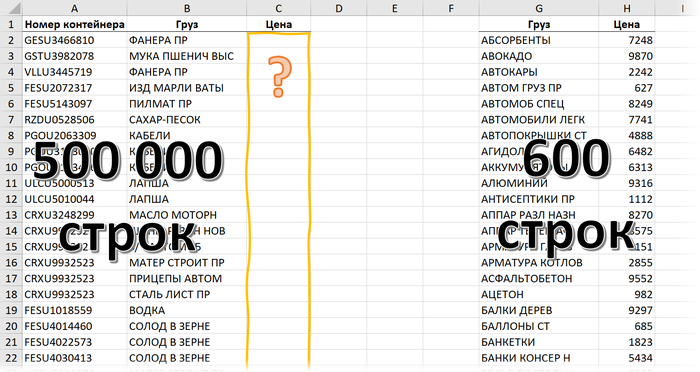
Это книга Excel с одним листом, где расположены две таблицы: отгрузки (500 000 строк) и прайс-лист (600 строк).
Задача - подставить цены из прайс-листа в таблицу отгрузок. Для каждого способа будем вводить формулу в ячейку С2 и копировать вниз на весь столбец, замеряя время, которое потребуется Excel, чтобы просчитать весь столбец из полумиллиона ячеек. Полученные значения, безусловно, зависят от множества факторов (поколение процессора, объем оперативной памяти, текущая загрузка системы, версия Office и т.д.), но нам важны не конкретные цифры, а, скорее, их сравнение друг с другом. Важно понимать прожорливость каждого способа и их ограничения.
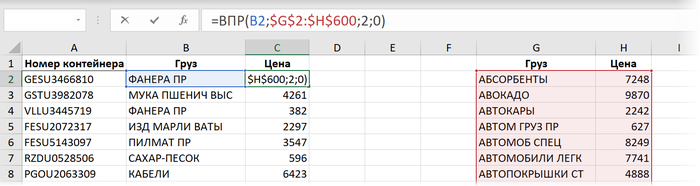
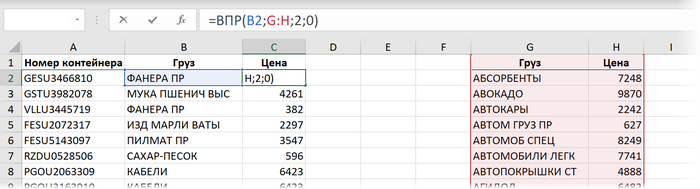
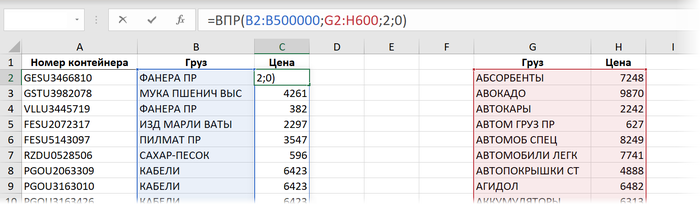
Способ 1. ВПР
Здесь участвуют следующие аргументы:
B2 - искомое значение, т.е. название товара, который мы хотим найти в прайс-листе
$G$2:$H$600 - закреплённая знаками доллара (чтобы не сползала при копировании формулы вниз) абсолютная ссылка на прайс
2 - номер столбца в прайс-листе, откуда мы хотим взять цену
0 или ЛОЖЬ - переключение в режим поиска точного соответствия, когда любое некорректное название товара (например, ФОНЕРА) в столбце "B" в таблице отгрузок приведёт к появлению ошибки #Н/Д как результата работы функции.
Время вычисления = 4,3 сек.
Способ 2. ВПР с выделением столбцов целиком
Многие пользователи, применяя ВПР, во втором аргументе этой функции, где нужно задать поисковую таблицу (прайс), выделяют не ограниченный диапазон ($G$2:$H$600), а сразу столбцы G:H целиком. Это проще, быстрее, позволяет не думать про F4 и то, что завтра прайс-лист может быть на несколько строк больше. Формула в этом случае выглядит тоже компактнее:
В старых версиях Excel такое выделение не сильно влияло на скорость вычислений, но сейчас результат получился в разы хуже предыдущего.
Время вычисления = 14,5 сек.
