


Инструкция по сборке домашней оффлайн нейросети (экспертной системы) с возможностью обучения

Итак, вы прочитали мой пост: Глаза боятся, а руки из.. плеч :) и поняли - "я тоже такое хочу". И тут я с вами совершенно согласен :) Приступим!
Часть 1. Системные требования и подготовка к сборке.
Системные требования:
ОС: Windows 10/11 (x64)
Python: 3.12.0 (точный номер версии!)
Видеокарта: NVIDIA с драйвером ≥ 535 и CUDA Toolkit 12.6
RAM: ≥ 8 ГБ
VRAM: ≥ 6 ГБ (для загрузки 32 слоёв на GPU)
Важно:
если у вас не видеокарта Nvidia, то смысла читать дальше нет! На других видеокартах эта программа работать не будет!
программы нужно ставить точно такой же версии (!), как я указал. Разработчики часто меняют список поддерживаемых команд от версии к версии, у меня указаны версии, которые подобраны методом перебора на максимальную совместимость!
для скачивания некоторых программ понадобится VPN. В связи с наложенными санкциями, многие разработчики ограничили доступ к своим ресурсам. Думаю, при желании, вы решите этот вопрос.
данная программа тестировалась и работает на Windows 10 (64-bit), работать должна и на Windows 11 (64-bit). Остальные версии не проверял!
Список необходимых программ для работы:
Скачайте и установите Python 3.12.0 (64-bit) (на 32-bit не тестировалось, потому что я счастливый владелец системы 64-bit)
ОБЯЗАТЕЛЬНО поставьте галочку "Add Python to PATH" во время установки!
Скачайте и установите CUDA Toolkit 12.6
Галочка "Add to PATH" обычно по умолчанию включена, но необходимо в этом убедиться и поставить, если нужно.
Скачайте и установите Visual Studio 2022 Build Tools (с C++ и CMake)
При установке Visual Studio 2022 выберите в меню "Разработка классических программ на C++" и справа в окошечке обязательно проставьте галочки напротив:
C++ CMake tools for Windows
C++ MSVC 143 (Visual Studio 2022)
Windows 10/11 SDK (в зависимости от вашей установленной системы)
Скачайте и установите Cmake 4.2.0 for Windows-x86-64
После того, как всё скачали и установили, открываем CMD (Command Prompt) и проверяем установленные версии необходимых компонентов (копируем команду и вставляем её, жмём Enter для выполнения).
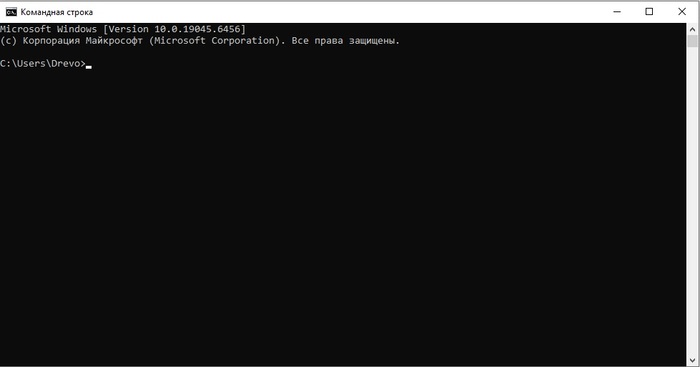
1. Python 3.12.0 (64-bit)
python --version
Должно быть: Python 3.12.0
python -c "import platform; print(platform.architecture())"
Должно быть: ('64bit', 'WindowsPE')
2. CUDA Toolkit 12.6
nvcc --version
→ В выводе ищите строку вроде: release 12.6, V12.6.85
3. CMake 4.2.0
cmake --version
Должно быть: cmake version 4.2.0
4. Дополнительно: проверка GPU и драйвера
nvidia-smi
Покажет версию драйвера и список GPU. Важно! Драйвер должен быть ≥ 535.xx для корректной работы CUDA 12.6. Если у вас версия ниже требуемой, обновите драйвера видеокарты.
Если после всех проверок у вас всё так же, как и у меня - база для сборки готова.
Часть 2. Формируем структуру программы.
