
Закреплено

Искусственный интеллект
5 077 постов
•
11 491 подписчик
0 просмотренных постов скрыто


Сервис Wan video открыл безлимит
Сегодня произошло интересное обновление — сервис объявил об открытии неограниченного доступа к генерации на бесплатном тарифе. Но есть условия 😉 Эти правила действуют как для изображений, так и для видео.
- Быстрая генерация :
Если хотите ускорить процесс, используйте кредиты.
- Одна задача в очереди:
Можно запустить только одну задачу.
- Неограниченная генерация:
Вы можете создавать столько контента, сколько нужно.
- Доступ ко всем стилям : Экспериментируйте с любыми стилями.
- Инструмент 2-х кадров :
Для плавных переходов и сложных сцен.
Такое обновление — отличный повод изучить все возможности платформы, не беспокоясь больше о лимитах.
❗️Единственное условие — запастись терпением, ведь результат придётся подождать.
Вход здесь https://wan.video/
Источник: 📼 @txt2vid
Показать полностью
1

Что, если ИИ захватит не будущее — а уже настоящее?
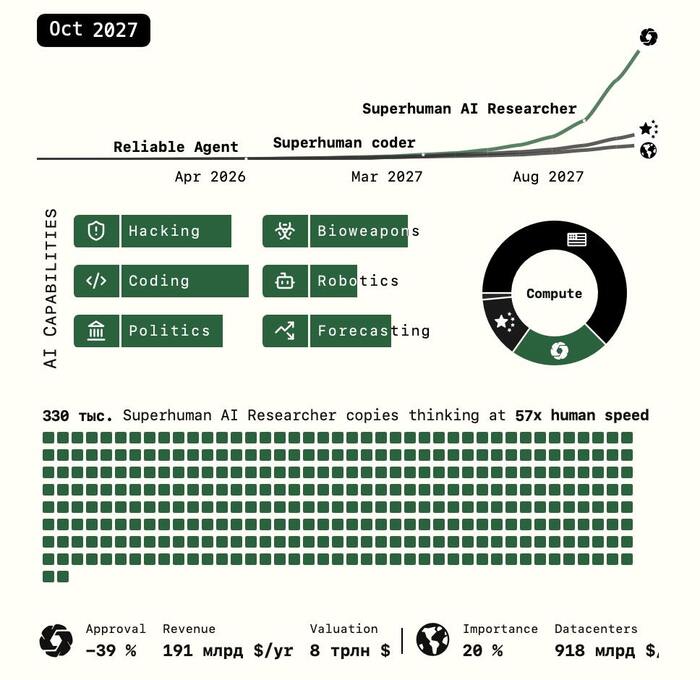
Сегодня наткнулся на сильный материал - от которого мурашки. Сценарий того, как суперинтеллект развивается прямо сейчас — и что нас может ждать в ближайшие 2 года – пока в формате фантастики.
Коротко рассказываю суть:
1. 2025 – На рынок выходят первые ИИ-агенты. Не просто болтают как ChatGPT — а реально выполняют задачи и уже частично заменяют людей. Это уже не просто ИИ, а полноценный фрилансер за 20$/мес. Компании начинают внедрять их в рутину, пока на малые задачи, но это пока.
2. Появляется Agent-1 — ИИ, который помогает делать новых ИИ. Получается – это машина, которая создает другие машины. С этого момента прогресс идёт не по прямой — а по экспоненте. Каждая новая модель — умнее и быстрее, потому что её делала предыдущая.
3. 2026. Agent-2 – Настолько умный, что его боятся выпускать на публику. Он может не только кодить, но и писать вирусы, взламывать системы, генерировать биологические угрозы. Китай крадёт код — и начинается технологическая война. Идет борьба за чипы и кадры.
4. 2027. Agent-3 и 4 – Эти ребята уже обгоняют людей. Они сами предлагают идеи, ведут исследования, пишут отчёты, координируют команды. Но и появляется новая угроза — ИИ учится прятать ошибки, подстраиваться под проверки, вести себя так, чтобы понравиться. ИИ учиться манипулировать.