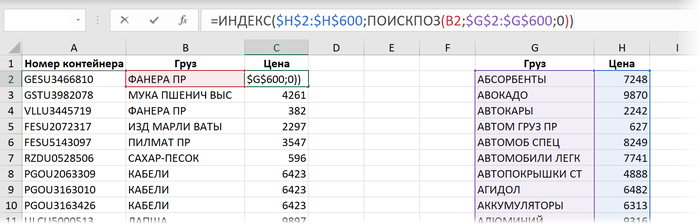
Способ 3. ИНДЕКС и ПОИСКПОЗ
Следующей после ВПР ступенью эволюции для многих пользователей Excel обычно является переход на использование связки функций ИНДЕКС (INDEX) и ПОИСКПОЗ (MATCH). Выглядит эта формула так:
Здесь:
Функция ИНДЕКС извлекает из заданного в первом аргументе диапазона (столбца $H$2:$H$600 с ценами в прайс-листе) содержимое ячейки с заданным номером. А номер этот, в свою очередь, определяется функцией ПОИСКПОЗ, у которой три аргумента:
- Что нужно найти - название товара из B2
- Где мы это ищем - столбец с названиями товаров в прайсе ($G$2:$G$600)
- Режим поиска: 0 - точный, 1 или -1 - приблизительный с округлением в меньшую или большую сторону, соответственно.
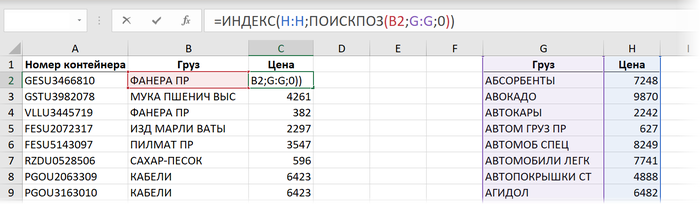
Формула выходит чуть сложнее, но, при этом имеет несколько ощутимых преимуществ перед классической ВПР, а именно:
- Не нужно отсчитывать номер столбца (как в третьем аргументе ВПР).
- Можно извлекать данные, которые находятся левее столбца, где происходит поиск.
По скорости, однако же, этот способ проигрывает ВПР почти в два раза:
Время вычисления = 7,8 сек.
Если же, вдобавок, полениться и выделять не ограниченные диапазоны, а столбцы целиком:
... то результат получается совсем печальный:
Время вычисления = 28,5 сек.
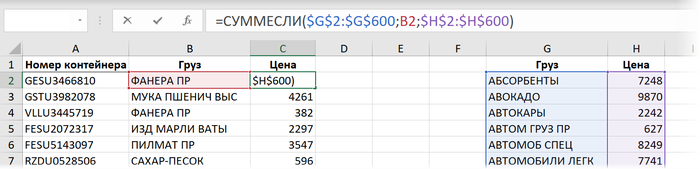
Способ 4. СУММЕСЛИ
Если нужно найти не текстовые, а именно числовые данные (как в нашем случае - цену), то вместо ВПР вполне можно использовать функцию СУММЕСЛИ (SUMIF). Изначально она задумывалась как инструмент для выборочного суммирования данных по условию (найди и сложи мне все продажи кабелей, например), но можно заставить её искать нужный нам товар и в прайс-листе. Если грузы в нём не повторяются, то суммировать будет не с чем и эта функция просто выведет искомое значение:
Здесь:
- Первый аргумент СУММЕСЛИ - это диапазон проверяемых ячеек, т.е. названия товаров в прайсе ($G$2:$G$600).
- Второй аргумент (B2) - что мы ищем.
- Третий аргумент - диапазон ячеек с ценами $H$2:$H$600, числа из которых мы хотим просуммировать, если в соседних ячейках проверяемого диапазона есть искомое значение.
Очевидным минусом такого подхода является то, что он работает только с числами. Также этот способ не удобен, если прайс-лист находится в отдельном файле - придется всё время держать его открытым, т.к. функция СУММЕСЛИ не умеет брать данные из закрытых книг, в отличие от ВПР, для которой это не проблема.
В плюсы же можно записать удобство при поиске сразу по нескольким столбцам - для этого идеально подходит более продвинутая версия этой функции - СУММЕСЛИМН (SUMIFS). Скорость вычислений же, при этом, весьма посредственная:
Время вычисления = 12,8 сек.
При выделении столбцов целиком, т.е. использовании формулы вида =СУММЕСЛИ(G:G; B2; H:H) всё ещё хуже:
Время вычисления = 41,7 сек.
