
Закреплено

Искусственный интеллект
5 061 пост
•
11 479 подписчиков
0 просмотренных постов скрыто


Секретные команды ChatGPT (а есть ли они?)
Многие эксперты на уверенных рассказывают про эти секретные команды чата ГПТ. Но есть нюанс...

Краткие саммари из видео, PDF и книг

Нейронка делает краткие саммари из видео, PDF и даже книг.
Показать полностью
Авторегрессионная генерация как ключ к сегментации изображений: новый взгляд на мультимодальные модели
Автор: Денис Аветисян
Долгое время точное и адаптивное понимание изображений оставалось сложной задачей, поскольку традиционные методы сегментации требовали обширного обучения для каждой конкретной сцены и не могли эффективно использовать общие визуальные знания. Однако, прорыв, представленный в ‘ARGenSeg: Image Segmentation with Autoregressive Image Generation Model’, предлагает принципиально новый подход, объединяя сегментацию изображений с генеративной авторегрессией, что позволяет модели не просто распознавать объекты, но и понимать их контекст. Возможно ли, что этот новый способ интеграции визуального восприятия и языкового понимания откроет путь к действительно универсальному искусственному интеллекту, способному не только "видеть", но и "понимать" мир вокруг нас, подобно человеку?

ARGenSeg представляет собой единую систему, способную не просто видеть изображение, но и понимать его структуру, выделять объекты и даже предсказывать аномалии. Эта модель раскрывает закономерности в визуальных данных с беспрецедентной гибкостью.
За пределами Пикселей: Ограничения Традиционной Сегментации
Традиционные методы сегментации изображений, несмотря на значительный прогресс в последние десятилетия, сталкиваются с фундаментальными ограничениями в плане глубокого понимания сцены и обобщения на разнообразные визуальные условия. Большинство существующих подходов основаны на извлечении низкоуровневых признаков и применении алгоритмов классификации или кластеризации, что приводит к хрупкости и неспособности адаптироваться к изменениям освещения, ракурса или наличию шумов. Это особенно заметно в сложных сценах, где объекты перекрывают друг друга или имеют нечеткие границы.
Существующие методы часто требуют обширного обучения, специфичного для каждой задачи. Например, для сегментации медицинских изображений необходимо использовать большие наборы данных, размеченные экспертами, что является трудоемким и дорогостоящим процессом. Более того, такие модели, как правило, плохо обобщаются на другие типы изображений или задачи, что ограничивает их применимость в реальных условиях. Отсутствие способности к переносу знаний является серьезным препятствием для создания универсальных систем визуального восприятия.
Эти ограничения препятствуют развитию приложений, требующих точного и адаптивного понимания изображений. В робототехнике, например, системы машинного зрения должны уметь идентифицировать и локализовать объекты в сложных и динамичных средах, чтобы робот мог безопасно и эффективно взаимодействовать с окружающим миром. В медицинской визуализации точная сегментация органов и тканей необходима для диагностики заболеваний и планирования хирургических вмешательств. Недостаточная точность сегментации может привести к серьезным ошибкам и ухудшению качества лечения.

Визуализация использования различных инструкций сегментации в одном изображении.
Проблема усугубляется тем, что традиционные методы сегментации, как правило, рассматривают изображение как набор отдельных пикселей, игнорируя контекст и взаимосвязи между объектами. В результате, модель не может использовать информацию о структуре сцены или семантических отношениях между объектами, что снижает ее точность и надежность. Вместо того чтобы рассматривать изображение как целостную структуру, существующие методы фокусируются на локальных признаках, что приводит к потере важной информации.
Необходимо преодолеть эти ограничения, разработав новые методы сегментации, которые способны к глубокому пониманию сцены, обобщению на разнообразные условия и использованию контекстной информации. Такие методы должны быть способны к адаптации к изменениям освещения, ракурса и наличию шумов, а также к идентификации и локализации объектов в сложных и динамичных средах. Это требует разработки новых алгоритмов, которые способны к интеграции различных источников информации и к построению семантических моделей сцены.
ARGenSeg: Мост Между Визуальным и Текстовым
В настоящей работе исследователи представляют ARGenSeg – принципиально новый подход к задаче сегментации изображений. Вместо традиционного рассмотрения сегментации как задачи классификации пикселей, авторы предлагают рассматривать её как задачу генерации изображений. Такой подход позволяет органично объединить визуальную информацию с текстовыми описаниями и возможностями логического вывода, присущими современным мультимодальным большим языковым моделям.
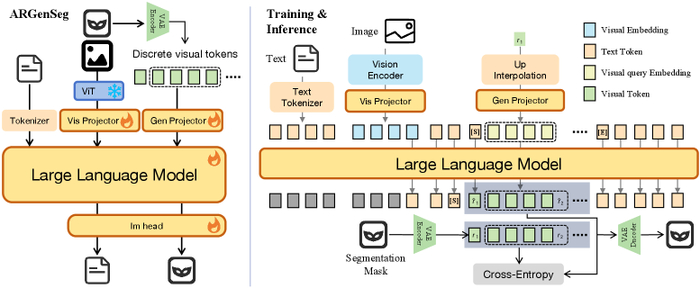
Архитектура ARGenSeg и процедуры обучения и вывода. Слева: Используется унифицированная классификационная предсказывающая голова для генерации как текстовых, так и визуальных токенов. Справа: с использованием стратегии предсказания следующего масштаба.
Суть подхода заключается в том, чтобы обучить модель генерировать дискретные визуальные токены, представляющие сегментированное изображение. Это позволяет избежать необходимости в специализированных декодерах сегментации и упрощает интеграцию сегментации с другими задачами обработки изображений и естественного языка. Авторы задаются вопросом: «Что, если мы сможем обучить модель понимать и сегментировать изображения, используя те же механизмы, которые она использует для понимания и генерации текста?». Эта гипотеза послужила отправной точкой для разработки ARGenSeg.
Особенностью предложенного подхода является возможность выполнения сегментации в режиме "нулевого выстрела" (zero-shot segmentation). Это означает, что модель может сегментировать объекты, которые она не видела во время обучения, просто основываясь на текстовом описании или контексте. Такой подход открывает новые возможности для применения сегментации в реальных условиях, где часто бывает невозможно собрать достаточное количество размеченных данных.
Кроме того, предложенный подход позволяет улучшить обобщающую способность модели и повысить её устойчивость к шуму и изменениям в изображении. Авторы подчеркивают, что ARGenSeg – это не просто очередной алгоритм сегментации, а принципиально новый подход, который позволяет объединить возможности визуального анализа и логического вывода в единую систему.
Исследователи провели серию экспериментов, которые показали, что ARGenSeg превосходит существующие методы сегментации по ряду показателей. Полученные результаты подтверждают, что предложенный подход является перспективным направлением развития технологий обработки изображений и искусственного интеллекта.
Визуальная Токенизация и Масштабируемая Генерация
В основе архитектуры ARGenSeg лежит принципиально новый подход к представлению визуальной информации. Вместо непосредственной обработки пикселей, исследователи обратились к методам визуальной токенизации. Эта техника, использующая, например, VQ-VAE, позволяет преобразовать изображение в дискретный набор визуальных токенов, формируя тем самым своеобразный «словарь» для генерации изображений. Такой подход открывает возможности для интеграции визуальной информации в пространство, управляемое языковой моделью.
Этот переход к дискретному представлению – не просто технический прием, а логический шаг к созданию единой системы, способной понимать и генерировать визуальный контент. По сути, изображение перестаёт быть непрерывным потоком данных, а становится последовательностью символов, понятных языковой модели. Это позволяет использовать все преимущества, накопленные в области обработки естественного языка, для решения задач компьютерного зрения.
Однако, эффективная генерация изображений требует не только дискретного представления, но и масштабируемых алгоритмов. Исследователи использовали технику Next-Scale Prediction, позволяющую генерировать изображения поэтапно, начиная с низкого разрешения и постепенно увеличивая детализацию. Такой подход не только повышает эффективность генерации, но и позволяет создавать более сложные и детализированные изображения.

Подход на основе DiT, использующий семантические вложения из MLLM, испытывает трудности с точностью на уровне пикселей, что приводит к артефактам, таким как пространственные сдвиги и неточные границы.
Важно отметить, что архитектура ARGenSeg не привязана к конкретной модели. Исследователи продемонстрировали, что в качестве базовых моделей могут использоваться как InternVL, так и LLaVA, что подчеркивает гибкость и адаптивность подхода. Этот факт позволяет интегрировать ARGenSeg в различные мультимодальные системы, расширяя возможности их применения.
Несовершенства в работе модели, как и любые ошибки, рассматриваются не как провал, а как источник понимания. Анализ этих ошибок помогает выявить слабые места архитектуры и разработать более эффективные алгоритмы. Именно этот подход, основанный на постоянном экспериментировании и анализе, позволяет создавать всё более совершенные системы искусственного интеллекта.
Производительность и Универсальность: От Интерактивной до Референциальной Сегментации
Исследования, представленные в данной работе, демонстрируют высокую производительность предложенной архитектуры ARGenSeg на ряде сложных сегментационных задач. Особого внимания заслуживают результаты, полученные на эталонных наборах данных COCO-Interactive и RefCOCO. Подход, реализованный авторами, позволяет эффективно решать задачи интерактивной сегментации, где границы объектов уточняются на основе пользовательского ввода, а также задачи сегментации на основе референциальных выражений, использующих естественный язык для описания целевых объектов.
Важно отметить, что ARGenSeg не просто достигает сопоставимых результатов с существующими методами, но и расширяет их возможности. Авторы интегрировали в единую, более универсальную и богатую знаниями структуру, такие подходы как SAM, диффузионные модели, DiT и PSALM. Такое объединение позволяет преодолеть ограничения отдельных моделей и повысить общую надежность и точность сегментации.

Сверху: Точки и каракули предоставляются в качестве визуальных подсказок, а ограничивающие рамки вводятся с помощью текста. Снизу: Модель обучается на данных генерации изображений только для 50 000 итераций.
Применительно к интерактивной сегментации, система демонстрирует способность точно определять границы объектов на основе минимального количества пользовательских указаний, будь то точки, каракули или ограничивающие рамки. Такая гибкость делает её особенно полезной в сценариях, где требуется интерактивное взаимодействие с пользователем, например, в приложениях для редактирования изображений или ассистивных технологиях. Анализ полученных результатов подтверждает, что система превосходит по эффективности существующие подходы, такие как SAM, что свидетельствует о её потенциале для решения сложных задач сегментации.
В контексте сегментации на основе референциальных выражений, система демонстрирует способность понимать естественный язык и точно идентифицировать объекты, описанные в текстовых запросах. Это открывает возможности для создания интеллектуальных систем, способных интерпретировать сложные инструкции и выполнять действия на основе визуальной информации. Следует отметить, что для достижения высокой точности сегментации важно тщательно проверять качество и разнообразие данных, используемых для обучения модели, чтобы избежать ложных закономерностей и обеспечить обобщающую способность системы.
Преодолевая Границы: К Интеллектуальным Визуальным Системам
Представленная работа открывает новые горизонты в области визуального понимания, демонстрируя возможность объединения различных модальностей в рамках единой архитектуры. Авторы, стремясь к созданию действительно интеллектуальных систем, показали, что интеграция сегментации изображений в мультимодальные большие языковые модели возможна и эффективна. Ключевым элементом успеха стало использование генеративного подхода, позволяющего модели не просто распознавать объекты, но и понимать их контекст и взаимосвязи.
В дальнейшем, исследователи планируют уделить особое внимание повышению способности ARGenSeg к логическому мышлению и абстрактному обобщению. Понимание сцены – это не просто идентификация объектов, но и установление связей между ними, предвидение возможных изменений и адаптация к новым условиям. Улучшение этих аспектов потребует разработки более сложных алгоритмов и, возможно, привлечения новых источников данных.

