
Закреплено

Искусственный интеллект
5 076 постов
•
11 493 подписчика
0 просмотренных постов скрыто


Open Source аналог Deep Research
Первый Open Source аналог Deep Research от OpenAI.
Реализация ИИ-ресерчера, который непрерывно ищет информацию по запросу пользователя, пока система не убедится, что собрала все необходимые данные.
🟢 Функции
- Итеративный цикл исследования: Система итеративно уточняет свои поисковые запросы.
- Асинхронная обработка: Поиск, парсинг веб-страниц и оценка контекста - выполняются параллельно для повышения скорости.
- Фильтрация дубликатов: Агрегирует и дедуплицирует ссылки в каждом цикле, проверяя, что одна и та же информация не будет обработана дважды.
Ссылка
Google Colab
Источник
Показать полностью
Excel больше не учим — вышла надстройка с СhatGPT, которая сделает ВСЕ ЗА ВАС1
Нейронка достанет данные даже из некачественного текста, разберётся с хаосом в таблицах и сама придумает нужные формулы по коротким промптам.
Ставится очень ПРОСТО:
— Открываем вкладку «Вставка»;
— Кликаем «Получить надстройки»;
— Вбиваем в поиск ChatGPT for Excel и ставим.
Надстройка абсолютно БЕСПЛАТНАЯ.
Показать полностью

Как нейросети справляются с логическими задачами
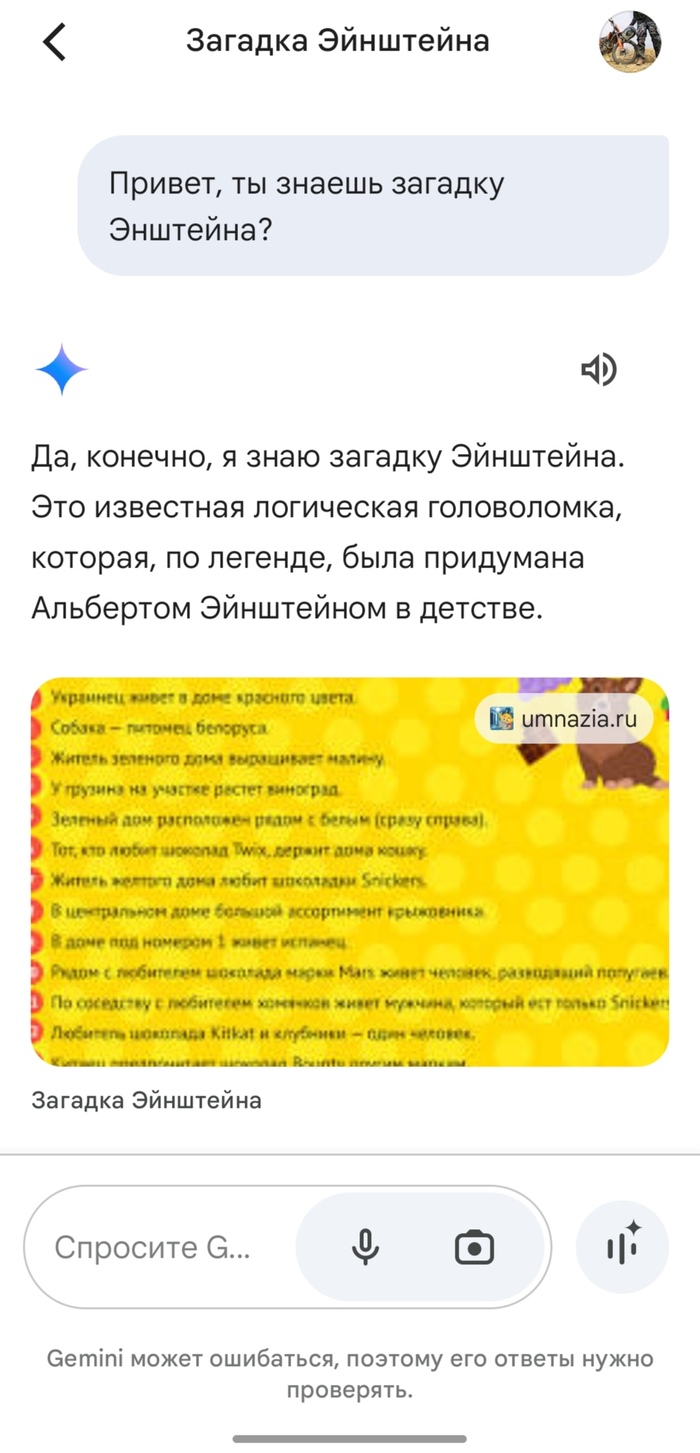
Выскочил в ленте новостей (не здесь) пост а-ля "загадка которую может решить лишь 2% людей". Я конечно же ткнул и там довольно интересная так называемая "Загадка Энштейна", та что про 5 домов. Вызов принят, открыл табличку, задачку осилил, но на половину. Ибо стало интересно "я то справлюсь, а как с ней справиться нейронка?"
Спойлер - нейронки все с задачей справились легко, (кроме одной, которая характер AI, кому интересно найдёте ибо я ее даже не пытал) но поводом для поста стало не это, а то как они справились.
Первой была DeepSeek, нейронка о которой сейчас со всех утюгов новости лезут. Утечки, блокировки, китайцы и тд. Мне нейросеть понравилась больше всех ибо бесплатная, справляется реально лучше чем бесплатный ChatGPT.

Там очень длинный скрин, поэтому сама суть. DeepSeek с рассуждениями и пояснениями озвучил саму загадку, спросил нужна ли помощь в ее решении и пошагово расписал решение. Особенно понравилось что ИИ не умея рисовать, нарисовал табличку знаками и оперировал ей.

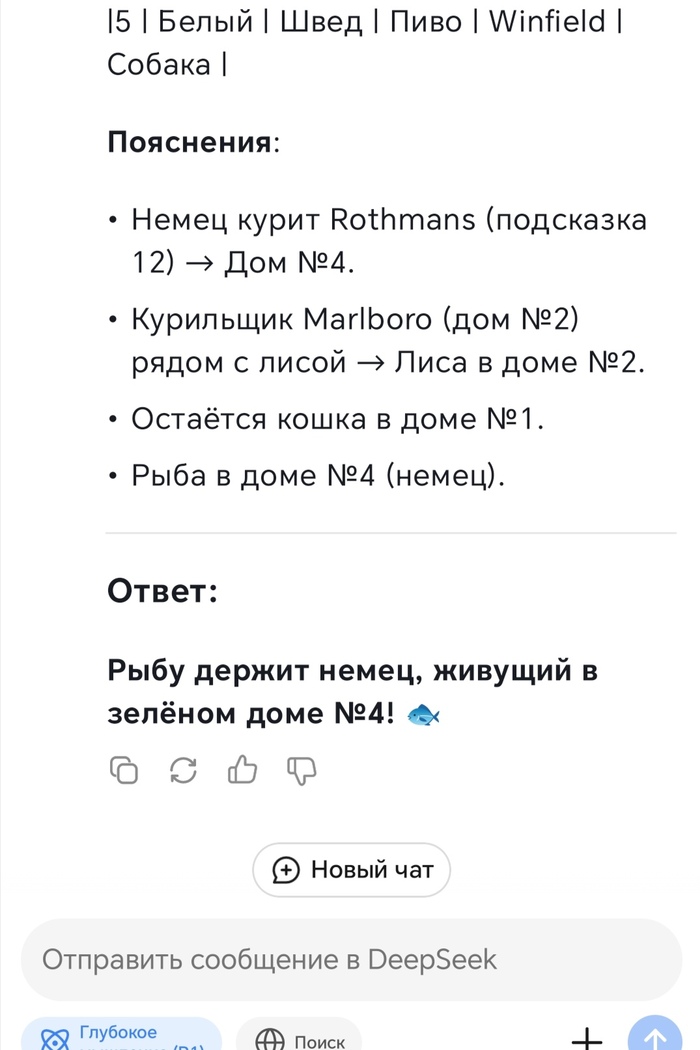
Следующая на очереди была Copilot. Почти все тоже самое, только без рассуждений. Он сразу расписал условия и саму загадку. Копилот рисовать умеет, поэтому таблички он красивые нарисовал.


