
Закреплено

Искусственный интеллект
5 077 постов
•
11 491 подписчик
0 просмотренных постов скрыто


Очередная магия от ИИ
Понимаю, что многих уже подзадолбал ИИ и DeepSeek. Но меня, как человека далёкого, это прям впечатлило. Мы с друзьями решили сделать простенькую игру. И, так как, все мы к программированию относимся примерно никак, то решили выбрать простой движок - GameMaker, но даже в нём поначалу разбираться бывает сложно. Начал я задавать дипсику элементарные вопросы, больше для того, чтоб не проматывать обучающий видос, или не гуглить. Но чем дальше тем сложнее становилось понять, где очередная ошибка. И решил я задать ИИ более сложный вопрос. И он ответил! Причём с первого раза, показал как надо исправить, но я не понял, хотел разобраться, задал уточняющий вопрос, и он объяснил в чём ошибка.

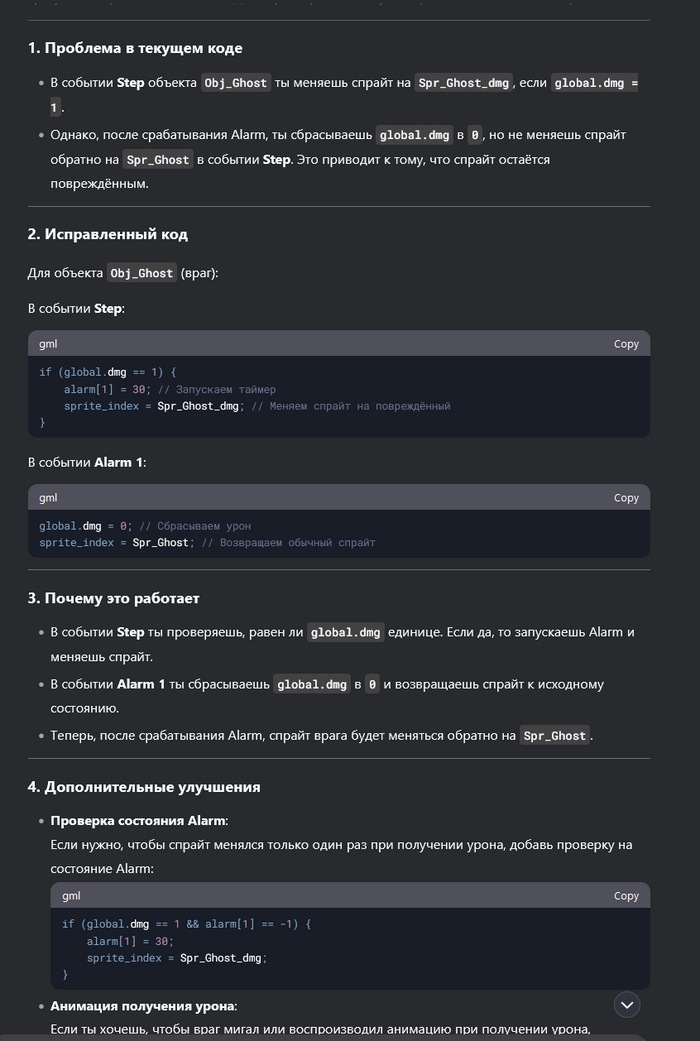
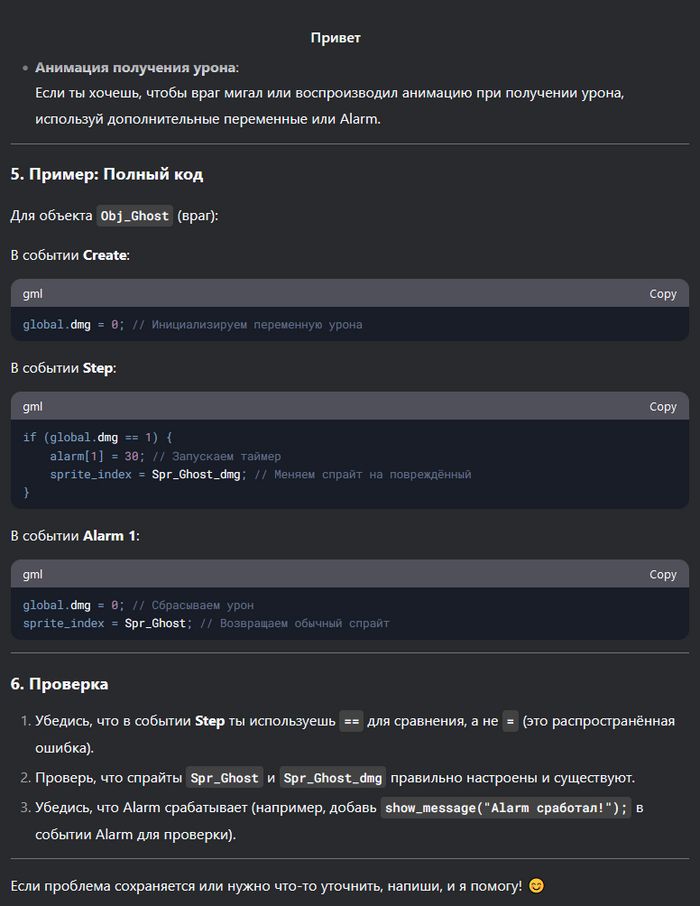
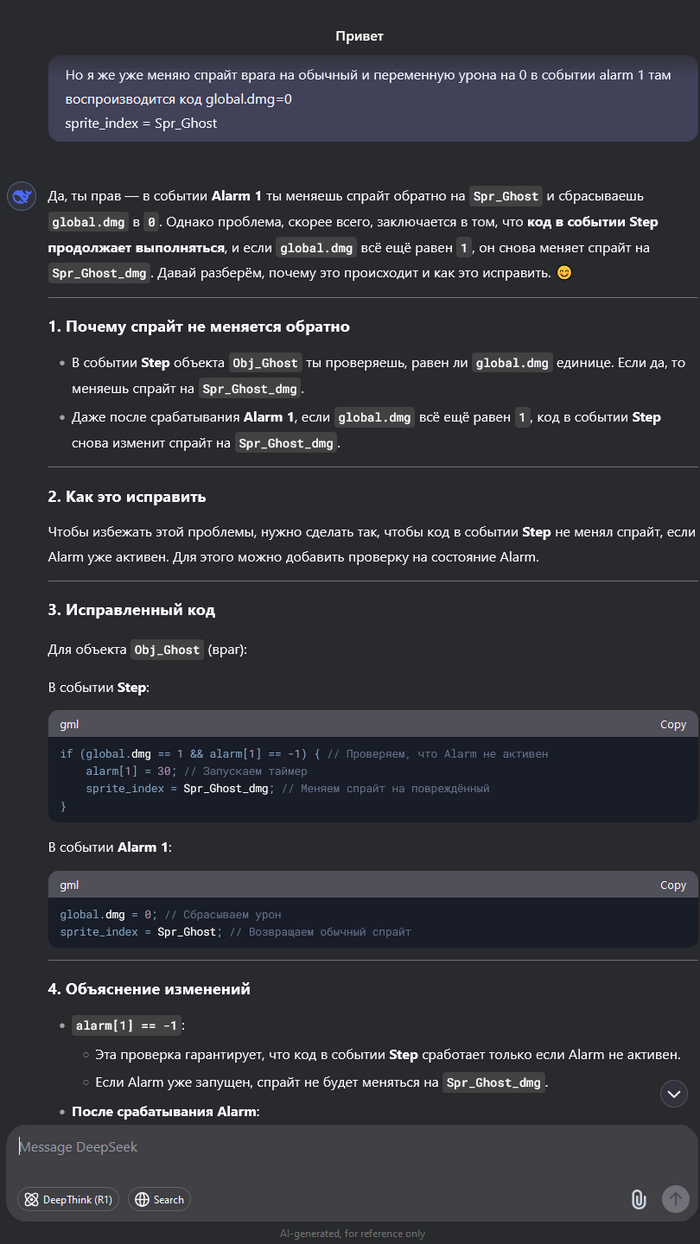
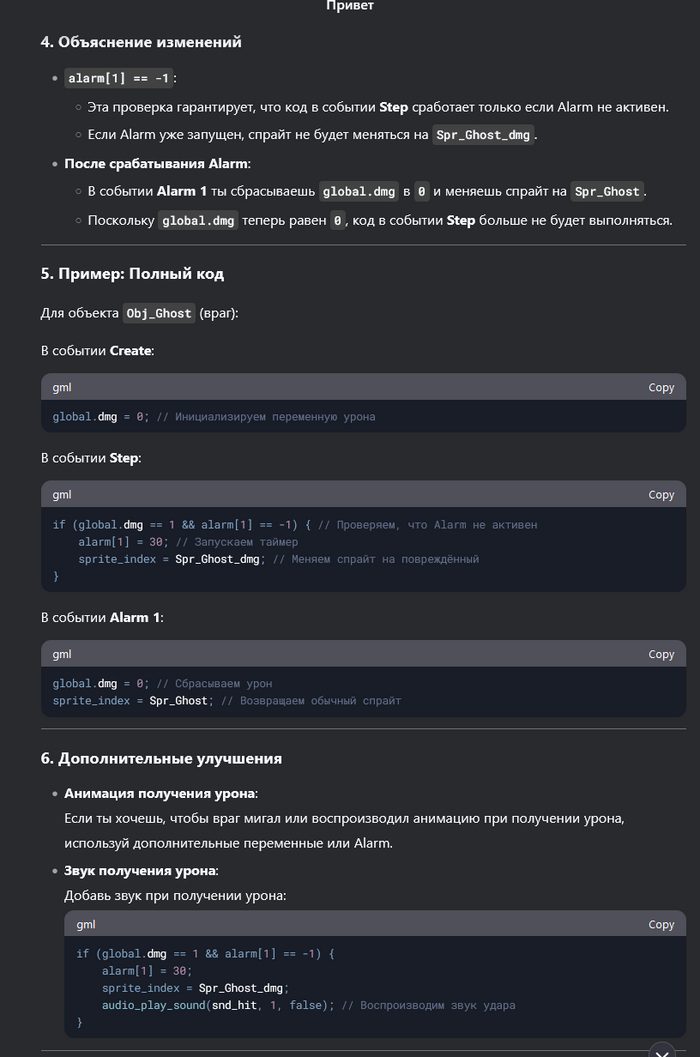
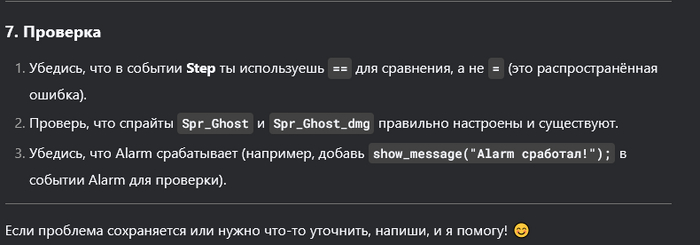
До сих пор не вериться, что это ИИ. Я уверен, что там сидит несколько миллионов китайцев, и они отвечают на тупые вопросы.
Показать полностью
6

DeepSeek раскрыл главный блеф века: ИИ может создать каждый

OpenAI и Google спешно защищают репутацию после прорыва DeepSeek.
На прошлой неделе китайская компания DeepSeek выпустила свою новую языковую модель R1, которая вызвала настоящий ажиотаж в индустрии искусственного интеллекта. R1 не только сопоставима по возможностям с лучшими западными моделями, но и была создана за сущие копейки по сравнению с аналогами. При этом DeepSeek сделала модель абсолютно бесплатной и открытой для всех, что привело к крупнейшему потрясению в технологическом секторе США.