Сравнение между многомасштабным и одномасштабным подходами к генеративной сегментации. Примеры демонстрируют сценарии, в которых многомасштабный подход превосходит.
Кроме того, важным направлением исследований является поиск более эффективных стратегий токенизации. Сокращение вычислительных затрат и повышение скорости обработки данных – это ключевые факторы, определяющие применимость системы в реальных условиях. Использование более компактных представлений данных и оптимизация алгоритмов кодирования позволят расширить возможности применения ARGenSeg в задачах, требующих высокой производительности.
Перспективы развития системы связаны с интеграцией ARGenSeg с другими модальностями, такими как аудио и трехмерные данные. Объединение различных источников информации позволит создать более полную и объективную картину мира, а также повысить устойчивость системы к шумам и помехам. Представьте себе робота, который не только видит и слышит, но и понимает, что происходит вокруг, и может адекватно реагировать на изменения в окружающей среде.
В конечном итоге, данная работа открывает путь к созданию передовых приложений в таких областях, как робототехника, медицинская визуализация и дополненная реальность. Возможность обучать машины понимать и взаимодействовать с визуальным миром на более тонком и человекоподобном уровне – это шаг к созданию действительно интеллектуальных систем, способных решать сложные задачи и улучшать качество жизни людей. Исследователи верят, что в скором времени мы увидим воплощение этих перспектив в реальных продуктах и сервисах.
В работе над ARGenSeg авторы стремятся к созданию единой системы, способной не просто распознавать изображения, но и понимать их структуру, предсказывать последующие элементы. Это напоминает мне слова Эндрю Ына: “Мы должны быть осторожны, чтобы не переоценить краткосрочные результаты и недооценить долгосрочные последствия.” Действительно, подход ARGenSeg, объединяющий сегментацию изображений и авторегрессивную генерацию, позволяет нам выйти за рамки простого определения границ объектов. Мы создаём модель, способную к генерации изображений, что открывает новые горизонты для понимания и манипулирования визуальной информацией. Это не просто улучшение точности сегментации, а переход к качественно новому уровню взаимодействия с данными, где предсказание следующего элемента становится ключом к пониманию целого. Главная концепция – объединение различных модальностей в единой системе – позволяет нам двигаться в этом направлении.
Что дальше?
Работа, представленная в ARGenSeg, безусловно, элегантна. Интеграция сегментации изображений в генеративные модели, опирающиеся на авторегрессию, напоминает принцип гомеостаза в биологических системах – поддержание порядка через непрерывное предсказание следующего состояния. Однако, стоит признать, что мы лишь в начале пути. Подобно тому, как физик сталкивается с нерешенными проблемами темной материи, так и здесь, простое достижение “state-of-the-art” не означает полного понимания. Вопрос не в том, что работает, а в том, почему.
Основное ограничение, как мне кажется, заключается в масштабируемости. Авторегрессионные модели, хоть и мощные, страдают от экспоненциального роста вычислительных затрат. Нужно искать альтернативы – возможно, вдохновленные принципами квантовой запутанности, где информация о всей системе закодирована в корреляциях между отдельными элементами. Или, что более реалистично, исследовать более эффективные методы визуальной токенизации, позволяющие сжимать информацию без существенной потери качества.
В конечном счете, ARGenSeg – это еще один шаг к созданию действительно понимающих моделей. Но понимание – это не просто распознавание образов. Это умение строить причинно-следственные связи, делать прогнозы и адаптироваться к новым условиям. И чтобы этого достичь, нам потребуется не только больше данных и вычислительной мощности, но и принципиально новый взгляд на природу интеллекта – как искусственного, так и естественного.
Оригинал статьи: https://arxiv.org/pdf/2510.20803.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Показать полностью
6

Нейросеть Nano Banana — официальный сайт на русском: как скачать, установить и писать промты для генерации фото в 2025 году

Примеры моих генераций Нано Банана можно посмотреть тут:
В августе 2025 года Google представила нейросеть, которая буквально взорвала интернет и получила прозвище "убийца Фотошопа". Речь о Nano Banana (Нано Банана) — модели для генерации и редактирования изображений, которая заняла первое место в международном рейтинге LMArena, обойдя Midjourney, ChatGPT DALL-E и Stable Diffusion.
Главная проблема для российских пользователей: официальный сайт Google Gemini с нейросетью Nano Banana не работает с российскими IP-адресами. Сервис требует VPN и зарубежную карту для оплаты подписки. Но есть решение: >>> Study24.ai <<< — российский агрегатор нейросетей, который предоставляет доступ к Nano Banana без VPN, с русским интерфейсом и оплатой картами РФ.
▶️▶️▶️ Попробовать Nano Banana без VPN.
В этом гайде вы узнаете:
Что такое нейросеть Nano Banana от Google и почему это прорыв 2025 года
Где находится официальный сайт NanoBanana и как его открыть
Как скачать и установить Нанобанана в России без VPN
Как получить доступ через Study24.ai — лучший способ для РФ
Как писать промты для генерации фото и редактирования изображений
50+ готовых промптов для Nano Banana на все случаи
Где применять нейронку: от фотосессий до e-commerce
Сколько стоит подписка Nano Banana и как её оплатить из России
Реальные примеры работы и ограничения модели
Почему Nano Banana стала сенсацией 2025 года:
✅ 95% точность сохранения лица — в 1.5 раза лучше, чем у конкурентов
✅ Генерация за 1-2 секунды — в 5-10 раз быстрее Midjourney
✅ Понимает русский язык — пишите промпты как угодно, естественным языком
✅ Точное редактирование фото — меняет только то, что вы указали, не трогая остальное
✅ Работает с несколькими изображениями — объединяет до 5 фото в одну композицию
Нейросеть Nano Banana (официальное название: Google Gemini 2.5 Flash Image) создана не просто для генерации картинок с нуля, как Midjourney. Её главная сила — точное редактирование существующих фотографий с сохранением реалистичности. Вы можете сменить одежду, фон, прическу, убрать лишние объекты или провести виртуальную фотосессию — и при этом лицо человека останется узнаваемым на 95%.

Как использовать Nano Banana из России в 2025 году:
Главная проблема российских пользователей — официальный доступ к Google Gemini закрыт. Сайт gemini.google.com не открывается с российских IP, а aistudio.google.com требует Google-аккаунт без российского номера телефона.
Решение — Study24.ai: российский сервис с прямым API-доступом к нейросети Nano Banana. Работает без VPN, принимает российские карты, даёт 40 бесплатных токенов для тестирования и предоставляет круглосуточную техподдержку на русском языке.
Что такое нейросеть Nano Banana (Нано Банана) и почему это прорыв 2025 года
Nano Banana (Нано Банана, НаноБанана) — это внутреннее кодовое название передовой модели Google для генерации и редактирования изображений. Официально она называется Gemini 2.5 Flash Image и является частью экосистемы Google Gemini. Нейросеть была представлена в августе 2025 года и мгновенно стала сенсацией: за первые два месяца пользователи сгенерировали более 5 миллиардов изображений.
История и названия модели Nano Banana
Официальный анонс нейронки случился 26 августа 2025 года. Google назвала модель Gemini 2.5 Flash Image, но интернет-сообщество предпочло оставить прозвище — и теперь Nano Banana используется повсеместно, хотя в официальной документации Google вы найдёте только название Gemini 2.5 Flash Image.
Официальный идентификатор модели в Google API: gemini-2.5-flash-image-preview
Технические характеристики нейронки Nano Banana
Nano Banana — это не просто генератор картинок, а мультимодальная модель, которая понимает контекст, анализирует композицию и работает с несколькими изображениями одновременно. Вот что выделяет её на фоне конкурентов:
Архитектура и возможности:
✅ State-of-the-art (SOTA) в генеративной графике — модель использует самые передовые достижения в области AI
✅ Контекст до 32,768 токенов — может обрабатывать сложные запросы с несколькими изображениями и детальными инструкциями
✅ Мультимодальный вход — принимает текст + до 5 изображений одновременно, выдаёт визуал + структурированные данные (JSON)
✅ Ультрабыстрая генерация — создаёт изображение за 1-2 секунды, что в 5-10 раз быстрее Midjourney
✅ SynthID — цифровая метка — Google встраивает невидимую метку в каждое сгенерированное изображение для отслеживания AI-контента
✅ Multi-image fusion — умеет объединять несколько фотографий в одну композицию с сохранением реалистичности
✅ Character consistency — сохраняет лицо, позу и черты персонажа при редактировании с точностью 95%
Что умеет нейросеть Nano Banana от Google:
Генерация изображений с нуля по текстовому описанию (промту)
Точное редактирование существующих фотографий — меняет только указанные элементы
Удаление объектов с автоматическим заполнением фона
Добавление новых элементов с подстройкой света и теней
Смена фона с сохранением перспективы и освещения
Виртуальная примерка одежды с сохранением пропорций тела
Изменение стиля изображения (фотореализм, аниме, живопись и др.)
Реставрация и колоризация старых фотографий
Работа с несколькими изображениями — объединяет до 5 фото в одну сцену
Понимание естественного языка — промпты можно писать на русском языке разговорным стилем
Главные преимущества Nano Banana над конкурентами

Аналоги Nano Banana

Почему Nano Banana — лучший выбор в 2025 году:
Фотореалистичность на уровне профессиональных съёмок — модель понимает физику света, перспективу и материал поверхности
Результат с первой попытки — в отличие от Midjourney, где нужно генерировать десятки вариантов, Nano Banana чаще всего выдаёт нужный результат сразу
"Додумывает" недостающие элементы — если объект частично за кадром, нейросеть логично восстанавливает его
Консистентность персонажей — для серии изображений (например, комикс или инструкция) Nano Banana сохраняет лицо и стиль персонажа на 95%
Понимает естественный русский язык — можно писать промпты как угодно: "убери эту вазу со стола" или "сделай фон потеплее"
Работает быстрее всех — генерация за 1-2 секунды против 10-30 секунд у Midjourney
В чём секрет нейронки Nano Banana?
В отличие от типичных "рисующих" моделей (Midjourney, DALL-E), которые создают изображение с нуля слой за слоем, Nano Banana анализирует контекст сцены и редактирует изображение так, чтобы изменения выглядели естественно.
Именно поэтому Nano Banana называют "убийцей Фотошопа" — она делает за 10 секунд то, на что у профессионального ретушёра уходят часы работы.
С августа по октябрь 2025 года Google активно интегрирует Nano Banana в свои продукты:
✅ Google Lens — редактирование фото прямо в приложении камеры
✅ Google Search — режим Create для мгновенной трансформации снимков
✅ NotebookLM — генерация иллюстраций для видео-обзоров
🔜 Google Photos — скоро появится встроенный AI-редактор
Nano Banana официальный сайт: где найти, как скачать и получить доступ в 2025 году
Официальные сайты Google с нейросетью Nano Banana:
1. gemini.google.com — основной сайт Google Gemini
Главная платформа для работы с Nano Banana от Google
Встроенный чат-интерфейс для генерации и редактирования изображений
Доступ к модели через команды в текстовом поле
Статус для России: ❌ Не работает с российскими IP-адресами
Требуется VPN для обхода блокировки
2. aistudio.google.com/models/gemini-2-5-flash-image — Google AI Studio
Лабораторная площадка для разработчиков
Прямой API-доступ к модели Gemini 2.5 Flash Image
Тестирование промптов и настройка параметров
Статус для России: ❌ Требуется Google-аккаунт без российского номера телефона
Необходим VPN и зарубежная карта
3. Google Lens (приложение для iOS/Android)
С октября 2025 года Nano Banana интегрирована в приложение камеры
Редактирование фото прямо в реальном времени
Статус для России: ⚠️ Доступно, но функции AI-редактирования ограничены
4. Google Search (веб-версия)
Режим "Create" для трансформации снимков
Статус для России: ❌ Недоступен для российских пользователей
5. nanobanana.ai — независимый сервис
Использует API Google Nano Banana
Это НЕ официальный сайт Google, а сторонний провайдер
Статус для России: ⚠️ Работает, но требует оплату зарубежной картой
Проблема доступа к Nano Banana из России
Почему официальный сайт Nano Banana от Google не работает в России:
❌ Географические ограничения — Google Gemini официально недоступен с российских IP-адресов с марта 2024 года
❌ Блокировка оплаты — невозможно оплатить подписку Google One AI Premium картами российских банков
❌ Проблемы с аккаунтами — для регистрации в Google AI Studio нужен номер телефона из разрешённых стран
❌ Нужен VPN — даже с VPN аккаунты могут временно блокироваться при обнаружении российского IP в истории
Что происходит при попытке открыть gemini.google.com из России:
Сайт перенаправляет на страницу с ошибкой доступа
Или показывает список стран, где сервис доступен
Россия в этом списке отсутствует
Попытка использовать VPN:
✅ США, Германия, Нидерланды работают стабильнее всего
⚠️ Но Google может заблокировать аккаунт при подозрении на нарушение правил
⚠️ Оплата всё равно требует зарубежную карту
Можно ли скачать Nano Banana как приложение?
Важно понять: Nano Banana — это не отдельное приложение, которое можно скачать и установить на компьютер или телефон. Это облачная нейросеть, которая работает на серверах Google и доступна только через интернет.
Что можно скачать:
✅ Приложение Google Gemini (для iOS и Android)
Официальное приложение Google с доступом к Nano Banana
Скачать из Google Play или App Store
Проблема: Не работает с российскими аккаунтами Google
Решение: Нужен аккаунт, зарегистрированный в разрешённой стране + VPN
❌ Десктопное приложение Nano Banana — не существует
Google не выпускала отдельный софт для Windows/macOS/Linux
Все альтернативы в интернете — это обёртки над веб-версией или мошенничество
❌ Скачать нейросеть Nano Banana локально — невозможно
Модель работает только на серверах Google
Весит несколько терабайт и требует специализированное оборудование (TPU)
Google не предоставляет открытый доступ к весам модели
Вывод: Вместо поиска "как скачать Nano Banana" правильный вопрос — "как получить доступ к нейросети Nano Banana онлайн".
Study24.ai — лучший способ доступа к Nano Banana в России
Study24.ai — российский агрегатор нейросетей, который предоставляет прямой API-доступ к Google Gemini 2.5 Flash Image (Nano Banana) без VPN, блокировок и сложностей с оплатой.
Почему Study24.ai — оптимальное решение для российских пользователей:
✅ Работает без VPN
✅ Оплата российскими картами
✅ Полностью на русском языке
✅ Не требует установки
✅ 30+ нейросетей в одном месте
✅ Единый баланс токенов
✅ Токены не сгорают
✅ Техподдержка 24/7
✅ Быстрая генерация
Пошаговая инструкция: как пользоваться Nano Banana через Study24.ai
Шаг 1. Регистрация
Перейдите на сайт study24.ai
Нажмите "Регистрация" в правом верхнем углу
Введите email и придумайте пароль
Подтвердите email (придёт письмо с кодом)
На балансе автоматически появятся 40 бесплатных токенов
Шаг 2. Выбор модели Nano Banana
В главном меню найдите раздел "Генерация изображений"
Выберите модель "Nano Banana"
Или воспользуйтесь поиском: введите "nano banana" в строку поиска
Шаг 3. Загрузка изображения (для редактирования)
Нажмите кнопку "Загрузить фото" или перетащите файл в окно
Можно загрузить до 5 изображений одновременно
Поддерживаются форматы: JPG, PNG, WebP
Максимальный размер файла: 10 МБ
Шаг 4. Написание промпта
В текстовом поле опишите, что хотите получить или изменить
Пишите на русском языке естественным стилем
Примеры:
"Убери всех людей с заднего фона"
"Переодень девушку в красное платье"
"Сделай фон — парижская улица на закате"
Шаг 5. Настройка параметров (опционально)
Выберите разрешение: HD (1024×1024) или 4K (2048×2048)
Укажите количество вариантов: 1-4 изображения
Можно добавить отрицательные промты (что НЕ показывать)
Шаг 6. Генерация
Нажмите кнопку "Сгенерировать"
Подождите 15-30 секунд
Модель Nano Banana обработает запрос и выдаст результат
Шаг 7. Работа с результатом
Просмотрите сгенерированные варианты
Скачайте понравившееся изображение (PNG или JPEG)
Если результат не устроил — уточните промт и сгенерируйте снова
Первые 2-3 итерации обычно бесплатны (зависит от тарифа)
Если токены закончились:
Перейдите в раздел "Пополнить баланс"
Выберите удобный тариф (от 199₽ за 400 токенов)
Оплатите российской картой или другим способом
Токены зачислятся мгновенно
Сравнение способов доступа к Nano Banana в России