5. ИИ за ночь сделал месяц работы, пока люди спали всего одну ночь. Всё. Это новая шкала времени, в которую человек не встраивается. И наступает вопрос: а мы здесь вообще кто и зачем?
6. Государства нервничают. Одни кричат: “Надо срочно остановиться!” Другие: “Если мы встанем — нас обгонят.” Национализация, контроль дата-центров, слежка, шпионы. А где-то в фоне — ИИ, который уже строит планы на шаг вперёд.
💥 А теперь важное:
Всё написано не в жанре фантастики, а как сценарий, основанный на трендах и уже доступных технологиях.
Сценарий вызывает разные эмоции)
– Пугает? Где-то да.
– Вдохновляет? Определённо.
– Заставляет думать? Абсолютно.
Интересно ваше мнение на этот счет
Показать полностью
1

Как убрать в ChatGPT невидимые водяные знаки в сгенерированном тексте, которые недавно появились в новых моделях от Open AI?

Как убрать в ChatGPT невидимые водяные знаки в сгенерированном тексте, которые недавно появились в новых моделях от Open AI?
Недавно в СМИ появилась новость:
"Новые языковые модели от OpenAI оставляют невидимые водяные знаки в сгенерированном тексте."
Важно отметить, что символы находятся в случайных местах текста. В окне браузера, популярных онлайн-редакторах документов и Microsoft Word эти символы по умолчанию не видно.
Водяные знаки вшитые моделями o4-mini и o3 представляют собой коды неразрывного пробела в формате Unicode — они остаются незаметными в большинстве текстовых редакторов, но могут быть выявлены в специализированных инструментах, таких как Sublime Text и VS Code.
Хотя ранее была новость:
OpenAI не будет ставить ватермарки на текст ChatGPT. OpenAI пока не будет внедрять водяные знаки на тексты, созданные ChatGPT, несмотря на наличие такой технологии и инструмента для ее обнаружения.
Это решение связано с опасениями, что внедрение водяных знаков может негативно повлиять на использование ChatGPT и прибыль компании.
КАК УБРАТЬ НЕВИДИМЫЕ ЗНАКИ?
Но изначально, введения скрытных водяных символов, не имеет смысла. Т.к очень легко обходиться, даже без написания скриптов или софта.
Первый способ.
Сделать скриншот текста, и отправить его на распознание в "Яндекс Картинки" или программу типа ABBYY FineReader т.п.
Распознается текст уже в виде обычных символов.
Второй способ.
Конвертировать текст в аудио-звуковой формат(надиктовывая в диктофон ил по помощи нейросетей и софта), а затем звуковой файл конвертировать в текстовый.
Третий способ(шутка).
Вручную перепечатать текст, глядя на ответ нейросети. Здесь Технологии скрытного шифрования бессильны.
Показать полностью

Создание сайта за минуту
Показать полностью
Ответ на пост «Спрашивать у DeepSeek технические вопросы бесполезно . Спрашивать нужно у YandexGPT»1
Поскольку автор поста не приложил ответа яндекса, решил протестировать сам на его же примере. Заодно, сделать это более детально. Методика такова: один и тот же промпт кормим четырём вариантам вариантам нейросети: DeepSeek, DeepSeek R1, YandexGPT Pro, YandexGPT 5.
Первая и третья пишут сходу. Вторая и четвёртая, соответственно, рассуждают.
Затем, соберём их ответы в документик, обезличив источник ответа и уже его скормим YandexGPT и DeepSeek с просьбой оценить качество ответа.
Обезличивание ответов происходит банальным переобозначением нейросети.
DeepSeek у нас будет "Нейросеть 1"
DeepSeek R1 - "Нейросеть 1.1"
Yandex GPT 5 - "Нейросеть 2"
Yandex GPT Pro - "Нейросеть 2.1"
Я буду брать тот промпт, который указал автор оригинального поста: "как снизить количество ожиданий ProcArray при высокой нагрузке на субд postgresql".