Создаём папку на диске С:\ с названием car_expert и формируем внутри следующую структуру файлов и папок:
Папка knowledge_base
Папка models
Файл app.py
Файл requirements.txt
Папки создать несложно, файлы делаем с помощью Блокнота (просто создаём пустой файл с названием, как у меня) и сохраняем в нашу папку car_expert. Базовая структура готова, остальное добавим в процессе работы.
Часть 3. Скачиваем необходимые установочные пакеты и языковую модель.
Открываем в режиме редактирования файл requirements.txt в Блокноте. Копируем в него и сохраняем следующий текст в кодировке UTF-8 (обычно стоит по умолчанию):
aiofiles==23.2.1
annotated-doc==0.0.4
annotated-types==0.7.0
anyio==4.12.0
certifi==2025.11.12
charset-normalizer==3.4.4
click==8.3.1
colorama==0.4.6
contourpy==1.3.3
cycler==0.12.1
diskcache==5.6.3
fastapi==0.124.0
ffmpy==1.0.0
filelock==3.20.0
fonttools==4.61.0
fsspec==2025.12.0
gradio==4.44.1
gradio_client==1.3.0
h11==0.16.0
hf-xet==1.2.0
httpcore==1.0.9
httpx==0.28.1
huggingface-hub==0.26.5
idna==3.11
importlib_resources==6.5.2
Jinja2==3.1.6
kiwisolver==1.4.9
llama_cpp_python==0.3.16
markdown-it-py==4.0.0
MarkupSafe==2.1.5
matplotlib==3.10.7
mdurl==0.1.2
numpy==1.26.4
orjson==3.11.5
packaging==25.0
pandas==2.3.3
pillow==10.4.0
pydantic==2.12.5
pydantic_core==2.41.5
pydub==0.25.1
Pygments==2.19.2
pyparsing==3.2.5
python-dateutil==2.9.0.post0
python-multipart==0.0.20
pytz==2025.2
PyYAML==6.0.3
requests==2.32.5
rich==14.2.0
ruff==0.14.8
semantic-version==2.10.0
shellingham==1.5.4
six==1.17.0
starlette==0.50.0
tomlkit==0.12.0
tqdm==4.67.1
typer==0.20.0
typer-slim==0.20.0
typing-inspection==0.4.2
typing_extensions==4.15.0
tzdata==2025.2
urllib3==2.6.1
uvicorn==0.38.0
websockets==12.0
Это список всех пакетов, которые нужны для корректной работы нашей программы. Обратите внимание на символы == в каждом пакете, это означает "найти и скачать именно этот номер версии". Это важно! Другие версии этих пакетов будут конфликтовать между собой, потому что список внутренних команд может отличаться от версии к версии. Данный список - стабильная сборка, которая прекрасно взаимодействует между собой.
После того, как мы скопировали этот список в файл requirements.txt, открываем консоль CMD и вводим следующие команды по очереди:
cd C:\car_expert
python -m venv venv_gpu_fresh
venv_gpu_fresh\Scripts\activate
pip install -r requirements.txt
Смысл команд:
cd C:\car_expert
Переходим к папке C:\car_expert
python -m venv venv_gpu_fresh
Создаём виртуальное окружение и папку venv_gpu_fresh в корневой папке car_expert.
venv_gpu_fresh\Scripts\activate
Активируем локальную версию Python для нашей папки venv_gpu_fresh.
pip install -r requirements.txt
Начинаем установку пакетов из файла requirements.txt
Зачем мы создаём виртуальное окружение? Для того, что бы Python, установленный в нашей системе работал только с теми пакетами, которые нужны для нашей программы. И что бы любые другие пакеты, которые могут установиться в процессе его работы (например, точно такие же, как в нашем файле requirements.txt, но другой версии) никак не влияли на дальнейшую работоспособность нашей программы. Т.е. наша программа всегда будет запускаться в "виртуальной капсуле", на которую больше ничего не будет влиять "извне". Это гарантирует стабильность работы при любых условиях.
Установка пакетов из файла requirements.txt может занять некоторое время, во время этого процесса нельзя закрывать окно консоли CMD.