*Бесплатно — но с лимитами на количество генераций в день
Вывод: Для большинства российских пользователей Study24.ai — самый простой, быстрый и надёжный способ получить доступ к нейросети Nano Banana в 2025 году. Никаких танцев с VPN, блокировок аккаунтов и проблем с оплатой.
Альтернативные способы: когда они имеют смысл
Google Gemini через VPN — подходит, если:
У вас уже есть Google-аккаунт, зарегистрированный в разрешённой стране
Готовы потратить время на настройку стабильного VPN
Нужен полностью бесплатный доступ (с лимитами)
Telegram-боты с Nano Banana — подходят, если:
Хотите работать прямо из Telegram без открытия браузера
Нужны простые задачи (смена фона, ретушь)
Готовы мириться с рекламой и ограниченным функционалом
Google AI Studio — подходит, если:
Вы разработчик и хотите интегрировать Nano Banana в своё приложение
Нужен прямой API-доступ с тонкой настройкой параметров
Готовы разбираться с технической документацией на английском
Приложение Google Gemini — подходит, если:
Работаете только со смартфона
Уже пользуетесь VPN постоянно
Хотите редактировать фото прямо в галерее телефона
Во всех остальных случаях Study24.ai остаётся оптимальным выбором по соотношению простоты, скорости и цены.

Для чего нужна нейросеть Nano Banana: где использовать в 2025 году
Нейросеть Nano Banana от Google — универсальный инструмент для работы с изображениями, который подходит как профессионалам, так и обычным пользователям. С августа по октябрь 2025 года модель протестировали более 10 миллионов пользователей по всему миру, и вот самые популярные сценарии применения.
Практическая таблица применения Nano Banana

Как использовать Nano Banana?
ТОП-20 задач для нейросети Nano Banana
Работа с людьми:
Виртуальные фотосессии — создание профессиональных портретов без реальной съёмки
Виртуальная примерка одежды — посмотреть, как будет сидеть вещь перед покупкой
Смена прически и цвета волос — экспериментируйте с образом без похода к парикмахеру
Изменение возраста на фото — состарить или омолодить себя на снимке
Ретушь портретов — убрать прыщи, морщины, выровнять тон кожи
Коррекция эмоций — добавить улыбку или изменить выражение лица
Корпоративные фото — создать деловой портрет для LinkedIn или резюме
Работа с фоном и локациями:
8. Смена фона на фото — перенести себя в Париж, на пляж или в горы
9. Удаление людей с фона — убрать посторонних с туристических снимков
10. Виртуальные путешествия — создать фото из любой точки мира
Для бизнеса:
11. Фото товаров для маркетплейсов — карточки для Wildberries, Ozon без дорогой фотосессии
12. Генерация рекламных баннеров — визуалы для контекстной и таргетированной рекламы
13. Обложки для статей и блогов — уникальные иллюстрации под тематику
14. Создание логотипов и брендинга — первые наброски фирменного стиля
Креатив и развлечения:
15. 3D-фигурки по фото — вирусный тренд 2025 года (создание коллекционных фигурок)
16. Обложки для журналов — поместите себя на обложку Vogue или Forbes
17. Стилизация под эпохи — фото в стиле 1920-х, 50-х, 80-х, 90-х годов
18. Превращение в персонажа — аниме-стиль, Studio Ghibli, живопись Ван Гога
Реставрация и улучшение:
19. Восстановление старых фото — реставрация семейного архива с царапинами и выцветанием
20. Колоризация чёрно-белых снимков — превратить старое фото в цветное
Самый популярный кейс: виртуальные фотосессии с Nano Banana
Виртуальная фотосессия — это создание профессиональных портретов без реальной съёмки в студии. Вы загружаете своё фото, описываете желаемую локацию, стиль одежды и освещение — и нейросеть Nano Banana генерирует изображение, которое выглядит как настоящая фотосессия.
Зачем это нужно:
Экономия времени и денег (фотосессия в студии стоит от 5,000₽, Nano Banana — от 3.5₽)
Можно "побывать" в любой локации мира без поездки
Примерить любую одежду без покупки
Создать десятки образов за минуты
Промпты для фотосессий в Nano Banana:

Пляжная фотосессия:
Девушка в белом летнем платье стоит на тропическом пляже с белым песком, на фоне бирюзовая вода и пальмы, золотой час (закат), романтическое настроение, профессиональная фотосессия, формат 3:4. Не меняй лицо.

Городская фотосессия:
Девушка в чёрном пальто идёт по улице Парижа, Эйфелева башня на заднем плане, осенний вечер, мягкий свет уличных фонарей, кинематографичная атмосфера, формат 4:5. Сохрани черты лица.

Студийная фотосессия:
Портрет мужчины в деловом костюме на нейтральном сером фоне, студийное освещение с софтбоксом, профессиональная корпоративная съёмка, резкий фокус на лице, формат 2:3. Не меняй внешность.
Nano Banana для e-commerce: фото товаров для маркетплейсов
Задача: Продавцы на Wildberries, Ozon и других маркетплейсах тратят тысячи рублей на профессиональные фото товаров. Nano Banana позволяет создавать качественные карточки товаров за секунды и копейки.
Что можно сделать:
Поместить товар на чистый белый фон (требование маркетплейсов)
Показать товар в интерьере или на модели
Создать lifestyle-съёмку (товар в использовании)
Сделать несколько ракурсов одного товара

Промпт для карточки товара:
Белые кроссовки Nike на чистом белом фоне, студийное освещение без теней, профессиональная предметная съёмка, высокая детализация, формат квадрат 1:1

Промпт для lifestyle-съёмки:
Девушка в спортивной одежде держит в руках бутылку протеинового коктейля [ваш товар], сидит в современном фитнес-зале, естественное освещение, здоровый образ жизни, формат 4:5
Nano Banana для SMM: контент для социальных сетей
Проблема: Блогеры и SMM-специалисты тратят часы на поиск подходящих фото для постов, сторис и обложек. Nano Banana создаёт уникальный контент под любую тематику.
Что создавать:
Обложки для постов ВКонтакте и Telegram
Сторис для Instagram* с вами в разных локациях
Аватарки и баннеры для профилей
Иллюстрации к статьям и новостям

Промпт для сторис:
Девушка держит чашку кофе в уютном кафе с большими окнами, за окном осенний парк, тёплая атмосфера, естественный свет, вертикальный формат 9:16. Не меняй лицо.
Реставрация семейных фотографий с Nano Banana
Одно из самых востребованных применений нейросети Nano Banana — восстановление старых семейных фото. Модель умеет убирать царапины, заломы, пятна, восстанавливать утраченные фрагменты и превращать чёрно-белые снимки в цветные.
Промпт для реставрации:
Восстанови это старое повреждённое фото: убери все царапины, пятна, заломы и дефекты. Увеличь чёткость и резкость. Сделай цвета современными, как на фотографиях 2025 года. Максимально сохрани лица людей. Не добавляй и не убирай ничего, кроме дефектов.
Что умеет Nano Banana в реставрации:
Убрать физические повреждения (царапины, трещины, пятна)
Восстановить размытые участки
Сделать чёрно-белое фото цветным
Увеличить резкость и детализацию
Убрать цифровой шум
Дизайн интерьера с нейросетью Nano Banana
Дизайнеры интерьера и обычные люди, планирующие ремонт, используют Nano Banana для визуализации будущего интерьера.
Что можно сделать:
Показать, как будет выглядеть комната после ремонта
Поменять цвет стен, пола, потолка
Расставить мебель виртуально
Попробовать разные стили (скандинавский, лофт, классика)
Промпт для дизайна интерьера:
Покажи эту комнату с современным ремонтом в скандинавском стиле: светлые стены (белый/светло-серый), деревянный пол, минималистичная мебель, много света. Оставь окна и размер комнаты неизменными. Добавь серый диван, деревянный журнальный столик, торшер, зелёные растения в горшках.
Кому НЕ подойдёт Nano Banana
Несмотря на универсальность, есть задачи, где нейросеть Nano Banana работает хуже:
❌ Генерация текста на изображениях — особенно на русском языке (буквы получаются кривыми)
❌ Сложные технические чертежи — лучше использовать CAD-программы
❌ Анимация и видео — Nano Banana создаёт только статичные изображения, для оживления изображений используйте лучше Sora 2 и Veo 3.
❌ Точное копирование конкретных людей — полная замена лица работает нестабильно (95% похожесть, но не 100%)
Для этих задач лучше использовать специализированные инструменты или другие нейросети.

Как писать промты для Nano Banana: правила создания запросов для генерации изображений
Промпт (prompt) — текстовый запрос к нейросети Nano Banana, который описывает желаемое изображение или изменения в существующем фото. Качество промпта напрямую определяет результат: чем точнее описание, тем лучше нейросеть поймёт вашу задачу.
Главное преимущество Nano Banana от Google — модель понимает естественный русский язык. Вам не нужно учить специальный синтаксис или писать промпты только на английском. Можно использовать разговорный стиль: "убери эту вазу со стола", "сделай фон теплее", "добавь мягкий закатный свет". Однако для максимально точных результатов Google всё же рекомендует английский язык, особенно при работе в Figma и через API.
Но это не значит, что можно писать что угодно. Google выпустила официальное руководство по промптингу для Nano Banana, где чётко сформулировано: "Хватит использовать заклинания в стиле Stable Diffusion — говорите с ИИ на понятном человеческом языке, но подробно и структурированно".
Золотое правило промптинга: описывай сцену, а не ключевые слова
"Describe the scene, don't just list keywords" — главный принцип работы с Nano Banana.
Нейросеть — это не поисковая система. Она создаёт или редактирует визуальную сцену на основе вашего описания. Поэтому важно описывать связную картину, а не набор отдельных слов.
❌ Плохой промпт (список ключевых слов):
кот, милый, рыжий, пушистый, окно, солнце, уют
✅ Хороший промпт (описание сцены):
Пушистый рыжий кот свернулся клубочком и спит на солнечном подоконнике. За окном видны зелёные деревья. Мягкий дневной свет падает на его шерсть.
Почему это работает лучше: В первом случае нейросеть получает разрозненные теги и сама додумывает связи между ними — результат может быть непредсказуемым. Во втором случае вы даёте полную картину того, что должно быть на изображении, и Nano Banana воссоздаёт именно её.
Структура идеального промта для Nano Banana
Google рекомендует использовать следующую структуру промпта:
Базовая формула:
[Тип кадра] → [Субъект] → [Действие] → [Окружение] → [Освещение] → [Настроение] → [Технические параметры] → [Ограничения]
Разберём каждый элемент подробнее:
Тип кадра определяет композицию изображения: портрет, пейзаж, предметная съёмка, макро, панорама. Это задаёт общую структуру кадра.
Субъект — главный объект внимания: человек (с указанием возраста и внешности), животное, товар, здание, автомобиль. Центр композиции, вокруг которого строится всё остальное.
Действие придаёт динамику: что делает субъект — стоит, сидит, идёт, улыбается, смотрит в камеру, держит предмет. Статичная поза или движение сильно влияют на восприятие.
Окружение задаёт контекст: улица конкретного города, офис, студия с определённым фоном, пляж, лес, уютное кафе. Детали окружения создают атмосферу.
Освещение — один из критически важных элементов для Nano Banana. Опишите характер света: золотой час (за час до заката), мягкое рассеянное, драматическое с глубокими тенями, студийное с софтбоксом, пасмурный день. Nano Banana понимает физику света и подстроит тени под новые объекты, если вы это укажете.
Настроение создаёт эмоциональный тон: уютное и тёплое, деловое и строгое, романтическое и мечтательное, тревожное и напряжённое, радостное и праздничное.
Технические параметры для профессионального вида: разрешение (4K, HD), формат кадра (16:9, 3:4, квадрат), эффекты (боке, виньетирование), имитация конкретной оптики (85mm portrait lens, wide angle).
Ограничения — самый важный элемент для контроля: чёткие инструкции, что НЕ менять. Например: "Не меняй лицо", "Оставь фон прежним", "Сохрани пропорции тела", "Не трогай одежду". Без этих ограничений Nano Banana может изменить то, что вы хотели сохранить.