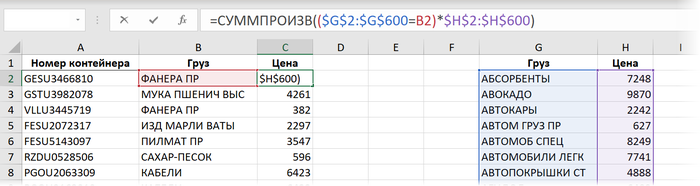
Способ 5. СУММПРОИЗВ
Этот подход сейчас встречается не часто, но всё ещё достаточно регулярно. Обычно так любят извращаться пользователи старой школы, ещё хорошо помнящие те времена, когда в Excel было всего 255 столбцов и 56 цветов :)
Суть этого метода заключается в использовании функции СУММПРОИЗВ (SUMPRODUCT), изначально предназначенной для поэлементного перемножения нескольких диапазонов с последующим суммированием полученных произведений. В нашем случае, вместо одного из массивов будет выступать условие, а вторым будут цены:
Выражение ($G$2:$G$600=B2), по сути, проверяет каждое название груза в прайс-листе на предмет соответствия искомому значению (ФАНЕРА ПР). Результатом каждого сравнения будет логическое значение ИСТИНА (TRUE) или ЛОЖЬ (FALSE), что в Excel интерпретируется как 1 и 0, соответственно. Последующее умножение этих нулей и единиц на цены оставит в живых цену только того товара, который нам, в данном случае, и нужен.
Эта формула является, по сути, формулой массива, но не требует нажатия обычного для них сочетания клавиш Ctrl+Shift+Enter, т.к. функция СУММПРОИЗВ поддерживает массивы уже сама по себе. Возможно, по этой же причине (формулы массива всегда медленнее, чем обычные) такой скорость пересчёта такой формулы - не очень:
Время вычисления = 11,8 сек.
К плюсам же такого подхода можно отнести:
- Совместимость с любыми, самыми древними версиями Excel.
- Возможность задавать сложные условия (и несколько)
- Способность этой формулы работать с данными из закрытых файлов, если добавить перед ней двойное бинарное отрицание (два подряд знака "минус"). СУММЕСЛИМН таким похвастаться не может.
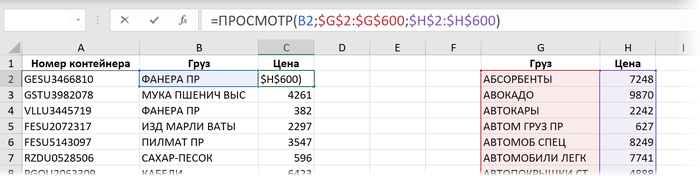
Способ 6. ПРОСМОТР
Ещё один относительно экзотический способ поиска и подстановки данных, наравне с ВПР - это использование функции ПРОСМОТР (LOOKUP). Только не перепутайте её с новой функцией ПРОСМОТРХ (XLOOKUP) - про неё мы поговорим дальше особо. Функция ПРОСМОТР существовала в Excel начиная с самых ранних версий и тоже вполне может решить нашу задачу:
Здесь:
- B2 - название груза, которое мы ищем
- $G$2:$G$600 - одномерный диапазон-вектор (столбец или строка), где мы ищем совпадение
- $H$2:$H$600 - такого же размера диапазон, откуда нужно вернуть найденный результат (цену)
На первый взгляд всё выглядит очень удобно и логично, но всю картину портят два неочевидных момента:
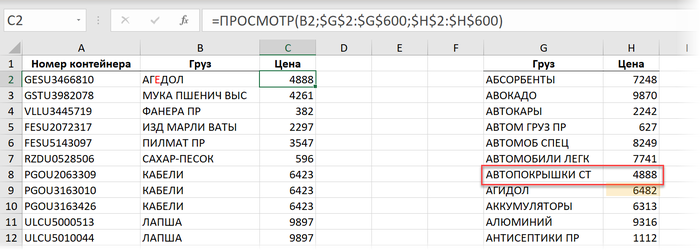
- Эта функция требует обязательной сортировки прайс-листа по возрастанию (алфавиту) и без этого не работает.
- Если в таблице отгрузок искомое значение будет написано с опечаткой (например, АГЕДОЛ вместо АГИДОЛ), то функция ПРОСМОТР выдаст не ошибку #Н/Д, а цену для ближайшего предыдущего товара:
При работе с неидеальными данными в реальном мире это гарантированно создаст проблемы, как вы понимаете.