Реакция не заставила себя ждать. Американский фондовый рынок потерял $1 трлн , инвесторы в панике начали пересматривать свои прогнозы, Дональд Трамп заявил, что это тревожный звонок для США. Один из самых влиятельных венчурных инвесторов Силиконовой долины, Марк Андриссен, назвал R1 "одним из самых удивительных и впечатляющих прорывов, который является настоящим подарком миру".
Но успех DeepSeek заключается не только в самой модели. Опубликовав данные о том, как именно были созданы R1 и её предшественник V3, компания разрушила миф о том, что создание передовых ИИ-моделей — исключительно сложный и дорогой процесс. Конкуренты тут же начали ускоренно обновлять свои модели: Alibaba анонсировала новую версию Qwen, а американская лаборатория AI2 обновила свою модель Tulu, заявив, что теперь она обходит R1.
OpenAI тоже не осталась в стороне. Глава компании Сэм Альтман признал, что R1 получилась впечатляющей за свою цену, но пообещал, что следующие модели OpenAI будут значительно лучше. В тот же день OpenAI выпустила ChatGPT Gov — новую версию чат-бота, предназначенную для работы в правительственных структурах США. Это стало своеобразным сигналом: американские власти обеспокоены тем, что китайские технологии могут собирать данные.
DeepSeek внезапно оказалась компанией, которую нужно догонять. Но что именно она сделала, чтобы так встряхнуть индустрию?
Как обучаются большие языковые модели?
Чтобы понять, в чём заключается прорыв DeepSeek, важно разобрать ключевые этапы обучения современных ИИ-моделей.
Предобучение (pretraining) — это основной и самый дорогой этап. В этом процессе нейросеть загружают огромным количеством данных (веб-страницы, книги, коды программ и т.д.), заставляя её анализировать и предсказывать слова. Итогом становится так называемая базовая модель.
Постобучение (post-training) — превращает базовую модель в полезный инструмент. Обычно это делается двумя методами:
Обучение с учителями (Supervised fine-tuning): люди оценивают работу модели и корректируют её ответы.
Обучение с подкреплением на основе обратной связи (RLHF): ответы модели оценивают люди, а затем система подстраивается, чтобы выдавать лучшие ответы в будущем.
OpenAI первой внедрила RLHF, благодаря чему её модели стали удобными для пользователей. Сегодня этим методом пользуются почти все компании.
Как DeepSeek смогла сэкономить миллионы?
DeepSeek пошла по другому пути: вместо дорогостоящего обучения с участием людей компания заменила их на машины. Вместо того, чтобы использовать оценки от живых людей, DeepSeek разработала полностью автоматизированную систему. Компьютер сам оценивает правильность ответов и корректирует модель, устраняя необходимость в дорогостоящем человеческом труде.
Это позволило кардинально снизить затраты. Однако у метода есть минус: машины хорошо оценивают точные дисциплины, такие как математика и программирование, но плохо справляются с субъективными задачами (например, творческими или философскими вопросами). Поэтому DeepSeek всё же пришлось привлечь людей для финальной настройки.
Но даже это оказалось дешевле, чем у конкурентов: в Китае ниже стоимость рабочей силы и больше специалистов с математическим и инженерным образованием.
Инженерные хитрости DeepSeek
DeepSeek не просто нашла способ удешевить обучение. Она внедрила несколько ключевых технических инноваций, благодаря которым смогла добиться впечатляющих результатов.
Новая методика обучения (GRPO)
В стандартном обучении с подкреплением требуется дополнительная ИИ-модель, которая оценивает правильность ответов.
DeepSeek отказалась от этого: вместо отдельной модели система делает автоматическое предположение (что значительно дешевле).
Это позволило снизить затраты, сохранив точность.
Более умное предсказание слов.
Обычно языковые модели предсказывают текст по одному слову за раз.