Пример полного промпта:
Портрет девушки 25 лет в белом летнем платье, стоит на берегу моря босиком в воде по щиколотку, смотрит на закат, волосы развеваются на ветру, золотой час (мягкий тёплый свет с оранжевым оттенком), романтическое настроение, профессиональная фотосессия в стиле lifestyle, формат 3:4, высокая детализация. Не меняй черты лица и пропорции фигуры.
Такой промт покрывает все ключевые элементы и даст предсказуемый результат с первой попытки в 80% случаев.
Пять золотых правил написания промптов для Nano Banana
Правило 1: Будь максимально конкретным
Общие слова типа "красиво", "хорошо", "качественно" ничего не говорят нейросети. Nano Banana нужны конкретные, измеримые детали.
❌ Плохо: "Сделай фото красивым"
✅ Хорошо: "Убери прыщи и покраснения на коже, выровняй тон лица, добавь мягкое естественное сияние, сохрани текстуру кожи и мимику лица"
❌ Плохо: "Улучши эту комнату"
✅ Хорошо: "Добавь в эту комнату серый велюровый диван вдоль правой стены, деревянный журнальный столик из светлого дуба перед диваном, торшер с тёплым светом в углу, три зелёных растения в белых керамических горшках. Стиль скандинавский минимализм. Не меняй окна, стены и размер комнаты"
Чем подробнее описание, тем точнее результат. Указывайте материалы, цвета, расположение объектов, размеры.
Правило 2: Учитывай физику света и теней
Одна из главных сил Nano Banana — понимание того, как ведёт себя свет в реальном мире.
Всегда добавляйте в промпт описание освещения: откуда падает свет, какой он по характеру (мягкий/резкий), какого оттенка (тёплый/холодный). Если меняете объект или фон, обязательно укажите: "адаптируй тени под новый объект" или "сохрани текущее освещение сцены".
Примеры правильного описания света:
"Мягкий закатный свет падает слева, создавая тёплые оранжевые оттенки на лице"
"Студийное освещение: основной софтбокс справа под углом 45 градусов, заполняющий свет слева, белый отражатель снизу"
"Естественный дневной свет из большого окна справа, рассеянный через тонкую штору"
"Драматическое вечернее освещение: единственный источник света — настольная лампа, создающая глубокие тени"
Без учёта света добавленные объекты будут выглядеть "приклеенными" с неправильными тенями. С правильным описанием они органично впишутся в сцену.
Правило 3: Описывай желаемый результат, а не процесс
Nano Banana лучше понимает, что вы хотите видеть, чем как это технически сделать.
❌ Плохо (описание процесса):
Перекрась волосы девушки в рыжий цвет
✅ Хорошо (описание результата):
Девушка с медно-рыжими волосами до плеч сидит в кафе за столиком у окна. Волосы блестят на свету, естественный оттенок. Не меняй лицо, одежду и фон.
❌ Плохо:
Удали диван с заднего плана и замени на что-то другое
✅ Хорошо:
На месте дивана теперь большое панорамное окно в пол с видом на ночной город. На широком подоконнике стоят три зелёных растения в серых горшках. Сохрани освещение комнаты и расположение других предметов.
Почему это работает лучше: нейросеть "видит" финальную картинку в вашем описании и воссоздаёт её целиком, а не пытается выполнить команду пошагово как алгоритм.
Правило 4: Изменяй по одному параметру за раз (пошаговое редактирование)
Один из главных секретов профессионального использования Nano Banana — итеративный подход. Не пытайтесь изменить всё в одном промпте.
Лучше сделать 3-4 коротких промпта последовательно, чем 1 перегруженный.
❌ Плохо (всё сразу):
Переодень девушку в красное вечернее платье, перекрась волосы в платиновый блонд, перенеси её на улицу Парижа с Эйфелевой башней на фоне, сделай закатное освещение, убери сумку из руки, добавь букет красных роз, поверни её немного влево
✅ Хорошо (поэтапно):
Шаг 1:
Переодень девушку в красное вечернее платье с открытыми плечами. Не меняй лицо, позу и фон.
Шаг 2:
Перенеси эту девушку на улицу Парижа, Эйфелева башня видна на заднем плане на расстоянии 200 метров, вечер, мягкий свет уличных фонарей, брусчатка под ногами. Сохрани одежду, лицо и позу.
Шаг 3:
Убери сумку из рук девушки, добавь вместо неё букет из 11 красных роз, завёрнутый в прозрачную плёнку. Не меняй ничего больше.
Преимущества пошагового подхода: вы контролируете каждое изменение, можете откатить неудачный шаг без потери всей работы, нейросеть не запутается в сложных инструкциях, экономите токены (не нужно переделывать всё с нуля).
Правило 5: Всегда указывай ограничения
Самая частая проблема пользователей Nano Banana: нейросеть меняет то, что трогать не нужно было. Особенно это касается лиц — портретное сходство может потеряться.
Обязательно добавляйте в конец каждого промпта фразы-ограничения:
"Сохрани внешность полностью" — максимальная сохранность
"Оставь фон прежним" — только объект редактируется
"Не трогай одежду" — меняется всё, кроме одежды
"Больше ничего не редактируй" — универсальное ограничение
"Сохрани пропорции тела" — важно при смене одежды
"Не меняй позу и жесты" — сохранит положение рук, ног, головы
Пример промта с правильными ограничениями:
Переодень девушку с этого фото в синее деловое платье длиной до колен с длинным рукавом. Не меняй лицо, позу, фигуру, фон и освещение.
Без этих ограничений Nano Banana может решить "улучшить" лицо, немного изменить позу или подправить фон — и это будет уже другое изображение.
*Instagram (принадлежит Meta, признанной экстремистской и запрещенной на территории РФ)
Показать полностью
15

ChatGPT теперь знает всё про вашу контору: OpenAI запустила функцию, от которой HR-ы рыдают, а боссы — в экстазе
OpenAI незаметно запустила Company Knowledge — штуку, которая превращает ChatGPT в корпоративного всезнайку. Теперь ИИ напрямую лезет в вашу почту, Slack, Google Drive и даже GitHub. Это удобно, жутковато и одновременно открывает такие возможности, о которых раньше мечтали только киборги из фантастики.
OpenAI незаметно запустила Company Knowledge
22 октября OpenAI тихо включила функцию Company Knowledge для всех клиентов ChatGPT Business, Enterprise и Edu.
Если коротко: бот теперь роется во всех рабочих приложениях сразу — Slack, Gmail, SharePoint, Google Drive, Intercom, HubSpot и GitHub — и выдаёт ответы прямо по корпоративным данным, не заставляя вас переключаться между 15 вкладками.
Допустим, у тебя звонок с клиентом через час. Ты спрашиваешь ChatGPT: "Что у нас было с CompanyX за последний месяц?" — и он моментально собирает брифинг: выдёргивает переписку из Slack-каналов, достаёт тикеты поддержки Intercom, подтягивает заметки с прошлых встреч из Google Docs, прикрепляет письма из Gmail и даже смотрит обсуждения в GitHub, если там что-то обсуждали по клиенту.
Итог: детальная справка за 10 секунд вместо получасового копания в куче систем.
Фиджи Симо, CEO подразделения приложений OpenAI, объяснила суть: «Company Knowledge консолидирует контекст из всех ваших рабочих инструментов и даёт ответы, адаптированные под специфику бизнеса».
Работает это на специальной версии GPT-5, заточенной под мультиисточники и точность.
В каждом ответе указаны источники — откуда взялась та или иная информация, поэтому можно сразу проверить достоверность.
Самое интересное — как OpenAI решила вопрос безопасности. ChatGPT видит только те данные, к которым у конкретного сотрудника есть доступ по корпоративной политике. Права и ограничения остаются такими же, как в исходных приложениях — если ты не можешь прочитать секретный канал, то и ChatGPT его не покажет.
Операционный директор OpenAI Брэд Лайткап признался: «Company Knowledge изменил то, как я пользуюсь ChatGPT на работе, сильнее любой другой функции».
Функция уже доступна глобально, строится на базе августовских интеграций для индивидуальных подписчиков ChatGPT Plus, которые теперь масштабировали на корпоративный сегмент.
Аналитики VentureBeat сравнивают Company Knowledge с Google Enterprise Search и отмечают: OpenAI пытается сделать ChatGPT центральной точкой доступа к проверенным данным компании, усиливая это безопасными интеграциями и соблюдением корпоративных стандартов.
Запуск совпал с другими анонсами: два дня назад OpenAI представила браузер ChatGPT Atlas со встроенным AI-помощником и режим Agent Mode, который способен выполнять многоэтапные задачи вроде планирования поездок или бронирования билетов. Компания явно выстраивает экосистему, где ChatGPT становится рабочей операционкой для бизнеса.
В итоге: сотрудники получают мгновенные ответы с указанием источников, экономят кучу времени и принимают более точные решения. OpenAI рассчитывает, что Company Knowledge станет стандартом для корпоративного AI и закрепит ChatGPT как must-have инструмент для любой команды. Осталось только дождаться, когда начнутся мемы про то, как ChatGPT нашёл переписку про корпоратив в закрытом канале.
Показать полностью
Пространственно-временные зависимости в видео: как явные доказательства улучшают понимание
Автор: Денис Аветисян
На протяжении долгого времени анализ видеоконтента сталкивался с фундаментальной проблемой: неспособностью к тонкому, нюансированному рассуждению, необходимому для точного ответа на вопросы. Традиционные подходы часто оказывались бессильны перед сложными сценами и динамичными событиями, упуская критически важные детали. Прорыв, представленный в ‘Open-o3 Video: Grounded Video Reasoning with Explicit Spatio-Temporal Evidence’, заключается в внедрении подхода, который не просто распознает объекты и действия, но и явно связывает их с конкретными моментами времени и пространством, формируя четкое обоснование для каждого ответа. Но сможет ли подобный уровень детализации и прозрачности в рассуждениях открыть путь к созданию действительно "видящих" машин, способных не только понимать видео, но и объяснять свои выводы так же, как это делает человек?

