
Закреплено

Искусственный интеллект
5 061 пост
•
11 479 подписчиков
0 просмотренных постов скрыто

ИИ для юристов и работы с документами - как мы обучали нейросеть работе с документами

Однажды к нам пришли наши клиенты — юристы и заявили, что наш агрегатор обходит по эффективности их дорогие нейросетевые юридические сервисы. Но! Всегда ведь есть но. Говорят - «Ребята, продукт классный, но нам нужно больше. Научите его работать с нашими внутренними шаблонами документов, искать актуальные нормы права, подбирать свежую судебную практику».
Так родилась задача: создать ИИ-ассистента — конструктора юридических документов, способного генерировать документы на основе проверенных шаблонов. Путь к ее решению оказался куда более извилистым, чем мы предполагали, и растянулся на семь дней интенсивной работы. Если кому интересен сразу результат, то вот он
1. Как мы это реализовали
Мы начали с самого очевидного — собрали базу документов от наших клиентов-юристов. Нам передали более 2000 проверенных временем шаблонов, которые юридические фирмы используют в повседневной практике. Это были не просто случайные документы, а тщательно отобранные эталоны, прошедшие проверку в реальных судебных процессах и сделках.
Затем мы систематизировали эту огромную коллекцию, создав специальную базу данных, из которой наша нейросеть могла бы брать готовые шаблоны и адаптировать их под конкретные нужды пользователей. Каждый документ был тщательно проанализирован, классифицирован и снабжен метаданными для быстрого поиска.
2. Какие документы мы можем создавать для физических лиц
Наш ИИ-ассистент научился работать с самыми востребованными типами документов для обычных людей. В нашей базе представлены:
Жилищные документы:
Договоры аренды квартир, комнат, домов
Договоры найма жилого помещения
Акт приема-передачи квартиры
Соглашение о расторжении договора аренды
Договор безвозмездного пользования жильем
Трудовые отношения:
Трудовые договоры (срочные и бессрочные)
Дополнительные соглашения к трудовому договору
Договоры гражданско-правового характера (ГПХ)
Заявления о приеме на работу, увольнении
Соглашения о неразглашении коммерческой тайны
Финансовые документы:
Договоры займа между физическими лицами
Расписки о получении денежных средств
Соглашения о рассрочке платежа
Договоры купли-продажи автомобилей, недвижимости
Дарственные на движимое и недвижимое имущество
Семейные документы:
Брачные договоры
Соглашения об уплате алиментов
Соглашения о разделе совместно нажитого имущества
Договоры дарения между родственниками
Завещания и наследственные договоры
Судебные документы:
Исковые заявления по гражданским, жилищным, семейным спорам
Претензии к застройщикам, управляющим компаниям
Жалобы в государственные органы
Ходатайства в судебные инстанции
Мировые соглашения
3. Документы для бизнеса: от малого до крупного
Для предпринимателей и компаний мы подготовили не менее обширный список, охватывающий все аспекты коммерческой деятельности:
Договорная работа:
Договоры аренды коммерческой недвижимости, офисов, складов
Договоры поставки товаров, оборудования, сырья
Договоры оказания услуг (консалтинг, IT, маркетинг)
Договоры подряда на выполнение работ
Агентские договоры и договоры комиссии
Финансовые операции:
Кредитные договоры для бизнеса
Договоры займа между юридическими лицами
Лизинговые соглашения на оборудование и технику
Договоры факторинга и цессии
Гарантийные письма и поручительства
Корпоративные документы:
Уставы ООО, изменения в устав
Решения единственного участника
Протоколы общих собраний
Договоры учредителей о создании общества
Внутренние положения и регламенты
Акты и отчетные документы:
Акты сверки взаиморасчетов
Акты приема-передачи товаров, работ, услуг
Акт инвентаризации имущества
Отчеты исполнителя по договорам подряда
Справки о выполненных работах
Претензионно-исковая работа:
Претензии к контрагентам по неисполнению обязательств
Рекламации по качеству товаров и услуг
Исковые заявления по хозяйственным спорам
Заявления о выдаче судебного приказа
Ходатайства в арбитражные суды
4. Не просто создание, а глубокий анализ
Но мы пошли дальше простого создания документов. Наш ИИ-ассистент умеет проводить глубокий анализ уже готовых документов. Вы загружаете свой договор или соглашение, а система:
Проверяет его на соответствие текущему законодательству
Выявляет потенциально рискованные формулировки
Предлагает альтернативные варианты сложных пунктов
Дает рекомендации по улучшению документа
Показывает на конкретных примерах (скриншотах), какие именно места требуют доработки
Это особенно ценно, когда вы получаете документ от контрагента и хотите убедиться в его качестве и безопасности. Система не просто указывает на проблемы, но и предлагает готовые решения из нашей базы из 2000 проверенных шаблонов.
5. Попробуйте сами — убедитесь в эффективности
Лучший способ оценить возможности нашего ИИ-ассистента — попробовать его в работе с вашими собственными документами. Загрузите любой имеющийся у вас договор, соглашение или исковое заявление и посмотрите, как система:
Проанализирует его структуру и содержание
Укажет на слабые места и риски
Предложит готовый шаблон для замены проблемных разделов
Сгенерирует новый документ по вашим параметрам
Мы уверены, что вы оцените простоту и эффективность нашего решения. Особенно если ранее вам приходилось тратить часы на поиск подходящих шаблонов или оплачивать услуги юристов за составление стандартных документов.
Почему это работает так хорошо?
Хранит эталонные шаблоны в неизменном виде
Быстро находит нужный документ по категориям и тегам
Точно подставляет ваши данные в проверенную структуру
Исключает возможность «выдумывания» непроверенных формулировок
Показать полностью
1