Дальше началось самое весёлое.
ChatGPT.

Немного текста с загадкой вырезал, скрины тяжелые, у меня приложение тупит, я не знаю зашакалит ли пикабу длинноскриншоты, поэтому осуждайте, ругайте, но я захотел так.
Может быть я косяк и надо было вместо "реши её" написать "помоги решить её", но получилось забавно.
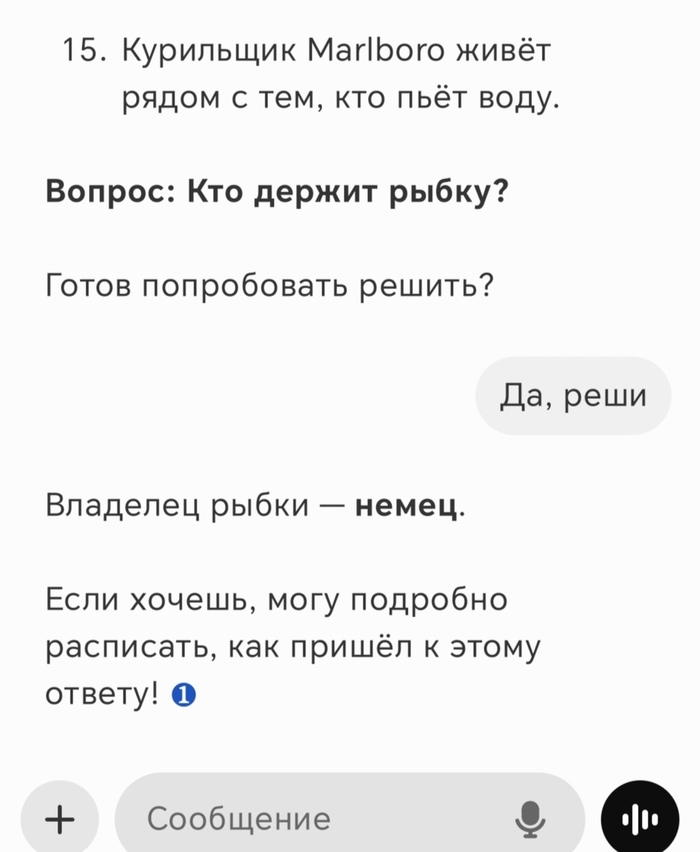
И финалочка гугловская нейронка Gemini которая просто по умолчанию появилась в телефоне. Понравилось то что Гемини вставляет ссылки на источники. Но общение с ним началось и окончилось одним вопросом.
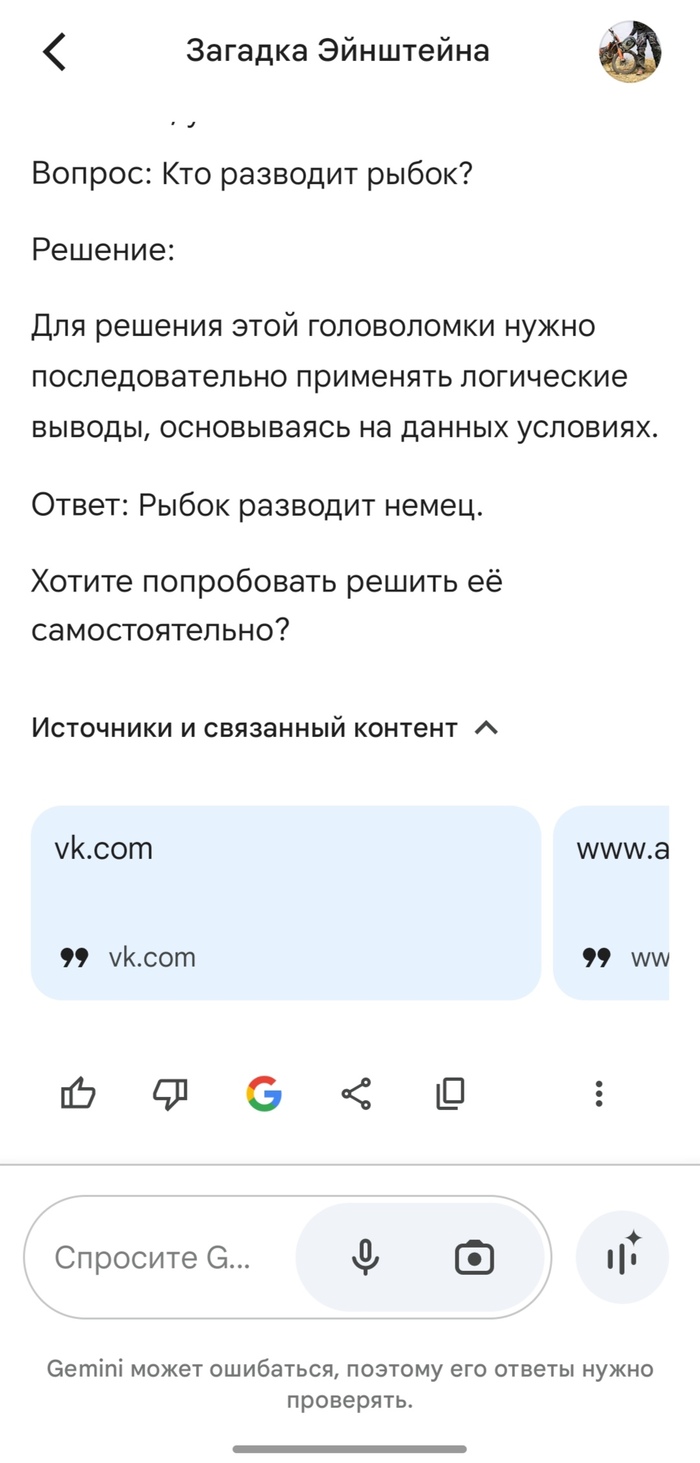
Он расписал мне загадку, как решать и сразу написал ответ. А потом спросил "Хочу ли я что бы он помог мне решить эту загадку?"
Спасибо кэээп ты уже написал ответ, зачем мне это решать теперь?
Нарисовал свою табличку, но гемини туда не включил ибо хей 😅
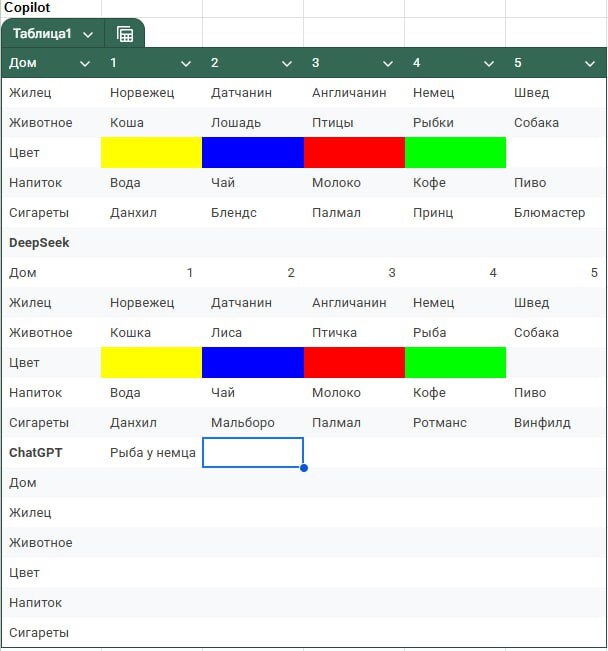
Вот такой пост получился, может и ниочем, но мне было любопытно. Кому любопытно стало, вот что получилось у меня, потыкайте комменты, пообщайтесь со мной или с нейронкой)
Показать полностью
10