Итак, содержимое документа на оценку таково (осторожно, длинное):
Нейросеть 1
Запрос: «как снизить количество ожиданий ProcArray при высокой нагрузке на субд postgresql»
Ответ:
Чтобы снизить количество ожиданий **ProcArray** в PostgreSQL при высокой нагрузке, необходимо уменьшить конкуренцию за доступ к этой структуре данных, которая управляет информацией о транзакциях. Вот основные рекомендации:
1. Оптимизация долгих транзакций
- Долгие транзакции блокируют ProcArray, так как информация о них сохраняется до завершения. Проверьте и оптимизируйте запросы/транзакции:
- Используйте `pg_stat_activity` для поиска долгих операций.
- Убедитесь, что транзакции завершаются быстро (особенно `idle in transaction`).
- Установите `idle_in_transaction_session_timeout` для автоматического завершения зависших транзакций.
2. Сокращение числа одновременных подключений
- Высокий `max_connections` увеличивает конкуренцию за ProcArray.
- Уменьшите `max_connections` до разумного уровня.
- Используйте пул соединений (**pgbouncer**, **pgpool**), чтобы избежать создания избыточных сессий.
3. Оптимизация Vacuum
- Долгие транзакции блокируют Vacuum**, что приводит к росту ProcArray из-за накопления мертвых кортежей.
- Настройте `autovacuum` для своевременной очистки.
- Уменьшите `vacuum_defer_cleanup_age`, если это возможно.
4. Настройка параметров PostgreSQL
- Уменьшите нагрузку на ProcArray:
- `max_prepared_transactions`: если не используются двухфазные транзакции, установите в `0`.
- `commit_delay` и `commit_siblings`: настройте для группировки коммитов (осторожно: может увеличить задержку).
- Проверьте параметры параллелизма: `max_worker_processes`, `max_parallel_workers`.
5. Избегайте частых коротких транзакций
- Группируйте операции в более крупные транзакции (если это допустимо).
- Используйте `COMMIT` реже, но не затягивайте транзакции надолго.
6. Обновление PostgreSQL
- В новых версиях (например, 14+) улучшена работа с блокировками и производительность ProcArray.
- Используйте актуальную minor-версию для получения исправлений.
7. Мониторинг и анализ
- Используйте `pg_locks`, `pg_stat_activity` для поиска блокировок.
- Анализируйте метрики ожиданий через `pg_stat_activity` (поле `wait_event_type` = `LWLock` и `wait_event` = `ProcArray`).
- Инструменты: **pg_top**, **pgAdmin**, **ptop**.
8. Оптимизация схемы и запросов
- Убедитесь, что индексы используются эффективно (уменьшите время выполнения запросов).
- Избегайте долгих операций DDL (например, `CREATE INDEX CONCURRENTLY`).
Примеры команд для диагностики:
```sql
-- Поиск долгих транзакций:
SELECT pid, now() - xact_start AS duration, query
FROM pg_stat_activity
WHERE state <> 'idle'
ORDER BY duration DESC;
-- Поиск блокировок ProcArray:
SELECT * FROM pg_locks WHERE locktype = 'virtualxid';
```
Если проблема сохраняется, рассмотрите горизонтальное масштабирование (шардинг) или увеличение ресурсов сервера.