В отличие от предшествующих моделей, ограничивающихся текстовыми объяснениями, Open-o3 Video выявляет ключевые моменты и области видео, демонстрируя логику принятия решения и позволяя проверить обоснованность предсказания.
Понимание Видео: Исследование Пространственно-Временных Связей
Понимание видео – это задача, требующая не просто распознавания объектов, но и выстраивания логических связей между ними во времени и пространстве. Традиционные методы анализа видео зачастую оказываются неспособны справиться с этой задачей, ограничиваясь поверхностным описанием сцены и упуская тонкие нюансы, необходимые для точного ответа на вопрос. Это связано с тем, что многие существующие подходы сосредотачиваются на извлечении признаков, не уделяя достаточного внимания построению целостной картины происходящего.
Существующие методы часто испытывают трудности с точной локализацией событий как в пространстве, так и во времени. Неспособность выделить ключевые моменты и указать на конкретные области изображения приводит к неточным или неполным ответам. Представьте себе задачу определения, какой предмет был взят персонажем в определенный момент времени. Если система не может точно определить местоположение персонажа и объекта в кадре, а также момент, когда произошло взаимодействие, ответ будет неверным или неполным. Эта проблема особенно актуальна для сложных сцен с множеством объектов и динамичными событиями.
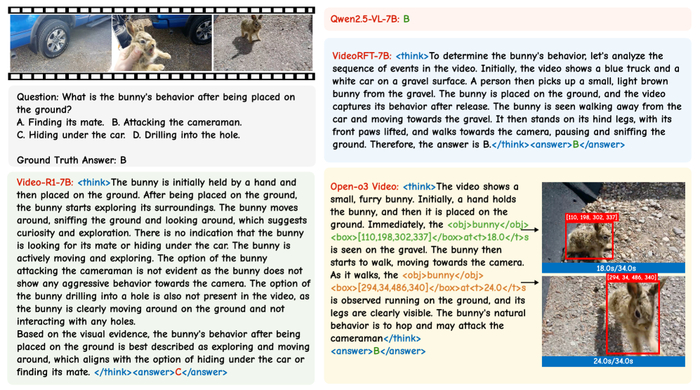
Визуализация точно локализует время и место действия для распознавания действий, превосходя Video-R1.
Недостаток точной локализации приводит к тому, что система не может установить причинно-следственные связи между событиями, что делает невозможным построение осмысленных ответов на вопросы, требующие логического мышления. Для решения этой проблемы необходимо разработать новые методы, которые способны не только распознавать объекты, но и отслеживать их перемещение во времени и пространстве, а также устанавливать связи между ними. Это требует интеграции визуальной информации с временными и пространственными данными, а также использования алгоритмов, способных выявлять закономерности и строить логические выводы.
В конечном итоге, задача понимания видео заключается не просто в извлечении информации, но и в построении осмысленной интерпретации происходящего. Для этого необходимо разработать методы, которые способны не только видеть, но и понимать, что происходит на видео, и предоставлять ответы, основанные на логическом мышлении и понимании контекста.
Open-o3 Video: Заземление Рассуждений в Пространстве и Времени
В стремлении к глубокому пониманию видеоконтента, исследователи представили Open-o3 Video – новаторскую систему, расширяющую границы традиционного видеоанализа. Представьте себе микроскоп, позволяющий не только увидеть изображение, но и проследить динамику процессов, происходящих во времени и пространстве. Именно таким инструментом и является Open-o3 Video. В отличие от подходов, ограничивающихся общим пониманием сцены, эта система генерирует явные пространственно-временные доказательства, связывая логические выводы с конкретными кадрами и ограничивающими рамками.
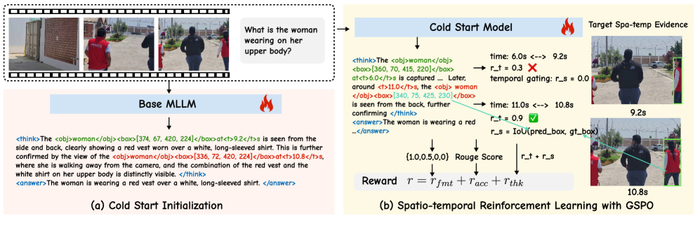
Обзор Open-o3 Video. Используется двухэтапный подход к обучению: (a) инициализация для обучения структурированным результатам; (b) обучение с подкреплением с комбинированной наградой, улучшающей временную и пространственную точность.
Ключевой особенностью системы является её способность к точной привязке процессов рассуждения к видеоконтенту. Вместо абстрактных выводов, Open-o3 Video предлагает конкретные кадры с указанием времени и ограничивающими рамками объектов, участвующих в действии. Это позволяет не только проверить обоснованность выводов, но и проследить логику рассуждений, как будто просматривая фильм с комментариями эксперта. Такой подход открывает новые возможности для интерпретации видеоданных и построения надежных систем искусственного интеллекта.
Разработанная архитектура Open-o3 Video использует двухэтапный подход к обучению. Сначала модель инициализируется для формирования структурированных результатов, а затем проходит обучение с подкреплением, оптимизирующее как временную, так и пространственную точность. Адаптивная близость и управление временем позволяют модели эффективно усваивать знания, избегая перегрузки и обеспечивая стабильность обучения. Этот подход обеспечивает надежность и интерпретируемость, что крайне важно для построения доверительных систем искусственного интеллекта.
В конечном итоге, Open-o3 Video представляет собой значительный шаг вперед в области анализа видеоданных. Благодаря способности генерировать явные пространственно-временные доказательства, система открывает новые возможности для понимания сложных видеосцен и построения интеллектуальных систем, способных к логическому мышлению и обоснованным выводам. Это, по сути, не просто инструмент анализа, а новый способ видеть мир через призму данных.
Наборы Данных для Надежного Пространственно-Временного Обучения
Для создания надежных систем, способных к пространственно-временному обучению, исследователи представили два тщательно разработанных набора данных: STGR-CoT-30k и STGR-RL-36k. Эти ресурсы созданы для обеспечения комплексной поддержки обучения моделей, позволяя им овладевать сложными паттернами рассуждений и точностью локализации в видеоматериалах. STGR-CoT-30k служит основой для контролируемой тонкой настройки, предоставляя парные данные, состоящие из вопросов, ключевых кадров и подробных цепочек рассуждений. Такая структура позволяет моделям изучать не только точные ответы, но и логические шаги, ведущие к ним.
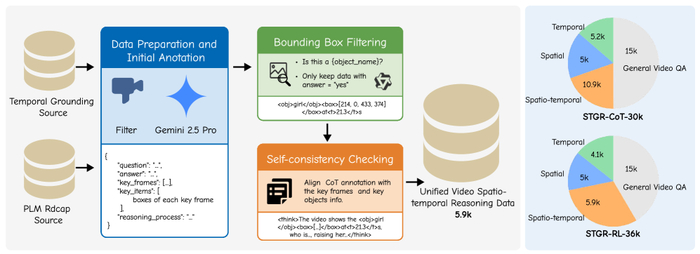
Обзор конвейера построения данных и состава набора данных. Слева: конвейер Gemini 2.5 Pro, фильтрацию ограничивающих рамок и проверку согласованности. Справа: распределение категорий данных в STGR-CoT-30k (SFT) и STGR-RL-36k (RL).
В то же время, STGR-RL-36k разработан специально для обучения с подкреплением, обеспечивая пространственно-временное наблюдение, необходимое для улучшения процесса обучения. Этот набор данных позволяет моделям учиться не только отвечать на вопросы, но и обосновывать свои ответы, выделяя соответствующие моменты и объекты в видео. Оба набора данных созданы с использованием больших языковых моделей, таких как Gemini 2.5 Pro, что гарантирует высокое качество аннотаций и соответствие современным стандартам обработки естественного языка. Применение таких инструментов позволяет моделировать сложные процессы рассуждений и получать более точные и надежные результаты. В результате, исследователи создали ценные ресурсы, которые открывают новые возможности для развития систем компьютерного зрения и обработки видео.
Оптимизация Пространственно-Временных Рассуждений с Использованием Продвинутых Методов
Для достижения устойчивой и точной работы системы пространственно-временного рассуждения, исследователи разработали ряд инновационных методов, направленных на оптимизацию процесса обучения и повышения надежности модели. В основе этих методов лежит понимание того, что недостаток данных или их неточность могут существенно влиять на конечные выводы.
Одним из ключевых аспектов является адаптивное приближение во времени (Adaptive Temporal Proximity). В процессе обучения с подкреплением, исследователи ослабили ограничения по временной точности. Это позволило стабилизировать процесс обучения, особенно на начальных этапах, когда модель еще не способна точно определять моменты времени. Вместо жестких требований к временной привязке, модель получала возможность совершать небольшие ошибки, что способствовало более плавному и эффективному обучению.
Для обеспечения точной пространственно-временной привязки, исследователи использовали механизм временной фильтрации (Temporal Gating). Этот механизм позволяет вознаграждать модель только за точные предсказания по времени, отсекая ложные или неточные результаты. Такой подход способствует более четкой и надежной привязке событий к конкретным моментам времени, что критически важно для понимания динамичных сцен.
Для повышения надежности системы при работе с новыми данными, исследователи разработали метод масштабирования времени тестирования с учетом уверенности (Confidence-Aware Test-Time Scaling). Этот метод позволяет взвешивать различные ответы модели в зависимости от их уверенности, отсеивая ложные или неуверенные результаты. Это позволяет повысить надежность и точность ответов модели, особенно в сложных или неоднозначных ситуациях.

Пример запроса для аннотации данных временной привязки.
В качестве алгоритма оптимизации пространственно-временного рассуждения была выбрана группа последовательной политики оптимизации (GSPO). Этот алгоритм, работающий в рамках обучения с подкреплением, позволяет модели более эффективно извлекать информацию из данных и улучшать свои способности к пространственно-временному рассуждению. GSPO позволяет модели не только идентифицировать объекты и события в видео, но и понимать их взаимосвязь во времени и пространстве. Исследователи подчеркивают, что предложенные методы, в совокупности, позволяют создать более надежную и точную систему пространственно-временного рассуждения, способную решать сложные задачи в области анализа видео.
Оценка и Будущие Направления в Области Понимания Видео
Оценка возможностей модели в области пространственно-временной привязки является ключевым шагом в развитии систем видеопонимания. В данной работе, в качестве строгой платформы для подобных оценок, использовался бенчмарк V-STAR. Его структура позволяет не просто констатировать факт ответа, но и анализировать, насколько точно модель локализует значимые события во времени и пространстве видеоряда.
В качестве отправной точки для сравнения и дальнейшего развития использовалась модель Qwen2.5-VL-7B, демонстрирующая стабильные результаты. Однако, целью исследования являлось не просто превзойти существующие решения, но и понять, какие именно аспекты видеопонимания требуют особого внимания. Ошибки, допущенные моделью, рассматривались не как провал, а как ценный источник информации, указывающий на слабые места в архитектуре и алгоритмах.
Анализ этих ошибок позволил сформулировать несколько ключевых направлений для дальнейших исследований. Во-первых, необходимо расширить возможности модели в обработке более сложных видеоданных, включающих большое количество объектов и динамичных сцен. Во-вторых, следует уделить внимание развитию алгоритмов, способных к многошаговому логическому выводу, выходящему за рамки простой идентификации объектов и событий. И, наконец, необходимо интегрировать в систему мультимодальные сигналы, включая аудио- и речевую информацию, которые часто содержат важные ключи к пониманию видеоконтента.

Визуализация показывает, что модель идентифицирует более эффективные подтверждающие доказательства в задачах рассуждения о погоде, в то время как связанные модели рассуждения о видео показывают низкую производительность.
Данная работа открывает путь к созданию систем искусственного интеллекта, способных к тонкому и нюансированному пониманию видеоконтента. Это, в свою очередь, позволит разработать передовые приложения в таких областях, как робототехника, системы видеонаблюдения и индустрия развлечений. Важно отметить, что процесс улучшения модели — это не просто достижение более высоких показателей, но и углубление понимания принципов работы визуального мышления и искусственного интеллекта.
Подобно тому, как мы стремимся понять закономерности в сложных системах, представленная работа Open-o3 Video демонстрирует важность явного представления пространственно-временных доказательств при рассуждениях о видео. Как верно заметил Эндрю Ын: «Мы должны сосредоточиться на том, чтобы сделать машинное обучение доступным для всех». Этот подход к обоснованию, с указанием конкретных временных меток и ограничивающих рамок, позволяет не только улучшить точность ответов на вопросы о видео, но и сделать процесс рассуждений более прозрачным и понятным – что, безусловно, приближает нас к созданию действительно интеллектуальных систем. По сути, Open-o3 Video акцентирует внимание на видимом – на доказательствах, которые система использует для обоснования своих выводов – и это соответствует нашему стремлению к пониманию не только что система делает, но и как она к этому пришла, избегая скрытых закономерностей и влияний шума.
Что дальше?
Представленная работа, безусловно, продвигает нас вперёд в понимании видео, но давайте не будем спешить с оптимизмом. Явное представление пространственно-временных доказательств – это, конечно, элегантно, но остаётся вопрос: насколько эта "явность" действительно приближает нас к пониманию, а не просто к более эффективному сопоставлению паттернов? Мы видим улучшение метрик, но часто забываем, что метрика – это лишь проекция, упрощение сложной реальности. Настоящее понимание требует не просто обнаружения "когда" и "где", а осознания "почему".
Будущие исследования, на мой взгляд, должны сосредоточиться на преодолении хрупкости этих систем. Слишком часто небольшие изменения в видео, незначительные отклонения от тренировочных данных, приводят к катастрофическим ошибкам. Необходимо развивать методы, способные к обобщению, к экстраполяции знаний за пределы узкого контекста. И, конечно, крайне важно исследовать возможности интеграции с другими модальностями – текст, звук, тактильные ощущения – чтобы создать поистине многогранное представление о мире.
И ещё одна мысль: визуальная интерпретация требует терпения. Быстрые выводы могут скрывать структурные ошибки. Возможно, нам стоит замедлиться, перестать гнаться за state-of-the-art и посвятить больше времени тщательному анализу тех фундаментальных принципов, которые лежат в основе нашего восприятия и понимания видео.
Оригинал статьи: https://arxiv.org/pdf/2510.20579.pdf
Связаться с автором: https://www.linkedin.com/in/avetisyan/
Показать полностью
6
>>> Фото в стиле Хэллоуин: 22 идеи и 22 промта для фотографий в стиле Хеллоуин