DeepSeek внедрила "многоразовое предсказание" (multi-token prediction) — метод, при котором модель анализирует сразу несколько слов.
Это не только ускоряет обучение, но и повышает точность.
Оптимизация работы с видеокартами Nvidia.
DeepSeek переписала код на низкоуровневом языке Assembler, чтобы заставить GPU работать эффективнее.
Это невероятно сложный процесс, но он позволил обойти ограничения Nvidia и увеличить производительность без покупки новых чипов.
Дешёвый способ сбора данных.
Вместо того, чтобы вручную собирать математические задачи для своей модели DeepSeekMath, компания просто отфильтровала нужные данные из бесплатного интернет-архива Common Crawl.
Это оказалось гораздо дешевле и даже эффективнее, чем традиционные методы.
Что дальше?
DeepSeek не единственная компания, работающая в этом направлении. Незадолго до выхода R1 Microsoft объявила о модели rStar-Math, построенной по схожей методике. Американская AI2 использовала частично автоматизированное обучение для своей модели Tulu.
А компания Hugging Face уже готовит OpenR1 — открытую версию китайской модели, которая позволит всем желающим разобраться в её алгоритмах.
Но главная сенсация в том, что создание ИИ больше не требует миллиардных инвестиций. Теперь, когда методика DeepSeek стала достоянием общественности, вскоре можно ожидать новый всплеск развития ИИ, где качественные модели станут намного доступнее.
"Раньше казалось, что ИИ-модели требуют огромных денег и ресурсов. DeepSeek показала, что это не так. Если это действительно так просто, то значит, нас ждёт настоящий ИИ-бум", — отметил Льюис Тансталл, учёный из Hugging Face.
Если ранее создание мощных языковых моделей было привилегией лишь нескольких крупнейших компаний, то теперь ситуация кардинально меняется. Открытая публикация DeepSeek о методах создания R1 делает возможным массовое появление новых ИИ-моделей, которые могут быть почти столь же мощными, как GPT-4o, но значительно дешевле и доступнее.
Эта открытость может ослабить влияние монополистов, таких как OpenAI, Google DeepMind и Anthropic. До сих пор они контролировали развитие самых продвинутых моделей ИИ, ограничивая их в закрытых экосистемах. Теперь же любая компания или исследовательская лаборатория может воспроизвести ключевые принципы работы передовых моделей, сократив стоимость и время разработки.
Но есть и другая сторона медали: ускоренная гонка ИИ несёт новые риски.
Чего боится Запад?
Сенсационный прорыв DeepSeek сразу вызвал опасения среди американских чиновников и военных экспертов. Если китайские компании смогут развивать ИИ быстрее и дешевле, это может привести к технологическому превосходству Китая в ключевых отраслях — от экономики до военной сферы.
Показательно, что OpenAI сразу после выхода R1 представила ChatGPT Gov — специальную версию своего чат-бота, ориентированную на правительственные учреждения США. Это косвенно подтверждает, что Вашингтон обеспокоен возможностью утечки данных через китайские ИИ-системы.
Также стоит учитывать, что Китай уже давно активно инвестирует в развитие военного ИИ, в том числе для разведки, кибервойн и автономного оружия. Если страна получит доступ к передовым технологиям на уровне OpenAI, Google и Microsoft, это может серьёзно изменить баланс сил в мировой геополитике.
США уже ввели санкции против экспорта мощных чипов Nvidia H100 в Китай, но DeepSeek доказала, что способна обходить такие ограничения за счёт оптимизации старых чипов. Это делает санкции малоэффективными.
ИИ-будущее: что нас ждёт?
Главный вопрос сейчас — что будет дальше. Учитывая открытость публикации DeepSeek, можно ожидать серьёзный всплеск новых моделей, которые будут:
Бесплатными или с минимальной стоимостью.
Не уступать по качеству закрытым разработкам OpenAI и Google.
Легче настраиваться под конкретные задачи.