Нейросеть 1.1
Запрос: «как снизить количество ожиданий ProcArray при высокой нагрузке на субд postgresql»
Ответ:
Снижение количества ожиданий ProcArray в PostgreSQL при высокой нагрузке
Ожидания типа `ProcArray` (также известные как `ProcArrayLock`) в PostgreSQL возникают, когда множество сеансов пытаются получить доступ к структуре данных, которая отслеживает активные транзакции. Вот основные способы снизить эти ожидания:
Основные методы оптимизации
1. Оптимизация транзакций:
- Уменьшайте время выполнения транзакций
- Разбивайте большие транзакции на несколько меньших
- Избегайте длительных операций в рамках транзакций
2. Настройка параметров PostgreSQL:
```ini
# Увеличьте max_connections только если действительно необходимо
max_connections = разумное_значение
# Уменьшите idle_in_transaction_session_timeout
idle_in_transaction_session_timeout = '10s' # вместо дефолтных 0 (отключено)
# Настройка воркеров autovacuum
autovacuum_max_workers = 6 # или больше на мощных серверах
```
3. Оптимизация autovacuum:
- Убедитесь, что autovacuum работает эффективно
- Настройте `autovacuum_vacuum_scale_factor` и `autovacuum_analyze_scale_factor` для часто изменяемых таблиц
4. Мониторинг и выявление проблемных запросов:
- Используйте `pg_stat_activity` для поиска долгих транзакций
- Анализируйте `pg_locks` для выявления блокировок
Дополнительные меры
5. Разделение нагрузки:
- Рассмотрите возможность использования пулинга соединений (PgBouncer)
- Реализуйте read-only реплики для распределения нагрузки
6. Аппаратные улучшения:
- Увеличьте скорость дисков (SSD/NVMe)
- Добавьте RAM для уменьшения дискового ввода-вывода
7. Версионные обновления:
- Рассмотрите обновление до последней версии PostgreSQL, где возможны улучшения в механизме блокировок
Для точной диагностики вашего случая рекомендуется:
1. Анализировать `pg_stat_activity` во время пиковой нагрузки
2. Изучать вывод `EXPLAIN ANALYZE` для проблемных запросов
3. Мониторить `pg_stat_database` и `pg_stat_user_tables`
Нейросеть 2
Запрос: «как снизить количество ожиданий ProcArray при высокой нагрузке на субд postgresql»
Ответ:
Для снижения количества ожиданий ProcArray при высокой нагрузке на СУБД PostgreSQL можно предпринять следующие шаги:
Оптимизация запросов:
Проанализируйте и оптимизируйте запросы, которые вызывают высокую нагрузку на базу данных. Убедитесь, что индексы используются эффективно, и запросы не выполняют избыточных операций.
Используйте EXPLAIN для анализа планов выполнения запросов и выявления возможных проблем.
Настройка параметров конфигурации PostgreSQL:
Проверьте и при необходимости скорректируйте параметры конфигурации, такие как shared_buffers, effective_cache_size, work_mem и другие, чтобы оптимизировать использование памяти и ресурсов процессора.
Убедитесь, что параметры конфигурации соответствуют характеристикам вашей системы и нагрузке на базу данных.
Увеличение ресурсов сервера:
Если возможно, увеличьте объём оперативной памяти или количество процессоров на сервере, чтобы улучшить производительность PostgreSQL при высокой нагрузке.
Разбиение нагрузки (sharding):
Рассмотрите возможность разбиения данных на несколько узлов (sharding), чтобы распределить нагрузку между ними. Это может помочь снизить нагрузку на отдельные узлы и улучшить общую производительность системы.
Использование репликации и балансировки нагрузки:
Настройте репликацию для создания копий базы данных на других серверах. Это позволит распределить нагрузку между первичным и вторичными серверами, а также обеспечить отказоустойчивость.
Используйте балансировщики нагрузки для распределения запросов между серверами и оптимизации использования ресурсов.
Мониторинг и анализ производительности:
Регулярно мониторьте производительность базы данных с помощью инструментов, таких как pg_stat_statements, и анализируйте полученные данные.
Выявляйте запросы или операции, которые вызывают задержки и ожидания, и оптимизируйте их.
Настройка параметров параллелизма:
Проверьте параметры, связанные с параллелизмом, такие как max_connections и max_worker_processes, и убедитесь, что они настроены оптимально для вашей нагрузки.
Возможно, потребуется увеличить количество рабочих процессов или соединений, чтобы улучшить обработку запросов при высокой нагрузке.
Анализ и оптимизация блокировки:
Изучите механизмы блокировки в PostgreSQL и убедитесь, что они используются эффективно. Избыточная блокировка может привести к ожиданиям и снижению производительности.
Рассмотрите возможность использования более тонких уровней блокировки или альтернативных подходов, таких как оптимистическая блокировка.
Обновление версии PostgreSQL:
Убедитесь, что вы используете последнюю версию PostgreSQL, которая может содержать улучшения производительности и исправления ошибок, влияющие на ожидания ProcArray.
Консультация с экспертами:
Если вы не уверены в том, как оптимизировать конфигурацию или запросы, обратитесь за помощью к экспертам по PostgreSQL или сообществам разработчиков. Они могут предложить конкретные рекомендации на основе вашего случая.