После того, как процесс установки закончится, скачиваем языковую модель phi-3-mini-4k-instruct.Q4_K_M.gguf. Это "мозг" нашей программы и именно эта модель будет "думать" и находить ответы на ваши вопросы. После скачивания помещаем её в папку models/.
Часть 4. Компилируем (собираем) платформу для работы с языковыми моделями llama-cpp-python.
Это важный этап нашей работы, именно платформа определяет каким способом будет происходить "мыслительный процесс" нашей языковой модели phi-3 : будет она думать медленно CPU (процессором) или быстро GPU (видеокартой). Самое печальное во всём этом, что официальных предсобранных .whl с CUDA для llama-cpp-python на Windows больше не публикуются ни на pypi.nvidia.com, ни в надёжных GitHub-репозиториях. Т.е. просто скачать и установить, как обычный пакет, уже не выйдет. Где-то её нет, а где-то стоят пароли на скачивание (жадины говядины). Но всегда есть возможность локальной сборки. Именно ей мы и займёмся.
Закрываем окно CMD, если оно было у вас до этого открытым, и запускаем заново (делаем сброс сессии).
Опять переходим в активированное виртуальное окружение, по очереди вводя команды:
cd C:\car_expert
venv_gpu_fresh\Scripts\activate
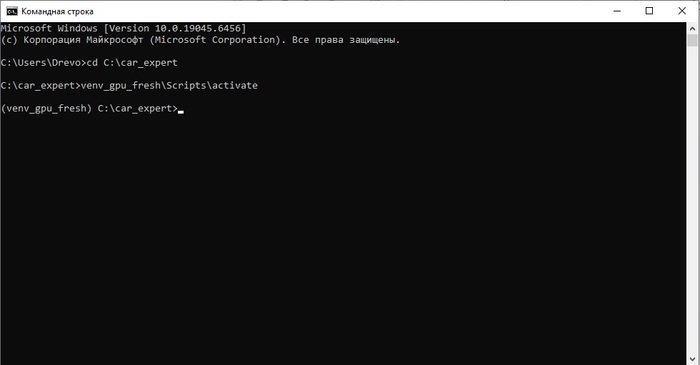
Признаком того, что вы вошли внутрь "виртуального окружения" и работаете в "капсуле", является надпись в скобочках (venv_gpu_fresh) перед C:\car_expert>. Если у вас всё так же как и у меня, продолжаем водить команды:
pip uninstall llama-cpp-python -y
set CMAKE_ARGS=-DLLAMA_CUBLAS=ON
set FORCE_CMAKE=1
pip install llama-cpp-python --no-cache-dir --verbose
Смысл команд:
ip uninstall llama-cpp-python -y
Удаляем предыдущую версию llama-cpp-python, у нас её пока вообще нет, но на всякий случай делаем очистку, что бы не было проблем.
set CMAKE_ARGS=-DLLAMA_CUBLAS=ON
Задаём переменную окружения CMAKE_ARGS в Windows CMD, чтобы передать параметр сборки в CMake при установке пакета llama-cpp-python. Без этого флага llama-cpp-python собирается только для CPU. С этим флагом — включается поддержка GPU (CUDA), и модель сможет использовать видеокарту NVIDIA.
set FORCE_CMAKE=1
в контексте установки пакета llama-cpp-python означает: «Принудительно запустить сборку через CMake, даже если pip или scikit-build-core считают, что это не нужно» Мы хотим собрать из исходников с поддержкой CUDA (работа именно на видеокарте), но pip может попытаться установить CPU-версию. Поэтому, "действуй строго по инструкции" :)
pip install llama-cpp-python --no-cache-dir --verbose
Эта команда гарантирует чистую установку: всё будет скачано и собрано заново. Показывает все этапы: загрузку, конфигурацию CMake, компиляцию, ошибки. Без этого флага pip может "молчать" при ошибках сборки или показывать только общее сообщение.
Важно! Процесс сборки займёт 10–25 минут — не прерывайте (не закрывайте окно CMD)!