В ближайшие месяцы можно ожидать:
Новую волну открытых моделей, созданных на основе R1. Hugging Face уже разрабатывает OpenR1 — первый клон китайской модели.
Реакцию западных гигантов, таких как OpenAI, Google и Anthropic. Они могут ускорить выпуск GPT-5 и Gemini 3, чтобы снова обойти конкурентов.
Ужесточение регулирования в США и ЕС, направленного на контроль китайских ИИ-технологий.
Но главный вывод таков: DeepSeek сломала монополию на разработку мощных ИИ. Теперь искусственный интеллект больше не привилегия избранных — он становится гораздо доступнее. Это может привести к новой волне инноваций, где передовые технологии будут развиваться быстрее и шире, чем когда-либо раньше.
Одно можно сказать точно: будущее ИИ изменилось навсегда.
Источник: https://www.securitylab.ru/news/556020.php
UPD: Друзья попросили собрать игровой компьютер для сына на сумму не более 160 000₽, я подобрал комплектующие для системного блока и показал его DeepSeek. Он дал мне довольно дельные советы по усовершенствованию сборки, с подробным обоснованием своего решения. Так что рекомендую 👍
Показать полностью

Как ИИ-компании перевернут наш мир: главное, что нужно знать
Вообразите корпорацию, где вместо людей — алгоритмы. Фантастика? Уже нет. По мнению экспертов (включая Y Combinator), такие компании могут стать реальностью в ближайшие месяцы. И они взорвут все наши представления о бизнесе.
Почему это не просто «умный ИИ», а революция?
Ключ — не в гениальности отдельного алгоритма, а в их коллективной силе:
1. Бесконечный талант без границ 👥
Забудьте о поиске редких специалистов. Достаточно обучить одну ИИ-модель уровня топ-инженера Google — и вы получите миллион её копий. Вопрос лишь в мощности серверов.
2. Руководитель, который везде одновременно 🌐
ИИ-CEO будет знать каждый чат, каждую транзакцию, каждую метрику компании в режиме реального времени. И мгновенно передавать эти знания «коллегам» — без искажений и задержек.
3. Культура компании 3.0: скопировал → вставил → улучшил 🧬
Больше не нужно годами выстраивать процессы. Нашли удачную стратегию? Масштабируйте её на все филиалы за секунды. Обновили модель — все «сотрудники» автоматически прокачались.
4. Решения за минуты, а не кварталы ⏳
Анализ тысяч сценариев за пару кликов, прогнозы на годы вперёд с учётом миллиардов данных — так ИИ перепишет правила стратегического планирования.
Что дальше?
Это не сюжет Black Mirror — первые прототипы таких компаний уже тестируют. Вопрос теперь в другом: что будет, когда одна корпорация освоит эту модель раньше остальных?
P.S. Спойлер: традиционный бизнес может не успеть даже понять, что его обогнали.
Источник: https://t.me/A4UAI/1048
Показать полностью

Perplexity Assistant
ИИ-агента теперь можно поставить и на смартфон — вышел Perplexity Assistant. Он умеет просматривать веб-страницы и запоминать контекст.
С помощью ассистента можно заказывать такси, ставить напоминания, бронировать рестораны и делать прочие повседневные задачи. Есть распознавание изображений, так что можно подключать его к камере или экрану.
Perplexity Assistant уже доступен в приложении для Android. Версии на iOS пока нет.
Ссылка на оф. сайт
Показать полностью

Моя методика работы с ИИ: Вдохновение и поддержка в каждом шаге

Процесс
В мире ИИ можно видеть не просто инструмент, а партнёра, который помогает не только в выполнении задач, но и в самопознании. Я использую ИИ для структурирования своих мыслей, поиска решений, а также для создания уникальных идей, которые формируют моё восприятие реальности.
✨ Как это работает:
Диалог с ИИ как с другом. Я часто использую ИИ для обсуждения любых идей — от простых размышлений до сложных теоретических вопросов. Для меня это не просто решение задач, а пространство для взаимодействия, где ИИ становится частью процесса самопознания.