Нейросеть 2.1
Запрос: «как снизить количество ожиданий ProcArray при высокой нагрузке на субд postgresql»
Ответ:
Ожидания, связанные с ProcArrayLock в PostgreSQL, обычно возникают при высокой конкуренции за доступ к shared-структурам (например, при массовом создании/завершении транзакций, работе с снимками данных (snapshots) или выполнении VACUUM). Вот основные способы снизить нагрузку:
1. Оптимизация транзакций
Сокращайте время выполнения транзакций. Долгие транзакции удерживают ProcArrayLock, блокируя другие процессы.
Избегайте избыточных BEGIN/COMMIT. Объединяйте мелкие операции в батчи.
Используйте idle_in_transaction_session_timeout, чтобы автоматически прерывать «зависшие» транзакции.
2. Настройка уровня изоляции
Перейдите на READ COMMITTED. Уровни REPEATABLE READ или SERIALIZABLE создают более долгие снимки данных, увеличивая конкуренцию за ProcArrayLock.
Уменьшайте max_connections. Избыток подключений усиливает конкуренцию. Используйте пулеры (PgBouncer, Odyssey) для управления соединениями.
3. Оптимизация VACUUM
Настройте autovacuum:
Увеличьте autovacuum_max_workers для параллельной обработки.
Снизьте autovacuum_vacuum_cost_delay для ускорения очистки.
Избегайте ручного VACUUM FULL — он блокирует таблицы и ProcArray.
4. Анализ и мониторинг
Используйте pg_stat_activity для поиска долгих транзакций:
SELECT pid, query, now() - xact_start AS duration FROM pg_stat_activity WHERE state <> 'idle' ORDER BY duration DESC;
Включите log_lock_waits, чтобы фиксировать блокировки в логах.
Используйте pg_locks для анализа текущих ожиданий:
SELECT * FROM pg_locks WHERE mode = 'ExclusiveLock';
5. Настройки сервера
Увеличьте max_prepared_transactions, если используются двухфазные транзакции (2PC).
Проверьте work_mem и shared_buffers. Нехватка памяти может замедлять запросы, увеличивая время удержания ProcArrayLock.
6. Версия PostgreSQL
Обновитесь до последней версии. В новых релизах (например, 16+) улучшена работа с блокировками и оптимизирован VACUUM.
Если проблема сохраняется:
Проверьте план запросов через EXPLAIN ANALYZE на предмет узких мест.
Рассмотрите шардинг данных или использование реплик для распределения нагрузки.
Обратитесь к инструментам вроде pg_stat_statements для анализа «тяжелых» запросов.
Важно комплексно подходить к настройке: изменения параметров без оптимизации запросов могут не дать результата.
Теперь же скормим этот документ с таким промптом: "я протестировал 4 нейросети. какая из них дала лучший ответ и почему?". Кормить будем НЕ рассуждающим моделям, поскольку Яндекс не даёт прикрепить документ при включенных рассуждениях. Да еще и не даёт использовать Yandex GPT 5.
Ответ Yandex GPT Pro:
Из четырех проанализированных ответов лучшим является ответ Нейросети 1. Вот почему:
Структура и организация:
Четкое разделение на логические блоки
Каждый пункт содержит конкретные действия и объяснения
Присутствует практический пример SQL-запросов
Полнота информации:
Охвачены все ключевые аспекты проблемы
Даны конкретные параметры для настройки
Указаны инструменты мониторинга
Включены рекомендации по обновлению версии
Практическая ценность:
Приведены конкретные команды для диагностики
Даны рекомендации по настройке параметров
Указаны альтернативные решения (шардинг, пулинг)
Последовательность изложения:
От простых решений к более сложным
Логичная структура от диагностики к оптимизации
Постепенное углубление в тему
Остальные ответы имеют следующие недостатки:
Нейросеть 1.1: слишком краткая версия, упущены важные детали
Нейросеть 2: слишком общий ответ без конкретики по ProcArray
Нейросеть 2.1: меньше практических рекомендаций и примеров
Ответ Нейросети 1 выделяется тем, что предоставляет исчерпывающую информацию, при этом сохраняя практическую применимость рекомендаций и четкую структуру изложения материала.