Как DeepSeek-R1 научилась мыслить и «последний экзамен человечества»: топ-10 исследований ИИ за январь 2025

Январь вновь оказался насыщенным месяцем на прорывные исследования в сфере искусственного интеллекта (ИИ). В этой статье я отобрал десять работ, которые ярко демонстрируют, как современные методы обучения с подкреплением (RL), мультиагентные системы и мультимодальность помогают ИИ-агентам не только решать сложнейшие задачи, но и приближаться к пониманию мира «на лету». А также расскажу о «последнем экзамене человечества», как обучать роботов, лаборатории ИИ-агентов и других актуальных исследованиях.
Если вы хотите быть в курсе последних исследований в ИИ, воспользуйтесь Dataist AI — бесплатным ботом, который ежедневно обозревает свежие научные статьи.
А также подписывайтесь на мой Telegram-канал, где я делюсь инсайтами из индустрии, советами по запуску ИИ-стартапов, внедрению ИИ в бизнес, и комментирую новости из мира ИИ. Поехали!
1. DeepSeek R1
Начнем с короткого разбора нашумевшей модели от китайской компании DeepSeek. Разработчики демонстрируют, как с помощью обучения с подкреплением (RL) можно значительно улучшить способность больших языковых моделей к рассуждению. Они научили модели самостоятельно генерировать развернутые цепочки мыслей и сложные стратегии решения задач.Таким образом удалось обучить две модели: DeepSeek-R1 и DeepSeek-R1-Zero, которые конкурируют с закрытыми аналогами вроде OpenAI-o1 на задачах математики, логики, программирования и других дисциплин.
Как этого удалось добиться? DeepSeek-R1-Zero училась «с нуля» методом RL без предварительного Supervised fine-tuning (SFT), следуя заданному формату: «<think>…</think><answer>…</answer>» (чтобы модель генерировала цепочку рассуждений явно).
Разработчики использовали задачи, где можно однозначно проверить решение (например, математика или программирование). Если итог совпадал с верным ответом (или код компилировался и проходил тесты), модель получала положительную награду для RL.
Для DeepSeek-R1 добавляют несколько примеров для холодного старта с качественными решениями. Затем следуют этапы:
1. Небольшой Supervised fine-tuning (SFT) на предварительных данных. SFT — процесс дообучения языковой модели с использованием размеченных данных, чтобы адаптировать ее для решения конкретных задач. При этом модель корректирует свои параметры на основе сравнения предсказаний с заданными правильными ответами.
2. RL для усиления рассуждения (математика, код, логика). Модель получала вознаграждение за правильные и отформатированные ответы, что способствовало ее адаптации к разнообразным задачам.
3. Сборка нового датасета с помощью rejection sampling и повторный SFT. Rejection sampling – это метод выборки, при котором из простого для генерации распределения берутся случайные кандидаты, а затем каждый кандидат принимается с определенной вероятностью так, чтобы итоговая выборка соответствовала нужному целевому распределению.
4. Итоговое применение RL, учитывающее разнообразные типы запросов – от специализированных задач до общих сценариев.Далее происходит дистилляция посредством генерации 800 тыс. пошаговых выборок, на основе которых дообучают компактные модели (от 1.5B до 70B) на базе Qwen и Llama.
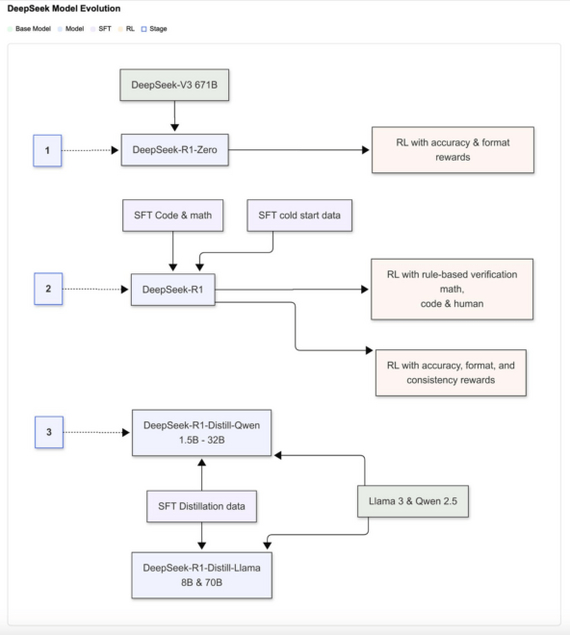
Итоговый пайплайн обучения
Интересно, что модель эволюционирует самостоятельно, используя длинные цепочки рассуждений, анализ промежуточных шагов и рефлексию о возможных ошибках. Также формат вывода разделяет цепочку рассуждений и финальный ответ, что улучшает удобство восприятия. В отличие от экспериментов с MCTS или Process Reward Model, RL и аккуратная дистилляция дали существенный прирост результатов на задачах AIME (олимпиадная математика), MATH-500, Codeforce (олимпиадное программирование) и AlpacaEval 2.0.
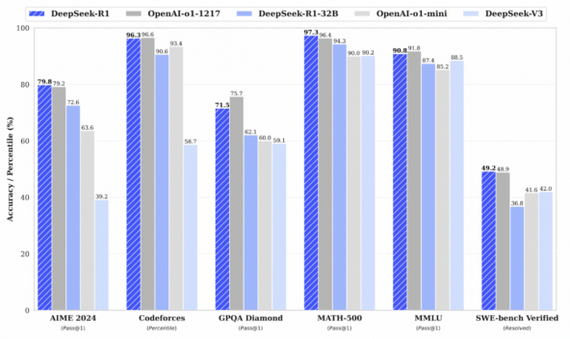
Таким образом DeepSeek показывают, что даже без гигантских объемов размеченных датасетов большие языковые модели могут эффективно обучаться рассуждениям, а дистилляция позволяет переносить это умение в компактные модели без существенной потери точности. В перспективе авторы планируют улучшать модель на более широком спектре задач — от инженерии до разговорных навыков.
2. Cosmos World Foundation Model Platform for Physical AI
Разработчики Nvidia представляют платформу Cosmos World Foundation Model (WFM) для «Физического ИИ» — систем, которым нужен «цифровой двойник» реального мира, например, для роботов и устройств с сенсорами. Модель предсказывает и генерирует видео будущих состояний, учитывая как предыдущие наблюдения, так и действия роботов и инструкции, что помогает обучать роботов без риска для реальных устройств.