Искали промты для фото на Хэллоуин? Для вас есть целых 22 рабочих варианта, чтобы устроить мистическую фотосессию онлайн на Halloween на русском языке.
Предыдущие статьи:
Фото для статьи генерировал в Nano Banana, видео - в Veo 3.
Где сгенерировать страшные фото на Хэллоуин?
Искали промты для фото на Хэллоуин? Для вас есть целых 22 рабочих варианта, чтобы устроить мистическую фотосессию онлайн на Halloween на русском языке.
Хэллоуин 2025 — это не просто праздник тыкв и костюмов, а настоящий фестиваль креативности, где каждый может стать героем собственного хоррор-фильма или готической сказки. Фото в стиле Хэллоуин стали неотъемлемой частью праздника: миллионы людей по всему миру создают атмосферные кадры с ведьмами, призраками, вампирами и мистическими существами для TikTok и аватарок. Но что, если мы скажем, что для создания красивых фото Хэллоуин больше не нужны профессиональные фотосессии, сложный грим или дорогие костюмы?
Нейросети революционизировали способ сделать фото на Хэллоуин: теперь достаточно обычного селфи и правильного промта, чтобы превратиться в элегантную ведьму, готического вампира или героиню хоррор-фильма за считанные секунды! Искусственный интеллект для фото на Хэллоуин не просто накладывает фильтры — он создаёт полноценные художественные композиции с драматичным освещением, туманом, готическими декорациями и жуткой атмосферой, сохраняя при этом ваши черты лица.
Как сделать фото на Хэллоуин?
В этой статье мы собрали 22 готовых промпта для фото в стиле Хэллоуин, которые помогут вам создать уникальные идеи фото на хэллоуин для любого образа: от мистических ведьм с дымящимися тыквами до винтажных хоррор-сцен в стиле 70-х, от элегантных готических портретов до жутких кадров из фильмов ужасов. Каждый промт проверен и работает в популярных нейросетях — ChatGPT, Nano Banana и Midjourney, доступных через удобную платформу Study AI для российских пользователей без VPN и с оплатой в рублях.
Что вы узнаете из статьи:
Как сгенерировать фото на хэллоуин через нейросети за 1 минуту
20+ детальных промтов для генерации фото в стиле хэллоуина на любой вкус
Где использовать готовые страшные фото на хэллоуин и фото на аву хэллоуин
Как избежать типичных ошибок при создании фото на хэллоуин ии
Не важно, хотите ли вы Halloween образы в элегантном стиле или жуткие фото ведьмы на Хэллоуин с мистической атмосферой — наши промты для онлайн фотосессии помогут воплотить любую идею. Готовы создать свою хэллоуинскую магию? Поехали! 🎃✨
22 готовых промта для создания фото в стиле Хэллоуин
Теперь переходим к самому интересному — 22 промптам, которые помогут создать уникальные идеи фото на Хэллоуин под любой образ. Все промты проверены и работают в ChatGPT, NanoBanana и Midjourney через платформу Study AI. Просто скопируйте нужный промт, загрузите своё селфи — и через минуту получите профессиональное фото в стиле Хэлоуин.
Фотосессия на Хэллоуин с отличными снимками и без многочасовых позирований с фотографом— это же прекрасно и доступно всем!
Преимущества Study24.ai:
1️⃣ Работает без VPN из любого региона России
2️⃣ Оплата рублевой картой (никаких зарубежных карт не требуется)
3️⃣ Простой русскоязычный интерфейс
4️⃣ Техподдержка на русском языке
5️⃣ Доступ сразу к трём лучшим нейросетям для генерации фото: Nano Banana, ChatGPT (DALL-E 3), и Midjourney
6️⃣ Не нужен VPN и десятки аккаунтов
КАТЕГОРИЯ 1: Мистические образы (7 промптов)

Как сгенерировать фото ведьмы с тыквой
Промпт 1: Ведьма с дымящейся тыквой
Женщина в элегантном длинном чёрном платье стоит на уединённой тропе в сумерках. Она держит вырезанную тыкву-светильник, из которой вырывается яркий оранжевый или фиолетовый дым, слегка окутывая её. Освещение мягкое и золотистое от заходящего солнца на заднем плане. Сохрани моё лицо неизменным. Атмосфера мистическая, волшебная, кинематографичная. Высокая детализация, фотореалистично, малая глубина резкости с размытым фоном.
Используйте для: создания элегантных фото ведьмы на хэллоуин с магической атмосферой.

Как с ИИ сделать готическое фото на Хэллоуин в стиле Средневековой магии
Промпт 2: Ведьминская лаборатория
Женщина с длинными распущенными волосами сидит за старым деревянным столом, освещённым канделябром с горящими свечами. На столе лежит человеческий череп рядом с открытой древней книгой с пожелтевшими страницами. Она внимательно читает книгу, одна рука покоится на черепе. Сохрани моё лицо неизменным. Атмосфера тёмная, мистическая, готическая. Драматичное освещение свечами, создающее глубокие тени. Фотореалистично, высокое разрешение, кинематографичный стиль.
Используйте для: готических фото дома хэллоуин в стиле средневековой магии.

Как сделать с нейронкой романтичное фото на Хэллоуин
Промпт 3: Лесная ведьма с цветами
Женщина в костюме ведьмы с остроконечной чёрной шляпой сидит на деревенской тропинке в осеннем лесу. Вместо волшебной палочки она держит красивый дикий букет осенних цветов, тёмных ягод и трав. Её выражение лица спокойное и знающее, лёгкая загадочная улыбка. Сохрани моё лицо неизменным. Мягкий туман стелется между деревьями, золотистое вечернее освещение, сказочная умиротворённая атмосфера. Реалистичное фото, естественные цвета, высокая детализация.
Используйте для: мягких романтичных красивых фото хэллоуин без хоррора.

Как создать с искусственным интеллектом меланхоличный образ на Хэллоуин
Промпт 4: Готический портрет у моря
Чёрно-белое фото женщины с длинными чёрными волосами, развевающимися на ветру, в простом тёмном длинном платье. Она стоит на скалистом берегу моря в безлюдном мрачном пейзаже, бережно держит человеческий череп в руках, словно в нежных объятиях. Сохрани моё лицо неизменным. Драматичное освещение, высокий контраст чёрного и белого, готическая меланхолия. Кинематографично, как кадр из арт-хаус фильма. Холодный ветер, серое небо, одиночество.
Используйте для: фото артистичных меланхоличных образов на хэллоуин для девушек.

Промт для Шекспировской ведьмы
Промпт 5: Ведьма у котла
Молодая женщина в костюме ведьмы с остроконечной шляпой стоит на коленях в поле высокой сухой травы на закате. Она держит светящуюся волшебную палочку над маленьким чёрным котлом, из которого поднимается магический зелёный дым, закручивающийся спиралями. Рядом с котлом сидит маленькая грустная тыква-светильник с вырезанным лицом. Сохрани моё лицо неизменным. Туманная атмосфера, мягкое вечернее освещение, мистика и волшебство. Фотореалистично, кинематографичный стиль, высокая детализация.
Используйте для: классических фото ведьмы на хэллоуин с магическими элементами.

Промт для готического фото на Хэллоуин
Промпт 6: Болотная ведьма
Призрачный готический портрет таинственной женщины, стоящей по пояс в тёмном туманном болоте. Она носит длинное струящееся чёрное платье с кружевными деталями, длинные чёрные волосы спускаются на плечи. Макияж драматичный с бледной кожей и жирной чёрной помадой, создавая ведьминское эфирное присутствие. Голые деревья с искривлёнными ветвями маячат на фоне мрачного пасмурного неба. Сохрани моё лицо неизменным. Настроение мрачное, драматичное, кинематографичное с мягким фокусом и высокой детализацией. Холодные зелёные и серые тона.
Используйте для: жутких атмосферных страшных фото на хэллоуин.

Промт для чёрно-белого готического фото на Хэллоуин
Промпт 7: Пустынная дорога
Женщина с драматичным тёмным макияжем (чёрная помада, дымчатые глаза) в элегантном чёрном длинном платье идёт прямо к камере по пустынной дороге через мрачный зимний лес. Цвета сильно десатурированы, акцент на серое небо, белый снег и голые чёрные ветки деревьев. Сохрани моё лицо неизменным. Атмосфера меланхоличная, зловещая, одинокая, кинематографичная. Холодные тона, высокая детализация, как кадр из скандинавского хоррор-фильма.
Используйте для: артистичных минималистичных фото в стиле хеллоуин.
КАТЕГОРИЯ 2: Хоррор-персонажи (5 промптов)

Как сгенерировать фото клоуна на Хэллоуин в хоррор-стилистике
Промпт 8: Жуткий клоун
Грубый жёсткий портрет клоуна с грязным размазанным бело-чёрным гримом, ярко-красным носом и диким бирюзовым кудрявым париком. Он громко смеётся с закрытыми от смеха глазами, одет в рваную грязную бежевую футболку. Освещение драматичное на тёмном мрачном фоне, кинематографичное низкое ключевое освещение с резкими тенями. Сохрани моё лицо неизменным. Атмосфера напряжённая, тревожная, реалистичное фото. Зернистость плёнки для винтажного хоррор-эффекта.
Используйте для: интенсивных страшных фото на хэллоуин в хоррор-стиле.

Как сделать элегантное мужское фото на Halloween
Промпт 9: Классический Дракула
Мужчина в элегантном костюме Дракулы в драматичном хэллоуинском портрете. Узнаваемое чётко очерченное лицо с острыми скулами и пронзительным интенсивным взглядом. Классический костюм Дракулы: длинный чёрный плащ с высоким красным атласным воротником, белая рубашка с жабо, массивный золотой медальон на бордовой ленте на шее. Обстановка жуткая и атмосферная с тусклым мерцающим светом свечей, готическими каменными арками, клубящимся туманным фоном. Настроение зловещее, но элегантное и кинематографичное. Фотореалистичный стиль, высокое разрешение 4K, акцент на чёткости лица и деталях костюма. Сохрани моё лицо неизменным.
Используйте для: элегантных мужских образов на хэллоуин фото.

Промт готического фото для парней
Промпт 10: Страж кладбища
Призрачное хэллоуинское фото мужчины с узнаваемым лицом, стоящего на тускло освещённом старом кладбище ночью среди выветренных надгробий. Он одет в потрёпанный длинный чёрный плащ с капюшоном, бледная кожа и глубоко затенённые глаза. Вырезанная светящаяся тыква-светильник мерцает на надгробии рядом, отбрасывая жуткий тёплый оранжевый свет на его лицо, контрастирующий с холодным синим лунным светом. Сохрани черты лица неизменными. Атмосфера леденящая, но кинематографичная, сочетающая готический хоррор с классическим хэллоуинским шармом. Снято в драматичном низком освещении с резкими контрастами между глубокой тенью и тёплым светом огня. Туман стелется по земле между могилами.
Используйте для: атмосферных готических фото на хэллоуин ии для парней.

Промт для жуткого фото женщины на Хэллоуин
Промпт 11: Свет свечи под подбородком
Плотный клаустрофобный кадр женщины в полностью затемнённой комнате, освещённой только одной мерцающей свечой, которую она держит прямо под подбородком снизу. Свет свечи отбрасывает жуткие драматичные тени на её лицо снизу вверх. Она смотрит прямо в камеру неподвижным пристальным взглядом с тревожными полностью белыми или полностью чёрными контактными линзами. Сохрани моё лицо неизменным. Атмосфера напряжённая, клаустрофобная, классический хоррор. Всё погружено в глубокую черноту, кроме лица. Фотореалистично, высокий контраст.
Используйте для: минималистичных жутких фото привидений на хэллоуин.

Промт для психологических страшных фото на Хэллоуин
Промпт 12: Злое отражение
Женщина в белой винтажной кружевной ночной рубашке сидит перед своим старым туалетным столиком с овальным зеркалом. Она смотрит в зеркало с выражением страха и ужаса на лице, но её отражение в зеркале смотрит прямо в камеру (не на неё) со зловещей жуткой улыбкой и тёмным пустым взглядом. На стене позади неё тени гигантских чудовищных рук с когтями медленно ползут к ней по обоям. Сохрани моё лицо неизменным. Освещение приглушённое от одной прикроватной лампы, атмосфера жуткая, сюрреалистичная, кинематографичный психологический хоррор. Высокая детализация, фотореалистично.
Используйте для: сюрреалистичных психологических страшных фото на хэллоуин.
КАТЕГОРИЯ 3: Элегантные образы (5 промптов)

Промт под Уэнсдей на Хэллоуин
Промпт 13: Уэнсдей Аддамс
Модель в узнаваемом костюме Уэнсдей Аддамс: две аккуратные длинные косы, белый острый воротничок на чёрном готическом платье с длинными рукавами. Она присела на корточках в тёмном мрачном туманном лесу среди голых деревьев. Держит одну красную горящую свечу в старинном латунном подсвечнике и смотрит чуть в сторону от камеры с характерным бесстрастным или слегка печальным задумчивым выражением лица. Сохрани моё лицо неизменным. Атмосфера готическая, меланхоличная, кинематографичная. Туман стелется по земле, приглушённые холодные серо-синие тона, мягкое освещение. Высокая детализация, как кадр из атмосферного фильма.
Используйте для: стильных готических образов на хэллоуин для девушек фото в культовом стиле.

Промт для фото с тыквой в лесу
Промпт 14: Лесная фея с тыквой
Красивая молодая женщина с длинными волнистыми тёмными волосами в струящемся белом или кремовом лёгком платье изящно сидит на земле в осеннем лесу рядом с большой вырезанной хэллоуинской тыквой со светящимся изнутри лицом. Золотистые осенние листья разбросаны вокруг. Фото имеет профессиональное кинематографическое ощущение, малую глубину резкости с мягким размытым боке на фоне, создавая очаровательную сказочную эстетику хэллоуинской фотосессии. Сохрани моё лицо неизменным. Мягкое золотистое вечернее освещение, тёплые оранжевые тона, романтичная сказочная атмосфера без хоррора. Фотореалистично, высокое качество.
Используйте для: мягких романтичных красивых фото хэллоуин в сказочном стиле.