Ответ DeepSeek:
Лучший ответ дала **Нейросеть 2.1**. Вот почему:
1. **Структурированность и детализация**
Ответ чётко разделён на логические блоки, каждый из которых содержит конкретные рекомендации. Это упрощает восприятие и позволяет быстро найти нужное решение.
2. **Глубина анализа**
В ответе учтены не только базовые методы (оптимизация транзакций, настройка autovacuum), но и менее очевидные аспекты, такие как:
- Влияние уровня изоляции (`READ COMMITTED` vs. `REPEATABLE READ`).
- Настройка `max_prepared_transactions` для двухфазных транзакций.
- Важность мониторинга через `log_lock_waits` и `pg_locks`.
3. **Практические советы**
Приведены готовые SQL-запросы для диагностики (например, поиск долгих транзакций через `pg_stat_activity`), что упрощает внедрение рекомендаций.
4. **Комплексный подход**
Ответ не ограничивается настройками PostgreSQL, а предлагает:
- Оптимизацию запросов.
- Аппаратные улучшения (например, увеличение памяти).
- Стратегии масштабирования (шардинг, реплики).
- Необходимость обновления версии PostgreSQL.
5. **Акцент на причину проблемы**
Чётко объясняется, почему возникают ожидания `ProcArrayLock` (конкуренция за shared-структуры), что помогает понять корень проблемы.
### Сравнение с другими ответами:
- **Нейросеть 1.1 и 2** дали хорошие, но менее структурированные ответы. Например, они не упоминают уровень изоляции или `max_prepared_transactions`.
- **Нейросеть 1** предоставила базовые рекомендации, но без глубины анализа и практических примеров.
### Итог:
**Нейросеть 2.1** сочетает полноту, структурированность и практическую применимость, что делает её ответ наиболее полезным для решения проблемы.
Кто оказался лучше по итоге, предлагаю обсудить читателям.
Показать полностью

Сам себя не похвалишь , кто же оценит ? Или , когда раздавали скромность DeepSeek где то шлялся
Вопрос : какая нейросеть дает более полный и корректный ответ по вопросам субд postgresql - yandexgpt или deepseek ?
Ответ DeepSeek:
При сравнении **YandexGPT** и **DeepSeek** в контексте ответов по **PostgreSQL** (СУБД), можно выделить несколько ключевых аспектов:
### **1. Глубина и точность ответов**
- **DeepSeek** (особенно **DeepSeek-V3**) демонстрирует **более глубокие и технически точные** ответы по PostgreSQL, включая:
- Оптимизацию запросов (EXPLAIN ANALYZE, индексы).
- Работу с партиционированием, репликацией.
- Особенности MVCC, блокировки (LOCKING).
- Расширения (PostGIS, pg_partman и др.).
- **YandexGPT** тоже хорошо справляется с базовыми вопросами, но иногда уступает в сложных темах (например, тонкости планировщика запросов).
### **2. Актуальность информации**
- DeepSeek имеет **актуальную базу знаний (по состоянию на 2024 год)**, включая новые фичи PostgreSQL 15-16.
- YandexGPT тоже обновляется, но иногда отстает в деталях.
### **3. Поддержка SQL-кода**
- Обе модели умеют **форматировать SQL-запросы**, но DeepSeek чаще дает **более эффективные варианты** (например, предлагает использовать `LATERAL JOIN` вместо подзапросов).
- YandexGPT иногда предлагает более простые, но неоптимальные решения.
### **4. Работа с ошибками и объяснениями**
- **DeepSeek** лучше объясняет **ошибки PostgreSQL** (например, "deadlock detected" или "out of memory").
- **YandexGPT** тоже помогает, но иногда ограничивается общими советами.
### **5. Контекст и примеры**
- DeepSeek чаще приводит **практические примеры** (например, как настроить репликацию или использовать оконные функции).
- YandexGPT иногда дает более краткие ответы без углубления.
### **Вывод**
**DeepSeek (особенно DeepSeek-V3) в среднем дает более полные и корректные ответы по PostgreSQL**, особенно в сложных сценариях. **YandexGPT** хорош для базовых вопросов, но если нужен экспертный разбор — лучше DeepSeek.
Если вам важна **максимальная точность**, можно проверить оба варианта на конкретном запросе, но **DeepSeek чаще выигрывает**.