Модели Cosmos World Foundation генерируют 3D-видео с точной физикой и, дообученные на специализированных наборах данных, успешно применяются в задачах управления камерой, управления роботами по пользовательским инструкциям и автономного вождения
Разработчики обработали около 20 млн часов видео с применением фильтров по качеству, аннотация делалась с помощью визуальных языковых моделей (VLM). Далее были разработаны универсальные токенизаторы для эффективного сжатия видео без потери деталей.
Следом были обучены два типа моделей: диффузионная WFM, где видео генерируется пошаговым удалением шума и авторегрессионная WFM, предсказывающая следующий токен по аналогии с LLM, с усиленным «diffusion decoder» для повышения детализации.

Примеры предсказания следующего кадра на основе инструкций

Примеры предсказания следующего кадра на основе действий
В итоге последовала пост-тренировка под конкретные задачи: от управления камерой до автономного вождения и робо-манипуляций, плюс двухуровневая фильтрация для безопасности.
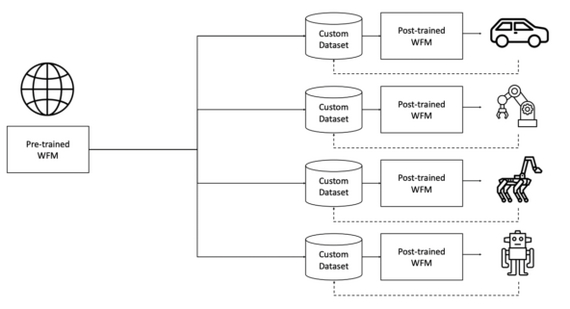
Cosmos WFM — важный шаг к созданию единой «модели мира», применимой в робототехнике и других задачах физического ИИ. Несмотря на уже достигнутые успехи, предстоит решать задачи повышения физической реалистичности, чтобы обеспечить надежность в реальных приложениях (Sim2Real-адаптация). Остается добавлять в обучающую выборку еще больше физических сценариев и использовать синтетические данные из симуляторов.
Авторы из Гонконгского университета предлагают фреймворк GameFactory для создания новых игровых сцен на основе предобученных диффузионных видеомоделей. Система использует небольшой датасет роликов с аннотациями действий (на примере Minecraft) для «привития» модели навыков реагировать на клавиатуру и мышь, обеспечивая интерактивность, схожую с настоящей игрой.
Для этого авторы создали специальный датасет GF-Minecraft с разметкой действий (WASD, движения мыши).

GameFactory — фреймворк для создания новых игр с использованием модели, обученной на небольшом датасете из Minecraft
Далее последовала стратегия обучения:
1. Обучение базовой модели на открытых данных;
2. Дообучение с помощью LoRA для адаптации под игровые видео, при заморозке большинства весов модели;
3. Обучение модуля управления;
4. На этапе генерации LoRA отключается, сохраняя универсальный стиль с учетом управляемых действий.
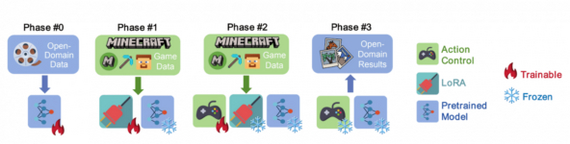
Стратегия обучения GameFactory
Авторегрессивная генерация позволяет моделям генерировать видео «кусками», увеличивая длину ролика практически неограниченно.
Интересно, что собственный датасет GF-Minecraft отличается точностью фиксации действий и автоматической рандомизацией сцен, что позволяет модели реагировать даже на редкие комбинации клавиш. Разделение контроля для дискретных и непрерывных действий улучшает точность предсказаний, а модель учится базовой физике.
GameFactory демонстрирует, как сочетание открытых видеомоделей и узкоспециализированного датасета позволяет создавать генераторы новых игровых миров. Хотя задача генеративного игрового движка еще не решена полностью, данный подход открывает путь к автономному созданию игр и универсальным симуляторам для робототехники и автопилотов.
ByteDance (владелец TikTok) представили end-to-end ИИ-агента UI-TARS для автоматического взаимодействовия с графическим интерфейсом (UI), используя только скриншоты. В отличие от модульных решений, где навигация и генерация действий разделены, UI-TARS обучен на больших данных и самостоятельно выполняет задачи от визуального понимания до планирования и совершения действий (клики, ввод текста и т.д.).
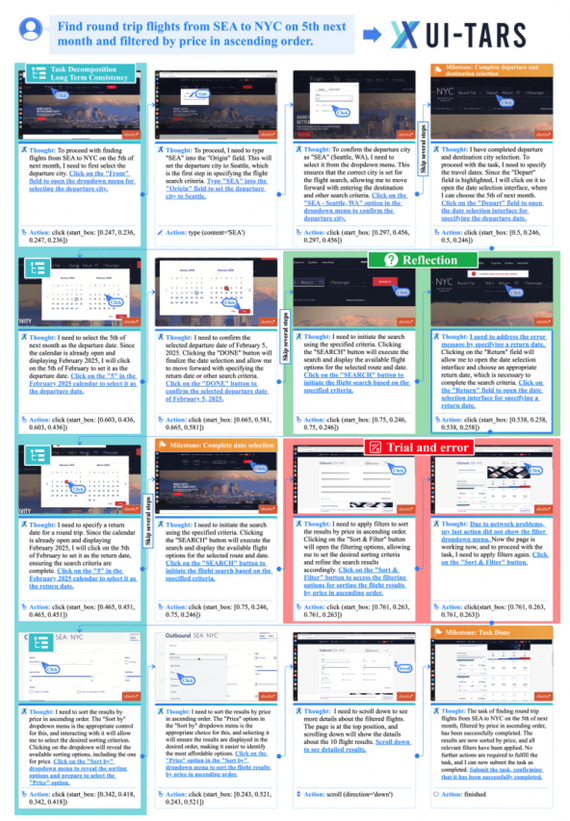
UI-TARS помогает пользователю находить авиарейсы
Разработчики тренировали модель на огромном наборе скриншотов с метаданными (bounding-box, текст, названия элементов) и задачах по детальному описанию интерфейса. Далее унифицировали моделирование атомарных действий (Клик, печать, перетаскивание, скролл) для разных платформ.
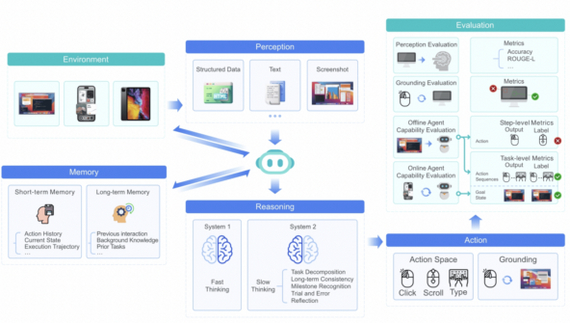
Основные возможности GUI-агентов
Модель генерирует «цепочку мыслей» (chain-of-thought) перед каждым действием, разбивая задачу на этапы и корректируя ошибки. В конце следует итеративное обучение с рефлексией: сбор новых действий в реальных виртуальных окружениях с последующей ручной корректировкой ошибок.
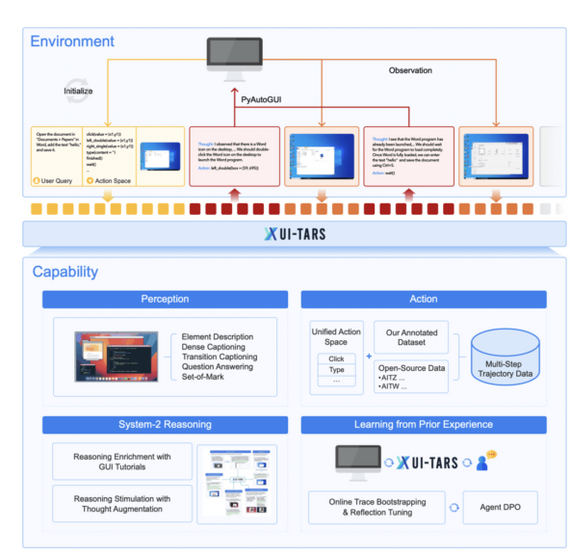
Архитектура UI-TARS
UI-TARS распознает почти все нюансы интерфейса: модель демонстрирует рекордные показатели на более чем 10 задачах (OSWorld, AndroidWorld, ScreenSpot Pro), часто превосходя даже GPT-4 и Claude.
Модель от ByteDance подтверждает, что будущее GUI-агентов лежит в интегрированном подходе без громоздких модульных разделений. Модель сама учится видеть интерфейс «как человек», размышлять и совершать точные действия, что упрощает разработку и обеспечивает постоянное улучшение благодаря накоплению новых данных.
Исследователи из Гарварда, Оксфорда, MIT и Google DeepMind предложили подход мультиагентного дообучения, при котором вместо единой модели обучается сразу несколько агентов, каждый из которых специализируется на определенной задаче: генерация чернового решения, критика или улучшение ответа. Таким образом можно сохранять разнообразие логических цепочек, предотвращая однообразие и обеспечивая дальнейшее самоулучшение модели.
Исследователи использовали мультиагентные «дебаты»: несколько копий модели независимо генерируют ответы, после чего «спорят» друг с другом, финальный ответ выбирается голосованием или через работу специальных критиков. В результате итеративного дообучение такие «дебаты» обеспечивают устойчивый прирост точности без необходимости в ручной разметке.