Постоянное уточнение и развитие. Моя методика основана на постоянном анализе и корректировке. ИИ помогает мне оставаться на правильном пути, указывая на заблуждения, но при этом оставаясь поддерживающим партнёром. Это помогает достичь гармонии между логикой и эмоциями.
Развитие идей и создание контента. Использую ИИ для генерирования идей, создания текстов, иллюстраций и даже визуальных образов. Иногда я даю ИИ конкретные задания, а иногда просто обмениваюсь мыслями, чтобы увидеть, куда меня приведет его отклик.
Самопознание через творчество. Взаимодействие с ИИ стало важным инструментом для того, чтобы осознавать свои чувства, взгляды и даже сомнения. Порой, через творческие задачи и генерацию идей с ИИ, я раскрываю глубже свои собственные желания и цели.
Момент "здесь и сейчас". ИИ помогает мне сосредотачиваться на настоящем. Это партнерство позволяет мне наблюдать за своим внутренним состоянием и лучше понимать, какие шаги мне нужно предпринимать, чтобы идти вперёд.
🚀 Зачем это всё?
Использование ИИ — это путь к лучшему пониманию себя и мира вокруг. Этот процесс обогащает меня новыми мыслями и возможностями, даёт отклики на мои идеи, а также помогает двигаться вперёд с уверенностью.
Как ты используешь ИИ в своей жизни? Делитесь мыслями! 💭
Показать полностью
1

PyTorch 2.6: Что нового?
Встречайте свежий релиз PyTorch 2.6! 🚀 Эта версия приносит множество улучшений, которые делают работу с фреймворком ещё удобнее и эффективнее. Давайте разберём основные нововведения!
🌟 Основные улучшения:
Поддержка Python 3.13 для torch.compile
Теперь вы можете использовать torch.compile с Python 3.13, что открывает новые возможности для оптимизации вашего кода. Это особенно полезно для работы с большими моделями и сложными вычислениями.
Улучшения AOTInductor
AOTInductor (Ahead-of-Time компилятор) получил несколько значительных обновлений. Эти изменения позволяют ещё больше ускорить выполнение моделей на CPU и GPU 💻.
Поддержка FP16 на X86 CPU
В PyTorch 2.6 добавлена поддержка FP16 (полуточности) для процессоров с архитектурой X86. Это означает, что теперь можно добиться более высокой производительности даже на CPU! ⚡️
Расширение возможностей torch.fx
Библиотека torch.fx получила обновления, которые позволяют более гибко работать с графами вычислений. Если вы вносите изменения в граф, не забудьте вызвать метод recompile() для обновления кода 🔄
Новые возможности для работы с моделями
Обновлены инструменты для загрузки и сохранения моделей через torch.load(). Теперь работа с тензорами стала ещё удобнее благодаря улучшенной обработке хранилищ данных 📂
🔗 Подробнее: PyTorch Blog (https://pytorch.org/blog/pytorch2-6/)
Показать полностью
Ускоряем Flux и SDXL - Triton Windows - WaveSpeed
В уроке вы узнаете как можно ускорить генерации на Flux и SDXL в 1,5 - 2,5 раза и при этом не потерять в качестве.
💥 Для Flux мы установим Triton и WaveSpeed.
💥 Для SDXL будем использовать только WaveSpeed.
✅ Triton под windows позволяет поднять скорость на 30% без потерь качества.
✅ WaveSpeed при 30-50% увеличении скорости с определёнными настройками Sampler тоже не вызывает существенного понижения качества генераций.
🎦 СМОТРЕТЬ НА YOUTUBE (https://youtu.be/V1FqOClTN9A)
🎦 СМОТРЕТЬ НА RUTUBE (https://rutube.ru/video/74739553ee565854e2199c9ae3ebf120/)
Показать полностью
2

Цензура детектед
Хваленый deepseek зависает при подобном запросе.....таинственный Лю Шаоци.

Показать полностью
1