Если в процессе сборки в окне консоли CMD не появились ошибки, то самую важную и трудоёмкую часть работы мы уже сделали. Если вы дошли до этого этапа и у вас всё получилось, я горжусь вами, вы молодцы! :)
Часть 5. Пишем код программы, которая заставит работать всё что мы сделали.
Открываем в Блокноте файл app.py, копируем этот код и сохраняем:
# app.py — авто-экспертная система БЕЗ векторной БД (только LLM + контекст в промпте)
import os
import glob
from llama_cpp import Llama
import gradio as gr
# === Конфигурация ===
KNOWLEDGE_DIR = "knowledge_base"
MODEL_PATH = "models/phi-3-mini-4k-instruct.Q4_K_M.gguf"
MAX_CONTEXT_LENGTH = 2000 # ограничение на длину контекста (токенов)
# === Загрузка всей базы знаний в строку ===
def load_knowledge_base() -> str:
files = glob.glob(os.path.join(KNOWLEDGE_DIR, "*.txt"))
if not files:
return "Нет доступных инструкций по ремонту."
all_text = []
for file_path in sorted(files):
try:
with open(file_path, "r", encoding="utf-8") as f:
content = f.read().strip()
if content:
header = f"\n\n=== {os.path.basename(file_path).replace('.txt', '').title()} ===\n"
all_text.append(header + content)
except Exception as e:
all_text.append(f"\n\n[Ошибка при загрузке {file_path}: {e}]")
full_context = "".join(all_text)
# Ограничиваем длину, чтобы не превысить контекст модели
if len(full_context) > MAX_CONTEXT_LENGTH:
full_context = full_context[:MAX_CONTEXT_LENGTH] + "\n... (контекст усечён)"
return full_context.strip()
# === Загрузка модели ===
def load_model():
return Llama(
model_path=MODEL_PATH,
n_ctx=4096,
n_threads=os.cpu_count(),
n_gpu_layers=999,
verbose=True # ← ВАЖНО: включите!
)
# === Ответ от модели с контекстом ===
def get_answer(query: str, knowledge: str) -> str:
prompt = f"""<|user|>Ты — опытный автослесарь. Ответь на вопрос, используя ТОЛЬКО информацию из приведённого ниже контекста.
Если в контексте есть несколько причин или пунктов, перечисли их ВСЕ через дефис.
Если в контексте нет ответа, скажи: "Я не знаю".
Контекст:
{knowledge}
Вопрос: {query}<|end|>
<|assistant|>"""
output = llm(
prompt,
max_tokens=128,
temperature=0.3,
top_p=0.9,
repeat_penalty=1.1,
stop=["<|end|>", "<|user|>", "</s>"],
echo=False
)
return output["choices"][0]["text"].strip()
# === Gradio интерфейс ===
def chat_interface(user_query: str) -> str:
knowledge = load_knowledge_base()
return get_answer(user_query, knowledge)
# === Запуск (для Gradio 4.x) ===
if __name__ == "__main__":
llm = load_model()
demo = gr.Interface(
fn=chat_interface,
inputs=gr.Textbox(
lines=2,
placeholder="Например: Почему скрипят тормоза?",
label="🔧 Ваш вопрос по ремонту авто"
),
outputs=gr.Textbox(label="🛠 Ответ автоэксперта", max_lines=20),
title="🚗 Локальная авто-экспертная система",
description="""
<div style='text-align: center; margin: 10px 0;'>
<b>Полностью оффлайн. Работает на GPU.</b><br>
Знания из папки <code>knowledge_base/</code>.
</div>
""",
examples=[
["Почему двигатель троит на холостых?"],
["Что делать, если сел аккумулятор?"],
["Почему АКПП пинается при переключении передач?"],
],
theme=gr.themes.Soft(primary_hue="red").set(
body_background_fill="*neutral_50",
block_background_fill="white",
),
css="footer { display: none !important; }"
)
print("🧠 Модель загружена. Запуск GUI...")
demo.launch(server_name="127.0.0.1", server_port=7860)
Проверяем, что бы в строке
MODEL_PATH = "models/phi-3-mini-4k-instruct.Q4_K_M.gguf"
было записано точное название вашей языковой модели из папки models/. Если название вашего файла отличается, от того что записано в коде файла app.py, то скопируйте ваше и вставьте в эту строку вместо старого. Или, что ещё проще, переименуйте ваш файл phi-3-.....gguf в тот, который указан в коде (на работоспособность это никак не повлияет).