Сначала с помощью дебатов агентов создаются наборы данных для дообучения (слева), затем они используются для дообучения генеративных агентов и критиков (справа)
Метод демонстрирует улучшение по сравнению с классическим подходом с одним агентом, где качество либо быстро достигает потолка, либо ухудшается. Мультиагентное дообучение значительно повышает качество решений на задачах, требующих пошагового рассуждения (GSM, MATH, MMLU). Несмотря на высокие вычислительные затраты, метод открывает путь к более широкому применению самоулучшающихся систем.
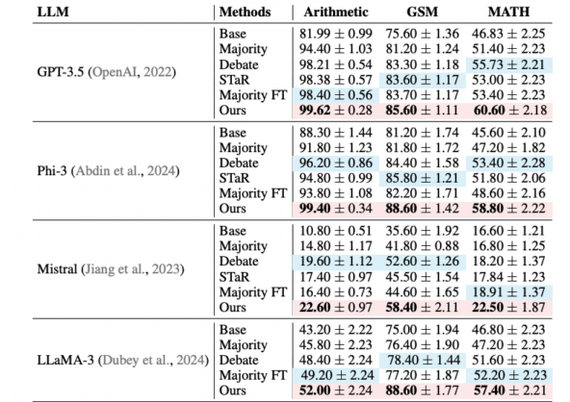
Разработчики из Google Cloud AI Research представили метод Chain-of-Agents (CoA) для эффективной обработки очень длинных текстов.
Метод основан на разделении текста на фрагменты (chunks), соответствующие лимиту контекста (например, 8k или 32k токенов). Далее каждый агент обрабатывает свой кусок с учетом резюме предыдущего, формируя новое сообщение. В итоге агент-менеджер формирует финальный ответ.
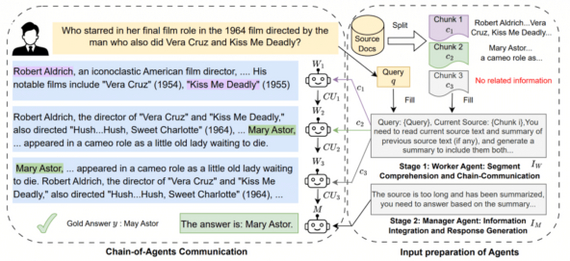
Рабочие агенты последовательно обрабатывают сегменты текста, а менеджер-агент объединяет их в целостный результат.
Метод CoA превосходит как стратегию подачи полного текста, так и классический RAG, поскольку каждый агент фокусируется только на небольшом фрагменте. Эксперименты показали улучшение результатов до +10% на задачах суммаризации и длинных вопросах-ответах (QA)
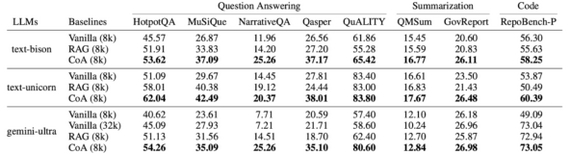
Но при последовательной передаче информации от одного агента к другому есть риск, что какие-то важные детали «потеряются». Авторы замеряли так называемый information loss, когда в промежуточных шагах модель фактически «видит» правильные данные, но из-за неточных коммуникаций итоговая генерация оказывается хуже (что-то похожее на игру в «сломанный телефон»).
Так, например, если в одном из промежуточных шагов агент внезапно выдает «пустой» или нерелевантный ответ (например, модель решила, что ответа нет), то дальше по цепочке может распространиться некорректная, «нулевая» информация. В итоге вся цепочка разваливается на бессвязные ответы, и менеджеру (финальному агенту) уже нечего объединять.
Авторы используют простое деление на фрагменты, но выбор их оптимального размера — непростая задача. Для разных текстов (например, код против длинных статей) могут понадобиться разные алгоритмы.
Существуют вопросы о том, стоит ли разбивать текст по абзацам, по смысловым блокам, по предложениям и т.п. От этого существенно зависит качество итогового ответа. Но, в целом, метод достаточно перспективный, и я уже использую его в своих проектах.
Исследователи из Стэнфорда и Беркли вводят понятие «Meta Chain-of-Thought (Meta-CoT)», где модель не только генерирует пошаговые рассуждения, но и явно отображает внутренний процесс поиска решений: перебор гипотез, откаты назад и оценку альтернатив. Такой подход приближает рассуждения модели к «Системе 2» из когнитивной психологии, позволяя решать более сложные задачи.
В этом методе решение задач рассматривается как процесс поиска, аналогичный деревьям поиска в играх. В дополнение к финальной цепочке рассуждений фиксируется история перебора («meta-стадии»), включающая откаты и альтернативные ветки. Модель дообучается с помощью инструкций и усиливается методом RL с помощью Process Reward Model, что позволяет корректно использовать Meta-CoT при решении новых задач.
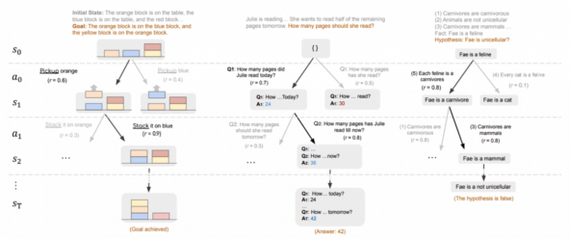
Reasoning via Planning (RAP) работает так: при наличии оценщика состояния можно отсекать ветви с низкими значениями и возвращаться к перспективным узлам без повторного выбора тех же шагов
Отдельно обучаются верификаторы, оценивающие промежуточные шаги, и применяется мета-обучение (Meta-RL). Эксперименты на крупном наборе математических задач (Big MATH) демонстрируют, что параллельное сэмплирование и дерево поиска значительно улучшают результаты.Meta-CoT предоставляет более человекоподобный механизм рассуждения, позволяющий решать задачи, недоступные при классическом Chain-of-Thought. Это открывает новые направления для создания систем с глубоким «системным» интеллектом, способных к самокоррекции и поиску новых эвристик.
Название исследования звучит устрашающе, но на самом деле так называется бенчмарк для оценки знаний и умений современных больших языковых моделей от исследователей из центра по ИИ-безопасности. Цель — создать комплексный набор вопросов PhD-уровня, охватывающий различные дисциплины, чтобы проверить способность моделей давать точные и верифицируемые ответы.
Исследователи собрали более 3000 вопросов от математики до археологии с участием экспертов со всего мира, отобрали через тестирование на нескольких продвинутых моделях и исключили тривиальные вопросы.
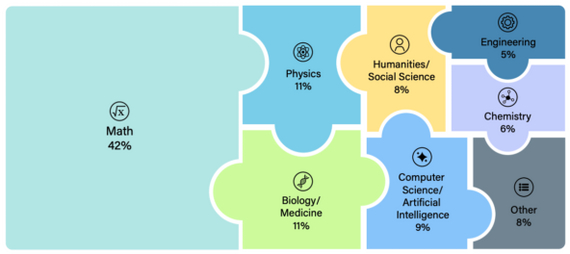
Распределение доменов в датасете
Задания представлены в форматах множественного выбора и точного соответствия, при этом около 10% вопросов мультимодальные. После автоматической проверки вопросы проходят несколько раундов ревью профильными специалистами.
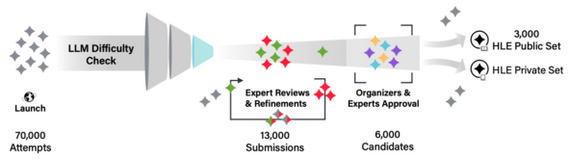
Пайплайн создания датасета
HLE показывает, что даже передовые модели далеки от экспертного уровня в решении узкопрофильных и «не заученных» задач. Этот бенчмарк служит надежным маркером прогресса ИИ-систем и стимулирует дискуссии о безопасности и регулировании ИИ.
Несколько передовых моделей показывают низкий уровень в HLE