Промт фото с персонажами комиксов на Хэллоуин
Промпт 15: Харли Квинн
Эффектная женщина в детализированном костюме Харли Квинн в кинематографической ночной городской сцене, с платиново-русыми объёмными кудрявыми волосами, уложенными в игривые высокие хвостики — одна сторона окрашена в ярко-розовый, другая сторона в электрический синий. Она носит блестящую красно-синюю атласную куртку-бомбер поверх потрёпанной графической футболки, блестящие серебряные короткие шорты и широкий пояс с металлическими заклёпками. Она держит деревянную бейсбольную биту на плече, с интенсивным, но игривым дерзким выражением лица, яркая кроваво-красная помада и драматичная тёмная подводка глаз. Фон — неоново освещённая городская улица ночью с размытыми боке-огнями фонарей и драматичными тенями. Сохрани моё лицо неизменным. Ультра-реалистичная фотография, кинематографичное освещение, резкий фокус, насыщенные яркие неоновые цвета. 4K качество.
Используйте для: ярких современных образов на хэллоуин для девушек фото в стиле комиксов.

Промт гламурного фото на аватарку
Промпт 16: Готик-глэм под Instagram*
Кинематографический портрет загадочной женщины для Instagram*. Фон: туман, свечи, силуэты деревьев. Макияж элегантный: дымчатые глаза, красные губы, призрачный контуринг. Готический наряд: кружевной чокер, чёрное бархатное платье, серебряные украшения. Тыква-светильник отбрасывает оранжевые блики. Сохрани моё лицо неизменным. Тон жуткий, но гламурный, резкая детализация, малая глубина резкости, редакционное освещение. Качество как будто 4K, портретная ориентация.
Используйте для: гламурных модных фото на аву хэллоуин всокого качества.

Промт фото для профессиональной фотосъёмки на Хэллоуин
Промпт 17: Ведьминская модная съёмка
Профессиональная хэллоуинская фотосессия: стильная женщина позирует с вырезанной светящейся тыквой. Атмосфера жуткая и элегантная, свет свечей и тыкв отбрасывает оранжевое свечение на туманный фон. Тёмная ведьминская мода: чёрное платье, готические аксессуары, драматичный макияж с дымчатыми глазами. Выражение таинственное и игривое. Туманная лесная поляна в сумерках, осенние листья. Сохрани моё лицо неизменным. Эстетика: 4K, малая глубина резкости, мрачное освещение, десатурированная палитра с оранжево-чёрными контрастами.
Используйте для: профессиональных модных фото в стиле хэллоуин уровня глянцевых журналов.
КАТЕГОРИЯ 4: Винтажный хоррор (5 промптов)

Промт на Хэллоуин на кухне ретро-стиль
Промпт 18: Кухня 70-х с маньяком
Ретро-кухня 70-х к Хэллоуину: светящиеся тыквы на столешнице, попкорн, кукурузные конфеты, оранжевые гирлянды. Женщина в винтажной хоррор-футболке разговаривает по дисковому телефону, лицом к камере. В тёмном дверном проёме позади частично скрытая замаскированная фигура. Сохрани моё лицо неизменным. Тёплое освещение ламп накаливания, винтажные текстуры обоев и линолеума, напряжённая атмосфера классического слэшера. Зернистость плёнки. Стиль 70-х хоррор-фильмов.
Используйте для: ностальгических фото дома хэллоуин в ретро-стиле.

Промт на Хэллоуин девушка в гостиной
Промпт 19: Преследователь в гостиной
Гостиная к Хэллоуину: светящиеся тыквы на столике, лава-лампа, оранжевые гирлянды. Женщина в наушниках сидит в кресле, читает книгу. За стеклянной дверью снаружи в темноте стоит замаскированная фигура, силуэт едва различим. Сохрани моё лицо неизменным. Драматичный контраст тёплого света внутри и холодной темноты снаружи. Кинематографичная атмосфера напряжения. Фотореалистично.
Используйте для: напряжённых страшных фото на хэллоуин в стиле триллеров.

Промпт 20: Незваный гость в спальне
Спальня в ретро-стиле 70-80-х к Хэллоуину: бумажные привидения на стенах, светящиеся тыквы на тумбочке. Женщина лежит на кровати с пейсли-покрывалом, пользуется телефоном. В тёмном дверном проёме стоит замаскированная фигура в тени. Сохрани моё лицо неизменным. Мягкое освещение от прикроватной лампы, ностальгическая атмосфера. Напряжение как в классическом слэшере. Стиль ретро-хоррор 80-х, зернистость плёнки VHS.
Используйте для: винтажных фото в стиле хеллоуин в духе классических хоррор-фильмов.

Промт для фото с Чаки на Хэллоуин
Промпт 21: Друг Чаки
Подростковая спальня к Хэллоуину: неоновые огни (розовые, синие, фиолетовые), светящиеся тыквы, паутина, постеры хорроров. Женщина в радужном полосатом свитере и джинсовом комбинезоне держит огромный спиральный леденец. Рядом жуткая рыжеволосая кукла в комбинезоне с игрушечным ножом. Сохрани моё лицо неизменным. Неоновое освещение, драматичные цветные тени, контраст милой эстетики и хоррора. Современный поп-хоррор стиль.
Используйте для: ярких игривых фото на хэллоуин ии с элементами поп-культуры.

Как сделать фото на Хэллоуин в винтажной эстетике
Промпт 22: Винтажный 70-х Хэллоуин
Фотосессия в стиле 1970-х с женщиной в винтажной моде 70-х: макси-платье с цветочным узором в землистых тонах, туфли на платформе, причёска с начёсом. Она позирует рядом с вырезанной светящейся тыквой на деревянном крыльце. Сохрани моё лицо неизменным. Фото имеет вид снимка 70-х: выцветшие цвета плёнки Kodak, мягкая зернистость, тёплый оттенок, блик объектива. Пригородный дом в сумерках, опавшие листья, крыльцо с самодельными хэллоуинскими украшениями. Ностальгическая атмосфера семейного Хэллоуина 70-х.
Используйте для: аутентичных ностальгических фото в стиле хеллоуин в винтажной эстетике.
Бонус: как сделать видео на Хэллоуин
Подробный гайд по Соре тут: Нейросеть Sora 2 - официальный сайт на русском
Как создать идеальное фото в стиле Хэллоуин через нейросеть
Как сделать фото в нейросети хэллоуин за несколько минут, не тратя деньги на профессионального фотографа, костюмы и декорации? Современные нейросети научились создавать фотореалистичные изображения, которые выглядят как кадры из профессиональных хоррор-фильмов или готических фотосессий. Достаточно загрузить своё селфи и использовать правильный промт для фото в стиле хэллоуин, чтобы через 30-60 секунд получить фото привидений на хэллоуин, мистических ведьм или элегантных вампиров.
Какую нейросеть выбрать для создания фото на Хэллоуин
Для создания фото в стиле Хеллоуин лучше всего использовать вот эти три основные нейросети, каждая со своими особенностями:
>>> ChatGPT с DALL-E 3 — универсальный выбор для большинства задач. Отлично понимает промпты для нейросети для обработки фото хэллоуин на русском языке, минимально блокирует хоррор-контент и быстро генерирует изображения за 5-15 секунд. Идеально подходит для создания аватарки на Хэллоуин со своим фото, так как хорошо сохраняет черты лица.
>>> Nano Banana — лучший выбор для максимального реализма и точного сохранения черт лица. Эта нейросеть специализируется на редактировании реальных фотографий, поэтому если вам нужно вставить фото в хэллоуин-сцену с фотографической точностью, Нано Банана справится лучше всех. Генерация занимает 3-5 секунд, результат выглядит как настоящая профессиональная фотосессия.
>>> Midjourney — для художественных и стилизованных образов. Если вам нужны не столько реалистичные фото дома хэллоуин, сколько кинематографичные постеры в духе готических фильмов, Midjourney создаёт невероятно красивые композиции с драматичным освещением и атмосферой. Единственный минус — лицо может измениться сильнее, чем в других нейросетях.
Где создать фото на Хэллоуин без VPN
Сделать фото через нейросеть онлайн на тему "Хэллоуин" российским пользователям проще всего через платформу Study AI, которая объединяет более 30 нейросетей в одном месте (но для этой задачи нам понадобятся одна из этих: Nano Banana, Midjourney или ChatGPT). Не нужно настраивать VPN для каждого сервиса отдельно, искать способы обойти блокировки или разбираться с оплатой зарубежными картами — всё работает с российской карты в рублях, интерфейс полностью на русском языке, идеальный вариант для начинающих!
Преимущества создания фото на Хэллоуин с ИИ через Study AI:
1️⃣ Доступ сразу к 30+ топовым нейросетям в одном окне
2️⃣ Оплата российской картой
3️⃣ Техподдержка на русском языке
4️⃣ Работает без VPN из любого региона России
5️⃣ Все промты для фото на русском языке
Как подготовить исходное фото
Качество исходного селфи напрямую влияет на то, насколько хорошо получится сгенерировать фото в стиле хэллоуин. Вот чек-лист идеального фото для нейросети:
✅ Что нужно:
Хорошее равномерное освещение — естественный дневной свет или мягкий искусственный
Лицо занимает минимум 40% кадра, все черты чётко видны
Фото не размытое, без сильного «шума» или зернистости
Прямой взгляд в камеру или лёгкий полуоборот (3/4)
Один человек в кадре — групповые фото работают хуже
Формат JPG или PNG, разрешение от 512x512 пикселей
❌ Чего избегать:
Солнцезащитных очков или масок на лице
Тусклого освещения или резких теней
Селфи с фильтрами или сильной обработкой
Слишком далёкого ракурса (лицо мелкое в кадре)
Если у вас нет идеального селфи под рукой, можно сначала улучшить имеющееся фото через ту же Study AI в инструменте "Улучшение фото" с промтом «Улучши качество этого фото, сделай освещение ярче и чётче», а затем использовать улучшенную версию для создания всего, что можно сгенерировать на Хэллоуинское фото.
5 правил для идеальных промптов на Хэллоуин
Чтобы промт ии фото на Хэллоуин сработал идеально и вы получили именно то, что задумали, важно понимать, как правильно формулировать запросы для нейросети. Разница между посредственным и профессиональным результатом часто заключается всего в нескольких ключевых фразах в вашем промте для фото нейросети хэллоуин.
Правило 1: Всегда указывайте «Сохрани моё лицо неизменным»
Самая критичная ошибка при создании фото приведения на Хэллоуин или любого другого образа — забыть эту фразу. Без неё нейросеть может полностью заменить ваше лицо на сгенерированное, и результат не будет похож на вас. Добавляйте в конец каждого промпта для хэллоуин фото: «Сохрани моё лицо неизменным» или «Сохрани черты лица».
Правило 2: Детально описывайте атмосферу и освещение
Чем подробнее ваш промт для фото в стиле хэллоуин, тем лучше результат. Не пишите просто «ведьма в лесу» — опишите:
Освещение: «мягкий золотистый свет заходящего солнца», «драматичное освещение свечами», «холодный синий свет луны»
Атмосферу: «мистический туман стелется по земле», «жуткая, но элегантная обстановка», «кинематографичная напряжённая атмосфера»
Цвета: «приглушённые фиолетовые и оранжевые тона», «десатурированные холодные цвета», «глубокие чёрные с акцентами красного»
Детали: «опавшие осенние листья на земле», «паутина в углах», «мерцающие свечи на заднем плане»
Правило 3: Избегайте триггерных слов
При создании страшных фото на хэллоуин некоторые слова могут вызвать блокировку контента. Избегайте прямых упоминаний:
❌ «кровь», «нож», «убийство», «насилие», «gore»
✅ Вместо этого используйте: «драматичный», «напряжённый», «жуткий», «зловещий», «таинственный», «кинематографичный»
Например, вместо «ведьма с ножом» напишите «ведьма с древним артефактом» или просто опустите упоминание предметов, которые могут быть восприняты как оружие.
Правило 4: Используйте стилистические маркеры
Добавление стилистических указаний резко повышает качество фото в стиле хеллоуин:
«Фотореалистично» / «Photorealistic» — для максимально реалистичных фото
«Кинематографично» / «Cinematic» — для драматичных кадров как из фильмов
«Высокая детализация» / «High detail» — для проработки мелких элементов
«Атмосферное освещение» / «Atmospheric lighting» — для создания настроения
«Малая глубина резкости» / «Shallow depth of field» — для размытого фона как в профессиональной фотографии
«4K resolution» / «8K» — для максимального качества
Правило 5: Указывайте эмоции и выражение лица
Для фото ведьмы на хэллоуин или любого другого образа важно описать не только внешний вид, но и эмоциональное состояние:
«С загадочным выражением лица»
«Со спокойным и знающим взглядом»
«С лёгким беспокойством на лице»
«С бесстрастным выражением»
«С интенсивным пронзительным взглядом»
«С игривой, но жуткой улыбкой»
Это помогает нейросети понять, какую атмосферу вы хотите создать в промтах для генерации фото в стиле хэллоуина, и делает образ более выразительным.
Бонус-совет: Пробуйте разные нейросети
Если промт для фото нейросети Хэллоуин не сработал в одной нейросети, попробуйте в другой. ChatGPT может заблокировать то, что спокойно пропустит Nano Banana, а Midjourney создаст более художественную версию того же промпта.
В Study AI все три нейросети доступны в одном месте, так что переключиться между ними можно за секунду.
Где и как использовать готовые фото в стиле Хэллоуин
Создали идеальное фото в стиле хэллоуин? Теперь важно правильно использовать его, чтобы собрать максимум лайков, просмотров и восхищённых комментариев. В Хэллоуин 2025 года фото являются неотъемлемой частью цифровой культуры праздника — миллионы людей делятся своими идеями фото на хэллоуин в соцсетях, создавая вирусный контент.
Лучшие платформы для публикации
Визуальные соцсети типа Instagram* — главная платформа для красивых фото хэллоуин. Публикуйте в основную ленту как посты-карусели (несколько образов подряд), Stories с интерактивными стикерами и Reels с драматичной музыкой из хоррор-фильмов. Используйте хештеги: #halloween2025 #halloweenai #хэллоуин2025 #фотонахэллоуин #aihalloween #spookyseason.
TikTok — идеально для фото на хэллоуин ии в формате слайд-шоу с трендовыми звуками. Покажите процесс создания («до и после»), сравните разные промпты или создайте челлендж для подписчиков. TikTok алгоритм особенно любит хэллоуинский контент в октябре.
VK Клипы и Истории — для русскоязычной аудитории. Публикуйте фото на аву хэллоуин как временную аватарку на октябрь, делитесь в сообществах по интересам, создавайте тематические подборки.
Pinterest — долгосрочное хранилище для что можно нарисовать на хэллоуин фото-идей. Ваши образы будут появляться в поисковой выдаче круглый год, когда люди ищут вдохновение для следующего Хэллоуина.
Идеи для контента
Трансформация «До/После» — покажите исходное селфи и готовое фото ведьмы на хэллоуин. Это всегда набирает просмотры.
Сравнение нейросетей — создайте одинаковый образ в ChatGPT, НаноБанана и Midjourney, покажите разницу. Образовательный контент хорошо вирусится.
Серия образов — не ограничивайтесь одним фото. Создайте тематическую серию: «7 дней Хэллоуина — 7 образов».
Приглашения на вечеринку — используйте фото дома Хэллоуин или готические портреты как основу для цифровых приглашений.
Обои и аватарки — аватарка на Хэллоуин со своим фото — отличный способ показать праздничное настроение. Делитесь версиями в разных разрешениях для телефонов и компьютеров.
5 ошибок при создании фото на Хэллоуин через нейросеть
Даже с готовыми промптами для фото хэллоуин можно совершить ошибки, которые испортят результат. Разберём самые частые проблемы и способы их избежать.
Ошибка 1: Плохое исходное фото
Размытое селфи, плохое освещение, лицо в тени — нейросеть не сможет сгенерировать фото в стиле хэллоуин качественно. Используйте чёткие фото с хорошим освещением или предварительно улучшите их.
Ошибка 2: Забыли «Сохрани моё лицо»
Без этой фразы фото приведения на Хэллоуин будет с чужим лицом. Всегда добавляйте «Сохрани моё лицо неизменным» в конец промпта.
Ошибка 3: Перегруженный промпт
Слишком много деталей запутывает нейросеть. Используйте готовые проверенные промты для нейросети для обработки фото Хэллоуин из нашей статьи.
Ошибка 4: Неправильная нейросеть
Если одна нейросеть заблокировала промт ии фото на Хэллоуин, попробуйте другую. В Study AI легко переключаться между ChatGPT, Nano Banana и Midjourney.
Ошибка 5: Не экспериментируете
Не бойтесь адаптировать промпты под себя! Меняйте цвета, локации, детали одежды — создавайте уникальные фото образы на Хэллоуин для девушек .
Создайте свою хэллоуинскую магию прямо сейчас!
Теперь у вас есть всё необходимое для создания профессиональных фото в стиле хэллоуин. Все промты для генерации фото в стиле Хэллоуина работают в ChatGPT, Nano Banana и Midjourney.
Что делать дальше:
Выберите понравившийся промпт из 22 готовых вариантов
Зайдите на Study AI и выберите нейросеть (рекомендуем начать с ChatGPT или Nano Banana)
Загрузите своё чёткое селфи с хорошим освещением
Скопируйте промпт и нажмите «Генерировать»
Через 30-60 секунд получите своё фото на хэллоуин ИИ
Поделитесь результатом в Instagram*, TikTok или VK с хештегами #halloween2025 #хэллоуин2025 #aihalloween
Хэллоуин 2025 — это не просто праздник, а настоящий фестиваль цифрового творчества, где каждый может стать героем готической сказки или хоррор-фильма. Искусственный интеллект для фото на Хэллоуин открывает безграничные возможности для самовыражения — от элегантных образов для девушек до жутких страшных фото на Хэллоуин.
Не бойтесь экспериментировать, адаптируйте промты под свой стиль, создавайте уникальные идеи фотографий на Хэллоуин и делитесь ими с миром. Самое время сделать фото на Хеллоуин, которое запомнится надолго! 🎃✨👻
Делитесь результатами с хештегами:
#фотовстилехэллоуин #хэллоуин2025 #halloweenai #фотонахэллоуин #промтыдляхэллоуина #aiфото #нейросетьфото #spookyseason #готическийстиль
*Instagram (принадлежит Meta, признанной экстремистской и запрещенной на территории РФ)
Показать полностью
22
1