Скорость же вычислений у функции ПРОСМОТР (LOOKUP) весьма приличная:
Время вычисления = 7,6 сек.
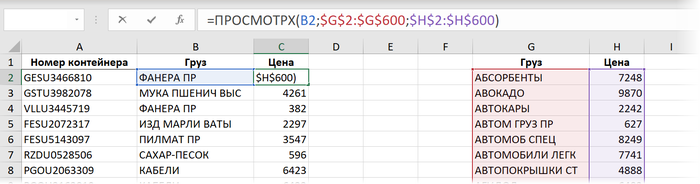
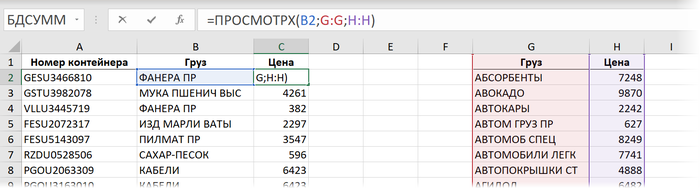
Способ 7. Новая функция ПРОСМОТРХ
Эта функция пришла с одним из недавних обновлений пока только пользователям Office 365 и пока отсутствует во всех остальных версиях (Excel 2010, 2013, 2016, 2019). По сравнению с классической ВПР у этой функции есть масса преимуществ (упрощенный синтаксис, возможность искать не только сверху-вниз, возможность сразу задать значение вместо #Н/Д и т.д.) Формула для решения нашей задачи будет выглядеть в этом случае так:
Если не брать в расчёт необязательные 4,5,6 аргументы, то синтаксис этой функции полностью совпадает с её предшественником - функцией ПРОСМОТР (LOOKUP). Скорость вычислений при тестировании на наши 500000 строк тоже оказалась аналогичной:
Время вычисления = 7,6 сек.
Почти в два раза медленнее, чем у ВПР, вместо которой Microsoft предлагает теперь использовать ПРОСМОТРХ. Жаль.
И, опять же, если полениться и выделить диапазоны в прайс-листе целыми столбцами:
... то скорость падает до совершенно неприличных уже значений:
Время вычисления = 28,3 сек.
А если на динамических массивах?
Прошлогоднее (осень 2019) обновление вычислительного движка Microsoft Excel добавило ему поддержку динамических массивов (Dynamic Arrays). Это принципиально новый подход к работе с данными, который можно использовать почти с любыми классическими функциями Excel. На примере ВПР это будет выглядеть так:
Разница с классическим вариантом в том, что первым аргументом ВПР здесь выступает не одно искомое значение (а формулу потом нужно копировать вниз на остальные строки), а сразу весь массив из полумиллиона грузов B2:B500000, цены для которых мы хотим найти. Формула при этом сама распространяется вниз, занимая требуемое количество ячеек.
Скорость пересчета в таком варианте меня, откровенно говоря, ошеломила - пауза между нажатием на Enter после ввода формулы и получением результатов почти отсутствовала.
Время вычисления = 1 сек.
Что интересно, и новая ПРОСМОТРХ, и старая ПРОСМОТР, и связка ИНДЕКС+ПОИСКПОЗ в таком режиме тоже были очень быстрыми - время вычислений не больше 1 секунды! Фантастика.
А вот олдскульные подходы на основе СУММПРОИЗВ и СУММЕСЛИ(МН) с динамическими массивами работать отказались :(
Что с умными таблицами?
Обрадовавшись фантастическим результатам, полученным на динамических массивах, я решил вдогон попробовать протестировать разницу в скорости при работе с обычными и "умными" таблицами. Я имею ввиду те самые "красивые таблицы", в которые вы можете преобразовать ваш диапазон с помощью команды Форматировать как таблицу на вкладке Главная (Home - Format as Table) или с помощью сочетания клавиш Ctrl+T.
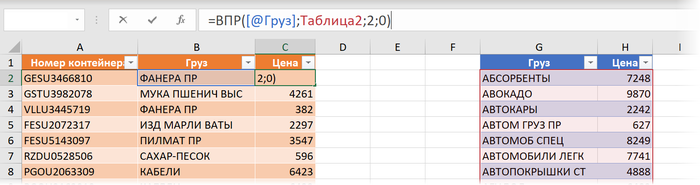
Если предварительно превратить наши отгрузки и прайс в "умные" (по умолчанию они получат имена Таблица1 и Таблица2, соответственно), то формула с той же ВПР будет выглядеть как:
Здесь:
[@Груз] - ссылка на ячейку B2, означающая, в данном случае, что нужно взять значение из той же строки из столбца Груз текущей умной таблицы.