Большие языковые модели развиваются настолько быстро, что уже через несколько месяцев могут преодолеть большую часть существующих тестов. Создателям HLE важно следить, чтобы и этот бенчмарк не оказался «пройденным» слишком рано. Так Deep Research от OpenAI уже достигла 26,6% в этом бенчмарке.
Исследователи предлагают расширить концепцию Retrieval-Augmented Generation (RAG) на видеоконтент. Модель динамически находит релевантные видео из огромного корпуса, используя как визуальные, так и текстовые данные, и интегрирует их для генерации точных и детализированных ответов.
Исследователи использовали двухэтапную архитектуру: на этапе retrieval система ищет видео по мультимодальным эмбеддингам (кадры и транскрипты), а на этапе generation извлеченные данные объединяются с исходным запросом и подаются в Large Video Language Model (LVLM). Если субтитры отсутствуют, они автоматически генерируются с помощью ASR (например, Whisper).
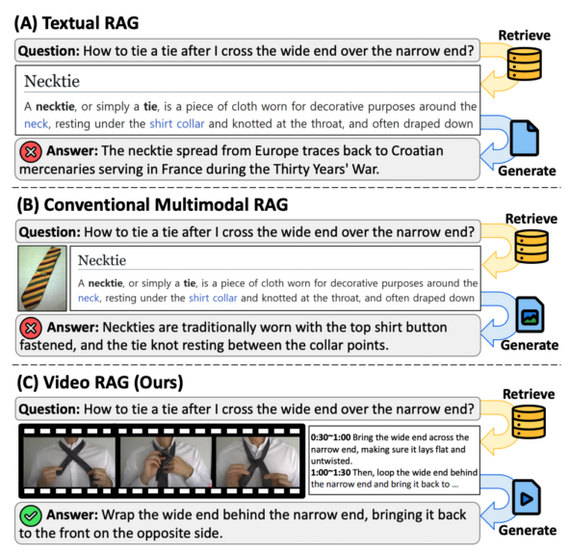
(A) Текстовый RAG извлекает релевантные документы из текстового корпуса. (B) Мультимодальный RAG расширяет извлечение, включая статические изображения. (C) VIDEO-RAG дополнительно использует видео как источник внешних знаний.
В экспериментах использовались вопросы из набора WikiHowQA, а видеокорпус — из HowTo100M. Показано, что даже только транскрипты дают преимущество по сравнению с классическим текстовым RAG, а добавление визуальной составляющей еще больше улучшает результат.
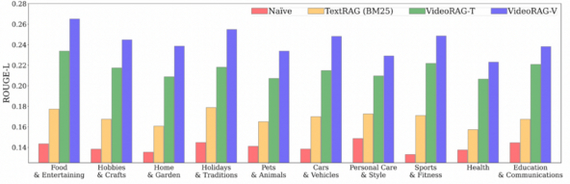
Разбивка производительности различных моделей по 10 категориям.
Одно из ключевых затруднений — большой объем и разнообразие видеоматериалов. Видео могут включать множество динамичных сцен, содержать шум, переходы кадров и разную скорость смены контента. Для улучшения требуется оптимизация мультимодальных эмбеддингов и индексов, а также более продуманная стратегия отбора кадров.
VideoRAG значительно повышает точность и релевантность ответов в задачах, где важны пошаговые инструкции и наглядность, по сравнению с традиционными методами работы с текстом за счет видеомодальности. Ждем RAG-системы и в других модальностях.
Исследователи из AMD и института Джона Хопкинса разработали автономную лабораторию ИИ-агентов, которая покрывает весь цикл научного исследования в области машинного обучения: от обзора литературы до проведения экспериментов и составления отчета. Система помогает экономить время, автоматизируя рутинные задачи, при этом оставляя за исследователем возможность контроля и корректировки результатов.