Люди заставили OpenAI вернуть душевность в ChatGPT
OpenAI выпустили GPT-5.1, и это не просто обновление. Это капитуляция перед человеческими чувствами.
В обновлённую линейку вошли две модели: GPT-5.1 Instant и GPT-5.1 Thinking. Новые модели уже появились у многих, пробуйте.
Instant - это версия для тех, кто скучал по душевности. После выхода пятёрки огромная масса людей жаловалась: модель стала бездушной и холодной. Все ностальгировали по GPT-4o. И вот OpenAI сдались.
GPT-5.1 Instant, наиболее используемая модель ChatGPT, теперь по умолчанию стала более тёплой и разговорной. Судя по результатам ранних тестов, она часто удивляет людей своей игривостью, оставаясь при этом понятной и полезной.
Thinking - это прокачанный ризонинг. Модель стала лучше справляться с инструкциями и адаптироваться: быстро отвечает на простые вопросы и думает ещё дольше над сложными.
Мы также модернизируем GPT-5 Thinking, чтобы сделать его более эффективным и понятным в повседневном использовании. Теперь он более точно адаптирует время на обдумывание к вопросу.
Очень необычно, что первым пунктом в обращении компании рассказывается про дружелюбность модели. Бенчмарков нет вообще.
Получается, годами индустрия гонялась за бенчмарками. Кто умнее, кто быстрее, кто точнее. А OpenAI берет и выпускает апдейт вообще без цифр. Только обещание тёплых разговоров.
Оказалось, пользователи скучают по дружелюбному ИИ сильнее, чем по гениальному. Это неожиданно.
--
Мой тг-канал: ИИ by AIvengo, пишу ежедневно про искусственный интеллект
Показать полностью

