", "Table-3"."col7" AS "Table-3.col7", "Table-3"."col8" AS "Table-3.col8"
FROM "public"."Table-1" AS "Table-1"
INNER JOIN "public"."Table-4" AS "Table-2" ON "Table-1"."col1" = "Table-2"."col6"
INNER JOIN "public"."Table-1_Table-3" AS "Table-3" ON "Table-1"."col1" = "Table-3"."col6" AND "Table-3"."col7" = 'ipr_training_id' AND "Table-3"."col8" = 'XXX';
QUERY PLAN
-------------------------------------------------------------------------
Gather (cost=51291.67..61070.22 rows=11 width=138) (actual time=212.782..228.904 rows=0 loops=1)
Output: "Table-1".col1, "Table-1".col2, "Table-2".col1, "Table-2".col3, "Table-2".col6, Table-3.col1, Table-3.col6, Table-3.col7, Table-3.col8
Workers Planned: 2
Workers Launched: 2
Buffers: shared hit=38808
-> Nested Loop (cost=50291.67..60069.12 rows=5 width=138) (actual time=198.025..198.030 rows=0 loops=3)
Output: "Table-1".col1, "Table-1".col2, "Table-2".col1, "Table-2".col3, "Table-2".col6, Table-3.col1, Table-3.col6, Table-3.col7, Table-3.col8
Inner Unique: true
Buffers: shared hit=38808
Worker 0: actual time=191.589..191.593 rows=0 loops=1
Buffers: shared hit=12830
Worker 1: actual time=191.283..191.288 rows=0 loops=1
Buffers: shared hit=10816
-> Parallel Hash Join (cost=50291.24..60066.84 rows=5 width=118) (actual time=198.023..198.027 rows=0 loops=3)
Output: "Table-2".col1, "Table-2".col3, "Table-2".col6, Table-3.col1, Table-3.col6, Table-3.col7, Table-3.col8
Inner Unique: true
Hash Cond: ("Table-2".col6 = Table-3.col6)
Buffers: shared hit=38808
Worker 0: actual time=191.587..191.590 rows=0 loops=1
Buffers: shared hit=12830
Worker 1: actual time=191.281..191.285 rows=0 loops=1
Buffers: shared hit=10816
-> Parallel Seq Scan on public.Table-4 "Table-2" (cost=0.00..9045.05 rows=278305 width=48) (never executed)
Output: "Table-2".col1, "Table-2".col3, "Table-2".col6
-> Parallel Hash (cost=50291.20..50291.20 rows=3 width=70) (actual time=197.528..197.529 rows=0 loops=3)
Output: Table-3.col1, Table-3.col6, Table-3.col7, Table-3.col8
Buckets: 1024 Batches: 1 Memory Usage: 0kB
Buffers: shared hit=38728
Worker 0: actual time=191.259..191.260 rows=0 loops=1
Buffers: shared hit=12790
Worker 1: actual time=190.969..190.970 rows=0 loops=1
Buffers: shared hit=10776
-> Parallel Seq Scan on public.Table-1_Table-3 Table-3 (cost=0.00..50291.20 rows=3 width=70) (actual time=194.885..194.885 rows=0 loops=3)
Output: Table-3.col1, Table-3.col6, Table-3.col7, Table-3.col8
Filter: ((Table-3.col7 = 'ipr_training_id'::enum_task_attribute_col7) AND (Table-3.col8 = 'XXX'::text))
Rows Removed by Filter: 1027564
Buffers: shared hit=38728
Worker 0: actual time=187.238..187.239 rows=0 loops=1
Buffers: shared hit=12790
Worker 1: actual time=187.176..187.176 rows=0 loops=1
Buffers: shared hit=10776
-> Index Scan using Table-1_pcol7 on public.Table-1 "Table-1" (cost=0.42..0.46 rows=1 width=20) (never executed)
Output: "Table-1".col1, "Table-1".col2
Index Cond: ("Table-1".col1 = "Table-2".col6)
Query Identifier: 1374759154717555017
Planning:
Buffers: shared hit=217
Planning Time: 2.928 ms
Execution Time: 228.955 ms
(49 rows)
Запрос нейросети
Как можно оптимизировать SQL запрос, используя прилагаемые таблицы участвующие в запросе и план выполнения запроса
Результат работы нейросети DeepSeek