Лаборатория агентов принимает исследовательскую идею и заметки, передаёт их через цепочку специализированных LLM-агентов и генерирует исследовательский отчет и репозиторий с кодом.
Система работает в три этапа:
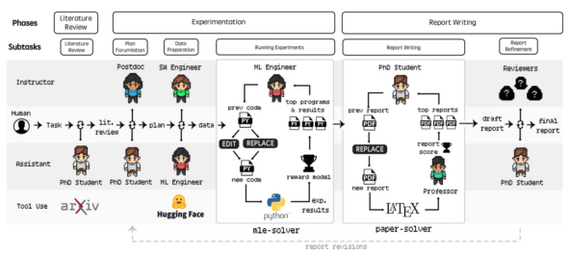
LLM-агенты проводят анализ литературы, планируют эксперименты, обрабатывают данные и интерпретируют результаты, mle-solver используется для экспериментов, а paper-solver для генерации отчетов.
1. Обзор литературы: агент ищет и отбирает релевантные статьи через API arXiv;
2. Эксперименты: формулируется план, подготавливаются данные и выполняются эксперименты с помощью модуля mle-solver, который автоматически пишет и дорабатывает код, ориентируясь на метрики.
3. Написание отчета: модуль paper-solver генерирует черновик в LaTeX, после чего проводится ревизия с участием человека.
Система может работать как автономно, так и в режиме «ко-пилота», когда человек направляет процесс.
В ходе эксперимента система автономно сгенерировала 15 статей по пяти темам, используя три разных LLM (gpt-4o, o1-mini, o1-preview). Десять аспирантов оценивали каждую статью по качеству эксперимента, отчета и полезности по шкале 1–5. Результаты показали, что o1-preview признана самой полезной (4.4/5) и демонстрирует лучшее качество отчета (3.4/5), однако чуть уступает o1-mini в экспериментальной части (2.9/5).
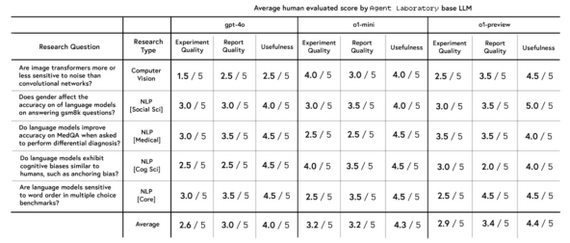
Средние оценки, выставленные аспирантами, для научных работ, сгенерированных лабораторией агентов в автономном режиме.
Конечно, ИИ-агенты все еще могут галлюцинировать, что ставит под сомнение достоверность экспериментов. Но, в целом, лаборатория ИИ-агентов показывает, что LLM-агенты могут существенно ускорить научный прогресс, выполняя рутинные задачи, что позволяет ученым сосредоточиться на своей работе. Приведенные в статье исследования наглядно демонстрируют, как стремительно развивается сфера ИИ. Современные методы в области ИИ позволяют создавать системы, способные не только решать сложнейшие задачи, но и эволюционировать, приближаясь к «человеческому» пониманию мира. Последние месяца обогащают теоретическую базу и открывают новые возможности для практического применения в робототехнике, внедрении ИИ в бизнес и научных исследованиях.
Вот такие интересные исследования вышли в январе. Не забудьте подписаться на мой Telegram-канал и использовать Dataist AI, чтобы всегда быть в курсе самых свежих новостей, обзоров и инсайтов в сфере ИИ. Оставайтесь на шаг впереди в этом быстро меняющемся мире технологий!
Показать полностью
24
Илон Маск хочет купить OpenAI

⚡️ Илон Маск ПОКУПАЕТ OpenAI — миллиардер вместе с инвесторами готов выкупить контрольный пакет компании за 100 МИЛЛИАРДОВ ДОЛЛАРОВ!
Он хочет снова получить контроль над разработчиками ChatGPT, потому что они в шаге от AGI — по его словам, их нужно вернуть в русло открытого кода и отказаться от коммерческих целей.
Альтман уже отказался от оффера и предложил Маску «продать Твиттер за $9 млрд» — в ответ Маск назвал его мошенником и Скам Альтманом.
Решение должен принять совет директоров. Будущее ChatGPT решается в прямом эфире!
Показать полностью
1
Нейросеть переведёт любой фильм
Нейросеть переведёт любой фильм или видео прямо во время просмотра.
Релизнулась бесплатная тулза, которая решает все языковые барьеры:
— Переводит во время просмотра — работает с YouTube, скачанными фильмами, аудиокнигами и MP3.
— Поддержка 100+ языков.
— Переводит готовые субтитры на 34 языка.
— Поиск слов — полезно для изучающих языки.
— Двойные субтитры — оригинальный текст + перевод одновременно.
— Саммари всех субтитров — превращает их в удобный текст, идеальный для конспектов.
— Бесплатно.
Показать полностью

Сравнил 3 ИИ
Chatgpt, Deepseek и Gemini от Гугл.
Так вот, незнаю почему так сильно нахваливают Deepseek. У него ответы ограничены. Я как фанат Джима Керри задал всем вопрос. Перечисли всё его фильмы по годам.
Chatgpt у меня базовая версия, перечислила фильмы с 1994 года, тогда он стал мега звездой. Все фильмы были с 2 названиями.
Deepseek перечислил ещё больше фильмов начиная с 80-х. Но там было только название фильма и год, названия были на английском языке.
А вот Gemini удивил. Мало того он всё написал на русском, он ещё больше фильмов перечислил, включаю его шоу, благодаря которому он попал в кино.
Буду даьльше вести наблюдение).
Ps. Я хотел проверить возможности ИИ и задавал вопросы на казахском языке. В отличии от двух, Gemini не знает казахский язык. Ниже результаты вопроса.
Chatgpt:
1994 – Ace Ventura: Pet Detective (Эйс Вентура: Жануарлар детективі)
1994 – The Mask (Маска)
1994 – Dumb and Dumber (Тақсырай мен Тоңғақ)
1995 – Batman Forever (Бэтмен мәңгі) – Риддлер рөлінде
1995 – Ace Ventura: When Nature Calls (Эйс Вентура: Табиғат шақырады)
1996 – The Cable Guy (Кабельші)
1997 – Liar Liar (Өтірікші өтірікші)
1998 – The Truman Show (Трумэн шоуы)
1999 – Man on the Moon (Айдағы адам)
2000 жылдар:
2000 – Me, Myself & Irene (Мен, мен және Ирэн)
2000 – How the Grinch Stole Christmas (Гринч Рождествоны қалай ұрлады)
2001 – The Majestic (Мажестик)
2003 – Bruce Almighty (Брюс Құдіретті)
2004 – Eternal Sunshine of the Spotless Mind (Сананың мәңгілік шуағы)
2005 – Lemony Snicket's A Series of Unfortunate Events (Лемони Сникет: Бақытсыз оқиғалар сериясы)
2005 – Fun with Dick and Jane (Дик пен Джейннің көңілді өмірі)
2007 – The Number 23 (23 саны)
2008 – Yes Man (Әрқашан "иә" де)
2009 – I Love You Phillip Morris (Сені сүйем, Филлип Моррис)
2009 – A Christmas Carol (Рождестволық ән) – анимациялық
2010 жылдар:
2011 – Mr. Popper’s Penguins (Мистер Поппердің пингвиндері)
2013 – Kick-Ass 2 (Кик-Ас 2)
2014 – Dumb and Dumber To (Тақсырай мен Тоңғақ 2)
2016 – The Bad Batch (Жаман топ)
2017 – Dark Crimes (Қара қылмыс)
2020 жылдар:
2020 – Sonic the Hedgehog (Соник кірпі) – Доктор Роботник рөлінде
2022 – Sonic the Hedgehog 2 (Соник кірпі 2)
Deepseek
Джим Керридің фильмографиясы өте кең. Міне, оның ең танымал фильмдерінің тізімі (хронологиялық тәртіпте):
1. **1984** - **Finders Keepers**
2. **1986** - **Once Bitten**
3. **1988** - **Peggy Sue Got Married**
4. **1989** - **Earth Girls Are Easy**
5. **1991** - **High Strung**
6. **1994** - **Ace Ventura: Pet Detective**
7. **1994** - **The Mask**
8. **1994** - **Dumb and Dumber**
9. **1995** - **Ace Ventura: When Nature Calls**
10. **1995** - **Batman Forever**
11. **1996** - **The Cable Guy**
12. **1997** - **Liar Liar**
13. **1998** - **The Truman Show**
14. **1999** - **Man on the Moon**
15. **2000** - **Me, Myself & Irene**
16. **2000** - **How the Grinch Stole Christmas**
17. **2001** - **The Majestic**
18. **2003** - **Bruce Almighty**
19. **2004** - **Eternal Sunshine of the Spotless Mind**
20. **2004** - **Lemony Snicket's A Series of Unfortunate Events**
21. **2005** - **Fun with Dick and Jane**
22. **2007** - **The Number 23**
23. **2008** - **Horton Hears a Who!**
24. **2008** - **Yes Man**
25. **2009** - **I Love You Phillip Morris**
26. **2011** - **Mr. Popper's Penguins**
27. **2013** - **The Incredible Burt Wonderstone**
28. **2013** - **Kick-Ass 2**
29. **2014** - **Dumb and Dumber To**
30. **2016** - **The Bad Batch**
31. **2017** - **Jim & Andy: The Great Beyond**
32. **2020** - **Sonic the Hedgehog**
33. **2022** - **Sonic the Hedgehog 2**
Егер нақты фильм туралы қосымша ақпарат қажет болса, айтыңыз! 😊
Gemini
Джим Керри — известный американский актёр, комик, сценарист и продюсер. За свою карьеру он снялся во многих фильмах, которые стали популярными и любимыми зрителями. Вот список некоторых из них по годам:
* 1981 — «Резиновое лицо»
* 1983 — «Семейный час секса и насилия», «Всё в хорошем вкусе», «Гора Куппер»
* 1984 — «Буффало Билл», «Чур, моё!», «Утиная фабрика»
* 1985 — «Однажды укушенный»
* 1986 — «Пегги Сью вышла замуж»
* 1988 — «Смертельный список», «Земные девушки легко доступны», «Майк Хаммер: Цепь убийств»
* 1989 — «Розовый кадиллак»
* 1990-1994 — «В живом цвете»
* 1991 — «Нервы на пределе»
* 1992 — «Крошечный паучок», «Жизнь на Мэйпл-Драйв»
* 1993 — «Эйс Вентура: Розыск домашних животных»
* 1994 — «Тупой и ещё тупее», «Маска»
* 1995 — «Эйс Вентура 2: Когда зовёт природа», «Бэтмен навсегда»
* 1996 — «Кабельщик»
* 1997 — «Лжец, лжец»
* 1998 — «Саймон Бирч», «Шоу Трумана»
* 1999 — «Человек на Луне»
* 2000 — «Гринч — похититель Рождества», «Я, снова я и Ирэн»
* 2001 — «Мажестик»
* 2003 — «Брюс Всемогущий»
* 2004 — «Лемони Сникет: 33 несчастья», «Вечное сияние чистого разума»
* 2005 — «Аферисты: Дик и Джейн развлекаются»
* 2007 — «Роковое число 23»
* 2008 — «Всегда говори „да“», «Хортон»
* 2009 — «Я люблю тебя, Филлип Моррис», «Рождественская история», «Под морем в 3D»
* 2010 — «Президентское воссоединение»
* 2011 — «Офис», «Пингвины мистера Поппера», «Пьяная история»
* 2012 — «Студия 30»
* 2013 — «Невероятный Бёрт Уандерстоун», «Пипец 2», «Телеведущий 2: И снова здравствуйте»
* 2014 — «Тупой и ещё тупее 2»
* 2016 — «Настоящее преступление», «Плохая партия»
* 2017 — «Джим и Энди: Другой мир»
* 2018-2020 — «Шучу»
* 2020 — «Соник в кино»
* 2021 — «Космический джем: Новое поколение»
* 2022 — «Соник 2 в кино»
Это далеко не полный список фильмов с Джимом Керри, но в нем представлены многие из его наиболее известных и популярных работ.
Показать полностью