Часть 6. Наполняем базу данных knowledge_base/
Открываем папку knowledge_base/ и создаём в Блокноте несколько пустых файлов:
electrical.txt
engine_issues.txt
transmission.txt
Теперь открываем их в Блокноте и заполняем их примерами:
Для electrical.txt
[Аккумулятор сел]
- Напряжение <12.2 В — разряжен
- Утечка тока в бортовой сети (>50 мА)
- Генератор не заряжает (менее 13.8 В на холостых)
- Окисленные клеммы — зачистите и смажьте
[Фары тускло горят]
- Плохая масса на кузов.
- Низкое напряжение в сети (генератор неисправен)
Для engine_issues.txt
[Двигатель троит на холостом ходу]
- Проверьте свечи зажигания — износ или нагар
- Пробой катушек зажигания
- Подсос воздуха во впускном коллекторе
- Ошибки по OBD2: P0300 (пропуски зажигания)
- Низкая компрессия в цилиндре
Для transmission.txt
[АКПП пинается при переключении]
- Низкий уровень ATF
- Старое или грязное масло — замените
- Износ фрикционов — требуется ремонт
- Неисправность соленоидов или гидроблока
[МКПП скрежет при включении передачи]
- Износ синхронизаторов
- Не выжимается сцепление (воздух в приводе или износ выжимного подшипника)
Это начало вашей лично базы данных. Именно так и будет происходить обучение вашего "Эксперта".
База может быть любого содержания, но важно соблюдать следующие правила:
Формат файлов
- Только текстовые файлы с расширением .txt
- Кодировка: UTF-8 (чтобы поддерживались кириллица и спецсимволы)
- Имя файла — описательное, без пробелов и спецсимволов (лучше: engine_misfire.txt, а не новый файл (1).txt)
Ограничение по объёму
Общий объём всех файлов — не более 2000–2500 символов (примерно 400–500 токенов)
Почему? Потому что:
- Phi-3-mini имеет контекст 4096 токенов
Из них:
~300 токенов — системный промпт
~100 токенов — вопрос пользователя
~500–700 токенов — ответ модели
Остаётся ~2500–3000 токенов на контекст, но лучше играть на опережение и оставить запас
Если база растёт — разделите её на тематические подсистемы (engine/, brakes/) и запускайте отдельные экземпляры.
Структура содержимого
Заголовки в квадратных скобках или через ===:
[ТРОИТ ДВИГАТЕЛЬ НА ХОЛОСТЫХ]
Маркированные списки:
- Изношенные свечи зажигания
- Засорённые форсунки
- Подсос воздуха
- Изношенные свечи зажигания
Ключевые слова: совпадают с примерами вопросов
Ключевые слова в начале (для совпадения с вопросом):
«Скрип тормозов», «Ошибка P0300», «АКПП пинается»
Нет "воды", только факты
Избегайте:
- Длинных абзацев
- Вводных фраз: «Как известно…», «Следует отметить, что…»
- Повторов и «воды»
- Сложных предложений
Точность и достоверность
Указывайте конкретные коды ошибок: P0300, C1234, а не «ошибки зажигания»
Используйте стандартные термины: ДПДЗ, АКПП, ЭБУ, ТЖ
Не допускайте двусмысленности:
Нет = «Может быть что угодно»
Да = «Наиболее вероятные причины: 1) ..., 2) ...»Язык и стиль
- Единый язык (в нашем случае — русский)
- Профессиональная лексика, но без излишнего жаргона
- Предпочтение повелительному наклонению или списку фактов
Часть 7. Запускаем программу и содаём ярлык на Рабочий стол.