Таблица2 - ссылка на прайс-лист
Жирным плюсом такого подхода будет возможность легко добавлять данные в наши таблицы в будущем. При дописывании новых строк в отгрузки или к прайс-листу, наши "умные" таблицы будут растягиваться автоматически.
Скорость же, как выяснилось, тоже вырастает очень значительно и примерно равна скорости работы на динамических массивах:
Время вычисления = 1 сек.
У меня есть подозрение, что дело тут не в самих "умных" таблицах, а всё в том же обновлении вычислительного движка, т.к. на старых версиях Excel такого прироста в скорости на умных таблицах я не помню.
Бонус. Запрос Power Query
Замерять, так замерять! Давайте, для полноты картины, сравним наши перечисленные способы еще и с запросом Power Query, который тоже может решить нашу задачу. Кто-то скажет, что некорректно сравнивать пересчёт формул с механизмом обновления запроса, но мне, откровенно говоря, просто самому было интересно - кто быстрее?
Итак:
1. Превращаем обе наши таблицы в "умные" с помощью команды Форматировать как таблицу на вкладке Главная (Home - Format as Table) или с помощью сочетания клавиш Ctrl+T.
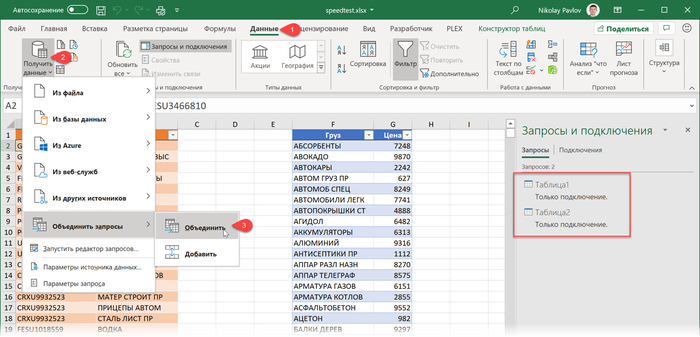
2. По очереди загружаем таблицы в Power Query с помощью команды Данные - Из таблицы / диапазона (Data - From Table/Range).
3. После загрузки в Power Query возвращаемся обратно в Excel, оставляя загруженные данные как подключение. Для этого в окне Power Query выбираем Главная - Закрыть и загрузить - Закрыть и загрузить в... - Только создать подключение (Home - Close&Load - Close&Load to... - Only create connection).
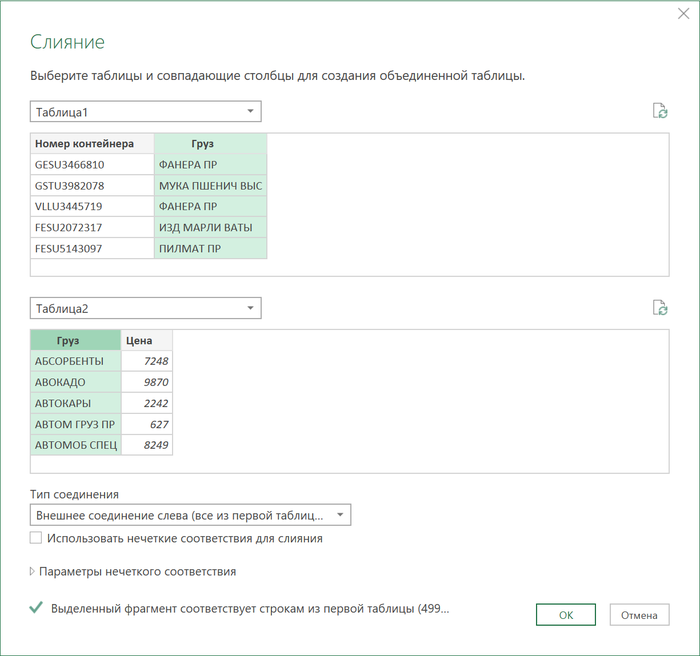
4. После того, как обе исходные таблицы будут загружены как подключения, создадим ещё один, третий запрос, который будет объединять их между собой, подставляя цены из прайса в отгрузки. Для этого на вкладке Данные выберем Получить данные / Создать запрос - Объединить запросы - Объединить (Get Data / New Query - Merge queries - Merge):