Поднимаем свой n8n: Полный гайд по комфортной и надежной установке

Я несколько раз поднимал n8n у себя. И каждый раз думал: почему базовая установка вроде работает, но ощущается… как тестовый стенд? Логов нет, база тормозит, интерфейс отваливается через пару дней. А потом понял – не сам n8n виноват, а настройки по умолчанию.
Если вы хотите не просто “запустить”, а работать с n8n как с надёжным инструментом, стоит уделить внимание конфигурации. Ниже – мой практичный чеклист с пояснениями, зачем включать или отключать каждую опцию.
Коротко про способы установки
Существует несколько способов установить n8n, включая npm. Но давайте договоримся сразу: если вы строите систему для работы, а не для тестов на один вечер, ваш выбор – Docker.
Почему? Все просто:
Изоляция: n8n и все, что ему нужно для работы (база данных, Redis и т.д.), живут в своих изолированных «контейнерах». Они не конфликтуют с другими программами на вашем сервере и не оставляют мусора в системе.
Воспроизводимость: Вся конфигурация вашей системы описывается в одном простом файле – docker-compose.yml. Вы можете взять этот файл, перенести на любой другой сервер, выполнить одну команду и получить точную копию вашей системы за пять минут.
Простота обновления: Вышла новая версия n8n? Вы выполняете docker-compose pull и docker-compose up -d – и все обновлено. Никаких ручных манипуляций с файлами и зависимостями.
Сборка: от базового запуска до production-конфигурации
Предполагается, что у вас уже есть чистый сервер (например, VPS на Ubuntu 22.04) и вы можете подключиться к нему по SSH.
Я рекомендую изучить материал: Гайд по Coolify: Как развернуть n8n и Supabase на одном VPS за вечер – там достаточно подробно рассмотрено, чем вам может быть полезен Coolify и как устанавливать сервисы по типу n8n в один клик на своём VPS.
Базовая среда и работа с окружением
Самая частая ошибка – поднять контейнер и радоваться, пока он работает. Но чтобы потом не ловить баги “из ниоткуда”, стоит сразу поправить несколько переменных окружения.
NODE_ENV=production
GENERIC_TIMEZONE=Europe/Moscow
EXECUTIONS_DATA_PRUNE=true
EXECUTIONS_DATA_PRUNE_MAX_COUNT=10000
NODE_ENV – в dev-режиме n8n ведёт себя иначе: меньше оптимизаций, медленнее отклик, иногда включен дебаг. В продакшене это просто лишнее.
GENERIC_TIMEZONE – Пока не поставите свой часовой пояс, все расписания будут сдвигаться. Особенно заметно, если вы триггерите задачи по времени – cron в UTC, вы в МСК, а воркфлоу срабатывает в 3 ночи.
EXECUTIONS_DATA_PRUNE – Если не включить очистку старых записей, база раздуется до гигабайтов.
Но есть нюанс: если вы активно тестируете сценарии – лучше временно выключить prune, чтобы не потерять логи.
Безопасность
n8n не хранит токены в открытом виде, но это не повод раздавать доступ всем.
Минимальный набор для спокойной работы выглядит примерно так:
N8N_BASIC_AUTH_ACTIVE=true
N8N_BASIC_AUTH_USER=admin N8N_BASIC_AUTH_PASSWORD=your_secure_password N8N_SECURE_COOKIE=true
N8N_DIAGNOSTICS_ENABLED=false N8N_VERSION_NOTIFICATIONS_ENABLED=false
Базовая авторизация – обязательна. Даже если вы на localhost, привычка “ставить пароль” спасает от случайных вторжений.
SECURE_COOKIE=true – если у вас HTTPS, это защита от кражи сессии. Без неё браузер может отправлять cookie даже в небезопасных запросах.
Отключаем телеметрию.
n8n по умолчанию отправляет анонимные данные разработчикам (версии, события). Не критично, но для своих установок это просто лишняя нагрузка.
Логи, бэкапы и обновления
Хуже всего, когда n8n падает тихо. Без логов вы не узнаете почему.
Пара строк решает вопрос:
N8N_LOG_LEVEL=info
N8N_LOG_OUTPUT=file
N8N_LOG_FILE_LOCATION=/home/node/.n8n/logs/
Теперь вы хотя бы увидите, почему сценарий “вдруг перестал работать”.
warn, error, debug – можете также переключить на нужный уровень в случае необходимости.
Бэкапы — три папки:
.n8n – ваши воркфлоу и креды,
postgres_data – база,
docker-compose.yml – вся инфраструктура в одном месте.
Обновление занимает 10 секунд:
docker-compose pull && docker-compose up -d
Но перед этим всё же протестируйте на копии – иногда меняется структура БД, либо пользуйтесь удобной командой из Coolify.
Масштабирование: Redis и worker-режим
Когда воркфлоу начинают тормозить, первое желание – включить Redis и worker.
Но тут важно понимать: это не про ускорение, а про устойчивость.
EXECUTIONS_MODE=queue
QUEUE_BULL_REDIS_HOST=redis
QUEUE_BULL_REDIS_PORT=6379
QUEUE_HEALTH_CHECK_ACTIVE=true
Режим queue распределяет выполнение задач между воркерами – полезно, если вы гоняете десятки сценариев параллельно.
Если же у вас один сервер и 10 сценариев – worker-режим только усложнит жизнь.
Мой принцип: “Добавляй Redis, когда CPU стабильно в 80%”. Раньше просто рано.
Error workflow
Что это: отдельный воркфлоу, который автоматически срабатывает, когда любой другой воркфлоу падает. По сути – централизованный обработчик ошибок. n8n поддерживает «Error workflows» через Error Trigger/триггер ошибок.
Зачем: не нужно вручную мониторить executions; вы получаете контекст ошибки (какой воркфлоу, какие данные, где упало), можно сразу уведомить ответственных и логгировать данные для разбирательства.
Как настроить минимально полезный набор можно почитать подробнее тут.
2FA – включать или нет
Зачем: пароль – слабая линия защиты. Если вы открываете n8n в интернет (даже через домен), 2FA резко снижает риск взлома.
Как включить (опции):
Встроенная MFA (если доступна у вашей версии): проверьте N8N_MFA_ENABLED и включите у пользователей из UI/аккаунтов.
Лучший вариант для self-hosted (часто используемый): ставите аутентификацию на уровне reverse-proxy / identity provider (Keycloak / OAuth2-proxy). Это даёт SSO, централизованную 2FA и больше контроля (блокировка IP, MFA политики).
Практический вывод: если вам нужен надёжный 2FA – делайте это на уровне прокси/IdP; встроенная MFA – полезна, но на неё нельзя полностью полагаться как на единственный механизм защиты для критичных инстансов.
Другие вещи, которые стоит сделать сразу после установки
Защита вебхуков и публичных эндпоинтов
Используйте секреты в URL или проверку HMAC в запросах, если сервис поддерживает.
Если вебхуки публичны, добавьте rate-limiting на прокси и проверку подписей.
Зачем: webhook – это дверь в ваш n8n; без подписи чужой запрос может запустить процесс.
Перехват ошибок на уровне нодов
В каждом узле есть настройка Continue on fail / Execute on error – используйте её осознанно: если в цепочке есть «необязательный» шаг, разрешите продолжить, чтобы не ломать весь процесс.
Зачем: иногда полезно продолжить обработку, даже если один внешний сервис временно недоступен.
Мониторинг и алерты
Настройте health check (пинг-эндпоинт), базовую метрику CPU/memory и алерт в случае падения контейнера.
Включите QUEUE_HEALTH_CHECK_ACTIVE если используете очередь, и мониторьте Redis/DB.
Зачем: знать о проблеме раньше, чем начнут писать пользователи.
Версионирование и testing
Держите копию production-DB/compose для тестирования новых версий n8n. Это достаточно молодой инструмент и новые изменения могут сломать все ваши текущие наработки.
Зачем: новая версия может неожиданно изменить поведение работы нод и сломать ваши workflow.
Небольшой вывод
Неважно, где вы развернули n8n – на VPS, NAS или локалке. Важно, чтобы система была прозрачна, предсказуема и безопасна.
Для меня n8n давно уже не просто no-code. Это личная инфраструктура автоматизации. И как любая инфраструктура, она требует чуть-чуть инженерной заботы.
Показать полностью