Закрываем окно CMD, если оно было раньше открыто, запускаем виртуальное окружение:
cd C:\car_expert
venv_gpu_fresh\Scripts\activate
пишем команду запуска нашей программы:
python app.py
В окне CMD вы должны увидеть следующую картину (немного промотал вниз):
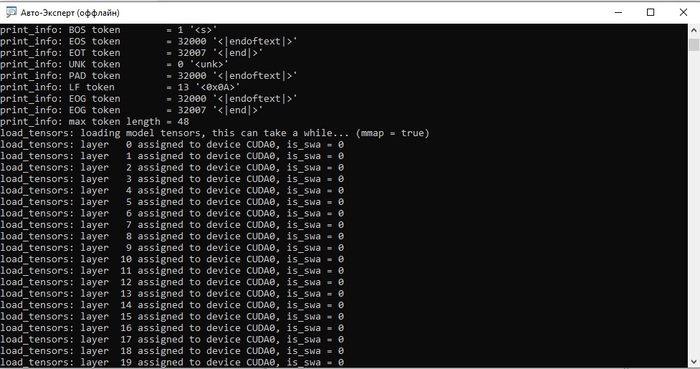
Надпись: load_tensors: layer 0 assigned to device CUDA0, is_swa = 0 означает, что работает видеокарта и обрабатывает поступающую информацию.
Открываем в браузере ссылку http://127.0.0.1:7860/ и наслаждаемся результатом:
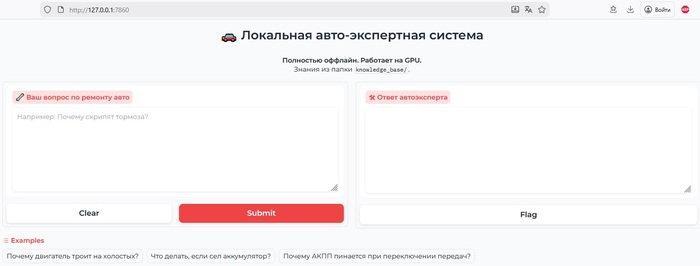
Делаем ссылку на ярлык для Рабочего стола:
- создаём в Блокноте файл, копируем и вставляем внутрь
сохраняем в корневую папку с названием Запустить авто-эксперта.bat.
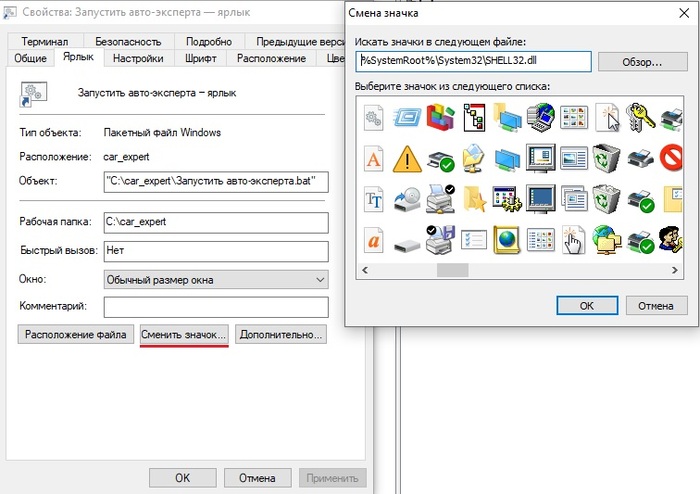
- кликаем на него правой кнопкой и выбираем "Создать ярлык".
- Перименовываем новый созданный файлик "Запустить авто-эксперта — ярлык.lnk" в "Авто-Эксперт (оффлайн).lnk".
- Кликаем по нему правой кнопкой мышки и нажимаем "Сменить значок", выбираем любой на свой вкус. Сохраняемся и закидываем его на рабочий стол.
Часть 8. Финальная.
Вот и всё. Мы своими собственными руками создали "великую и ужасную нейросеть" :) так что теперь смело можете говорить всем вокруг, что "...писали мы ваши нейросети, нет там ничего сложного" и гордо демонстировать свою работу. Текст надписей "морды лица" в браузере легко исправляется в коде файла app.py, база данных легко адаптируется под любые задачи.
Благодарю всех за внимание, если хотите меня отблагодарить и сподвигнуть на новые изобретения, можете задонатить, сколько не жалко :)