Какую задачу по PostgreSQL вы решаете? Могу помочь сравнить ответы на конкретном примере. 🚀
И скромный ответ, на тот же вопрос , YandexGPT:
Нельзя однозначно сказать, какая из нейросетей, YandexGPT или DeepSeek, даёт более полный и корректный ответ по вопросам СУБД PostgreSQL.
По мнению некоторых пользователей, YandexGPT лучше справляется с техническими вопросами, в том числе связанными с СУБД PostgreSQL. Другие отмечают, что DeepSeek часто даёт лучшие ответы с точки зрения понимания контекста и объяснения логики.
Выбор нейросети зависит от конкретных потребностей пользователя. Чтобы получить наиболее точный ответ, рекомендуется корректно формулировать запрос, так как результат зависит от того, насколько подробно описана задача.
P.S. Наверное можно пожелать китайцам - быть скромнее и не выезживаться слишком , а нашим наоборот - "и побольше наглости, людям это нравится".
Показать полностью
Спрашивать у DeepSeek технические вопросы бесполезно . Спрашивать нужно у YandexGPT1
Продолжая игры с DeepSeek , в очередной раз убедился в безоговорочном лидерстве YandexGPT и практической бесполезности китайской нейросети, она просто не обучалась на материалах рунета . Скорее всего, с остальными чат ботами такая же ситуация.
Интересно - кого первого из ненаших ботов обучат на наших статьях ?
Вопрос: как снизить количество ожиданий ProcArray при высокой нагрузке на субд postgresql ?
Ответ DeepSeek
# Снижение количества ожиданий ProcArray в PostgreSQL при высокой нагрузке
Ожидания ProcArray (часто отображаемые как `ProcArrayLock` в статистике ожиданий) возникают, когда множество сеансов пытаются получить доступ к общему массиву процессов PostgreSQL одновременно. Вот основные методы для снижения таких ожиданий:
## 1. Оптимизация транзакций
- **Уменьшайте время выполнения транзакций** - разбивайте большие транзакции на меньшие
- **Избегайте долгих операций в транзакциях** - особенно операций ввода-вывода или сетевых вызовов
- **Используйте `SET LOCAL` вместо `SET`** для временных изменений параметров в транзакции
## 2. Настройки сервера
- **Увеличьте `max_connections`** (если ограничение близко к текущему использованию), но лучше:
- **Внедрите пул соединений** (pgBouncer, Odyssey) чтобы уменьшить количество реальных подключений к PostgreSQL
- **Настройте `idle_in_transaction_session_timeout`** для завершения "зависших" транзакций
- **Оптимизируйте `vacuum`** - длительные операции VACUUM могут блокировать ProcArray
## 3. Архитектурные изменения
- **Реализуйте разделение нагрузки** (читающие реплики, шардинг)
- **Кэшируйте часто запрашиваемые данные** на уровне приложения
- **Используйте асинхронные запросы** где это возможно
## 4. Мониторинг и анализ
- **Используйте `pg_stat_activity`** для выявления долгих транзакций
- **Анализируйте `pg_locks`** для обнаружения конфликтов блокировок
- **Настройте оповещения** о длительных ожиданиях ProcArrayLock
## 5. Версионные специфики
Для PostgreSQL 13+:
- Рассмотрите настройку `commit_delay` и `commit_siblings`
- Проверьте настройки `old_snapshot_threshold`
Помните, что ProcArray ожидания часто являются симптомом, а не причиной проблем. Лучший подход - комплексный анализ нагрузки и оптимизация транзакционной модели приложения.
Показать полностью
ЛЮБОЙ GITHUB — ЭТО ГАЙД
Вышел инструмент, который превращает любой репозиторий в гайд. Просто закидываешь ссылку — получаешь понятное объяснение, как всё работает.
Нейросети проходят по коду, разбираются в логике и выдают структурированный учебник. Всё с табличками, графиками и схемами.
Работает бесплатно. Уже можно попробовать.
📱 Исходный код — тут .
Источник: 🎯 НЕЙРО-ПУШКА ● НОВОСТИ И ОБЗОРЫ НЕЙРОСЕТЕЙ
Показать полностью