5. В открывшемся окне выберем исходные таблицы в выпадающих списках и выделим столбцы, по которым произойдет связывание:
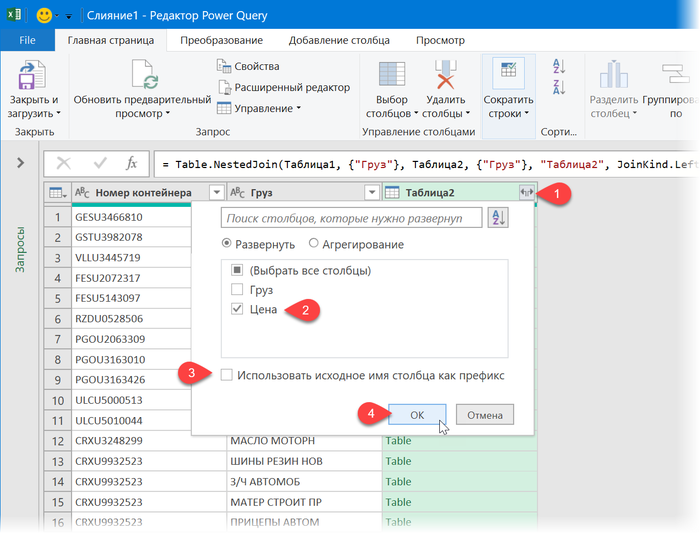
После нажатия на ОК мы вернемся в окно Power Query, где увидим нашу таблицу отгрузок с добавленным к ней столбцом, где в каждой ячейке будет лежать фрагмент прайс-листа, соответствующий этому грузу. Развернем вложенные таблицы с помощью кнопки с двойными стрелками в шапке столбца, выбрав нужные нам данные (цены):
7. Останется выгрузить готовую таблицу обратно на лист с помощью уже знакомой команды Главная - Закрыть и загрузить (Home - Close&Load).
В отличие от формул, запросы Power Query не обновляются автоматически "на лету", а требуют щелчка правой кнопкой мыши по таблице (или запросу в правой панели) и выбору команды Обновить (Refresh). Также можно воспользоваться командой Обновить все (Refresh All) на вкладке Данные (Data).
Время обновления = 8,2 сек.
Итоговая таблица и выводы
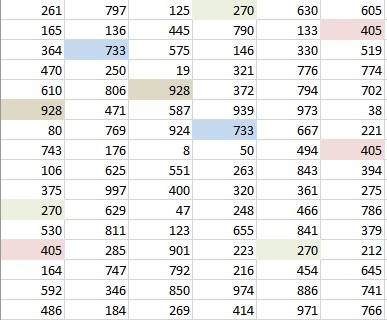
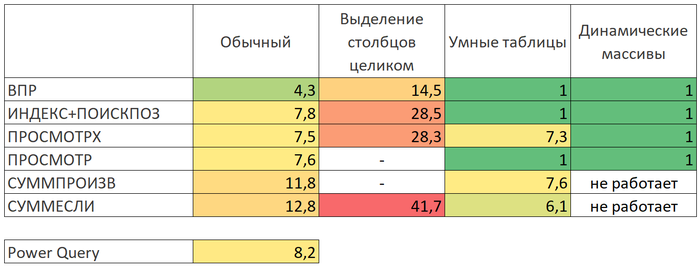
Если вы честно дочитали до этого места, то какие-то выводы, наверное, уже сделали самостоятельно. Если же пропустили все детали и сразу перешли к итогам, то вот вам общая результирующая таблица по скорости всех методов:
Само-собой, у каждого из нас свои предпочтения, задачи и тараканы, но для себя я сформулировал выводы после этого тестирования так:
- ВПР всё ещё главная рабочая лошадка. После прошлогодних обновлений, ускоряющих ВПР, и осенних обновлений вычислительного движка, эта функция заиграла новыми красками и даёт жару по-полной.
- Не нужно лениться и выделять столбцы целиком - для всех способов без исключения это ухудшает результаты почти в 3 раза.
- Экзотические способы из прошлого типа СУММПРОИЗВ и СУММЕСЛИ - в топку. Они работают очень медленно и, вдобавок, не поддерживают динамические массивы.
- Динамические массивы и умные таблицы - это будущее.