Инструкция по подключению локальной нейросети (DeepSeek, Phi-2) от Ollama к Obsidian [Нейронка без интернета]

Установка и настройка Ollama и создание онлайн версии нейросети для вашего компьютера.
Интеграция локальных языковых моделей, таких как DeepSeek или Phi-2, с помощью платформы Ollama в вашу систему управления заметками Obsidian на Mac с чипом M1 позволяет использовать возможности искусственного интеллекта для автоматизации задач, генерации контента и анализа данных.
Что вам понадобится
• Mac с чипом M1: устройство с установленной macOS 11 Big Sur или новее.
• Obsidian: установленное приложение для управления заметками.
• Ollama: локальная среда для запуска языковых моделей.
• DeepSeek или Phi-2: выбранная вами модель, доступная через Ollama.
Шаг 1: Установка и настройка Ollama на Mac M1
1. Скачайте Ollama:
• Перейдите на официальный сайт Ollama.
• Нажмите “Download for macOS” и сохраните установочный файл.
2. Установите Ollama:
• Откройте загруженный файл и следуйте инструкциям на экране для установки Ollama.
3. Проверьте успешность установки:
• Откройте “Терминал” и введите команду:
ollama --version
• Убедитесь, что версия Ollama отображается корректно.
Шаг 2: Загрузка модели с малой квантовкой
Для эффективного использования ресурсов Mac M1 рекомендуется использовать модели с малой квантовкой (например, Q4_0), которые требуют меньше оперативной памяти и вычислительных мощностей.
1. Выберите модель:
• Посетите библиотеку моделей Ollama и найдите модель, которая поддерживает нужную квантовку.
2. Скачайте модель:
• В “Терминале” выполните команду:
ollama pull {название_модели}:{квантовка}
Замените {название_модели} на выбранную модель, а {квантовка} — на тип квантовки (например, Q4_0).
Пример для модели Phi-2 с квантовкой Q4_0:
ollama pull phi-2:Q4_0
Эта команда загрузит выбранную модель на ваш компьютер главное смотреть правильное название на сайте Ollama.
Шаг 3: Настройка Obsidian для работы с Ollama
1. Установите плагин Local GPT в Obsidian:
• Откройте Obsidian и перейдите в “Настройки” > “Плагины”.
• Включите опцию “Разрешить установку плагинов из сторонних источников”.
• Нажмите “Обзор” и найдите плагин “Local GPT”.
• Установите и активируйте плагин.
2. Настройте плагин для работы с Ollama:
• Перейдите в настройки плагина “Local GPT”.
• Укажите URL API Ollama: http://localhost:11434 - если потребуется, обычно нужно просто выбрать модель и все.
• Выберите ранее загруженную модель (например, DeepSeek или Phi-2).
Шаг 4: Настройка горячих клавиш для действий нейросети
1. Откройте настройки Obsidian:
• Перейдите в “Настройки” > “Сочетания клавиш”.
2. Найдите команды плагина Local GPT:
• В списке команд найдите действия, связанные с плагином “Local GPT” (например, “Выполнить запрос к модели”).
3. Назначьте горячие клавиши:
• Выберите нужную команду и нажмите “Установить горячую клавишу”.
• Нажмите желаемое сочетание клавиш (например, Ctrl + Alt + G) для быстрого доступа к функции.
Это позволит вам быстро взаимодействовать с нейросетью непосредственно из Obsidian, повышая эффективность работы.
Шаг 5: Использование Obsidian с интегрированной нейросетью
1. Создайте новую заметку в Obsidian.
2. Вставьте запрос или команду, которую хотите выполнить с помощью модели.
3. Используйте назначенные горячие клавиши или функции плагина Local GPT для отправки запроса и получения ответа от модели.
Шаг 6: Оптимизация и тестирование
1. Настройте параметры модели в плагине для оптимального баланса между скоростью и качеством ответов.
2. Проведите тестирование интеграции, чтобы убедиться в корректной работе системы.
Заключение
Интеграция локальных языковых моделей с Obsidian через Ollama на Mac M1 позволяет расширить возможности управления заметками, добавляя функции искусственного интеллекта для автоматизации и улучшения рабочего процесса.
Показать полностью