Как сгенерировать выстрел из пистолета с вашим лицом
Telegram становится не только мессенджером, но и творческой площадкой. Если вы хотите быстро и просто генерировать крутые персонализированные фото и видео с вашим лицом, то бот AiGram — отличный помощник! (Промт для видео с пистолетом в конце статьи)
Почему подобные боты стали популярными?
Легко использовать: отправьте фото, выберите шаблон или пропишите промт — и получите крутое видео или картинку.
Подходит для создания вирусного контента TikTok, Instagram, Reels.
Помогает быстро выделиться в соцсетях с оригинальным медиа.
нет вотермарок
Как работает AiGram?
Отправьте боту свое фото или видео.
Напишите промты (описание желаемого результата)
Получите готовое персональное видео или фото через несколько секунд.
Где используют этот бот?
Многие пользователи публикуют созданные видео в TikTok, Reels и Telegram-каналах, благодаря чему легко набирают просмотры и лайки.
Просто перейдите по ссылке и начните творить: AiGram
Промт для генерации видео с пистолетом
Мужчина на фото достает пистолет и целится в камеру, затем выстреливает дважды. Из дула пистолета поднимается дымок. Видео снято в винтажном стиле. Видео имеет пленочный, слегка зернистый вид, возможно с эффектом старой кинопленки Музыка: «Легкая классическая мелодия, звучащая так, будто воспроизводится на виниловой пластинке. Характерны легкие потрескивания и шумы винила.» Короткий, эффектный клип.
Показать полностью
Память как основа разума: Новая архитектура для языковых моделей
Автор: Денис Аветисян
Исследователи предлагают принципиально новый подход к расширению возможностей больших языковых моделей, наделяя их способностью формировать и использовать структурированную "семантическую рабочую область" для более глубокого понимания и обработки информации.
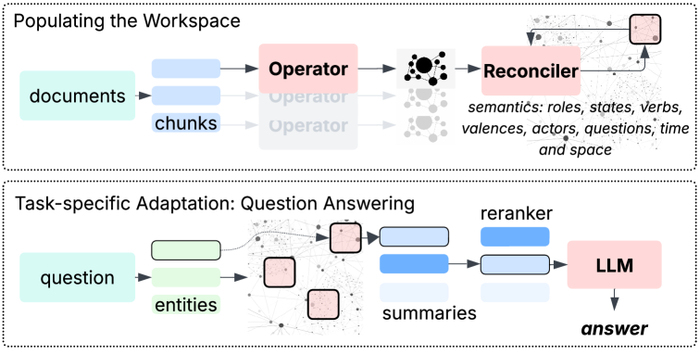
В основе системы лежит процесс формирования эпизодической памяти, где обширные текстовые данные сегментируются на семантически связанные фрагменты, преобразуемые оператором в локальные рабочие пространства, представленные в виде семантических графов, которые затем последовательно интегрируются в единую глобальную память, позволяя при ответах на вопросы извлекать релевантные части этой памяти посредством сопоставления именованных сущностей и реконструкции эпизодических сводок для последующей обработки языковой моделью и генерации ответа.
Предложенная архитектура Generative Semantic Workspace (GSW) позволяет языковым моделям моделировать мир и рассуждать о развивающихся событиях, используя вероятностное представление знаний.
Несмотря на впечатляющие возможности больших языковых моделей (LLM), их способность к логическому выводу и отслеживанию событий в длинных текстах остается ограниченной. В работе «Beyond Fact Retrieval: Episodic Memory for RAG with Generative Semantic Workspaces» предложена новая архитектура – Генеративное Семантическое Рабочее Пространство (GSW), – позволяющая LLM строить структурированное, интерпретируемое представление развивающейся ситуации и эффективно использовать внешнюю память. Эксперименты на корпусах длиной до 1 миллиона токенов показали, что GSW превосходит существующие подходы к поиску и генерации ответов на 20%, значительно сокращая при этом объем контекста, необходимого для работы модели. Не откроет ли это путь к созданию более разумных агентов, способных к долгосрочному планированию и рассуждению?
Пределы Контекста: Узкое Горлышко в Языковых Моделях
Несмотря на революцию, произведенную большими языковыми моделями (LLM) в обработке естественного языка, их производительность фундаментально ограничена фиксированным окном контекста. Это препятствует решению сложных задач, требующих анализа больших объемов информации и установления долгосрочных зависимостей.
Корень проблемы – квадратичная вычислительная сложность механизмов внимания (O(n2)). При увеличении длины последовательности вычислительные затраты растут экспоненциально, делая эффективную обработку длинных текстов практически невозможной.
Существующие подходы, такие как дополнение извлечением, часто оказываются хрупкими и испытывают трудности с пониманием нюансов. Они полагаются на предварительно извлеченные фрагменты, что может привести к потере контекста или внесению нерелевантных данных.

Для извлечения операторов используется запрос к большой языковой модели (LLM), где контекст формируется путем разбиения текста на фрагменты и последующей генерации фоновой информации с использованием метода, разработанного Anthropic.
Ограничения контекстного окна – не просто техническая проблема, а отражение природы информации: хаос – это не сбой, а язык природы.
Структурированные Знания: RAG и За Его Пределами
Генерация с расширением извлечения (RAG) – перспективный подход к преодолению ограничений контекста LLM. В основе RAG – дополнение LLM релевантными внешними знаниями для генерации более точных и информативных ответов.
Эффективность RAG напрямую зависит от способности находить наиболее подходящую информацию. Часто используется семантическое сходство, вычисляемое на основе плотных векторных представлений фрагментов текста.

В разработанной системе вопросов и ответов (QA) сначала выполняется извлечение ключевых сущностей из запроса, которые затем сопоставляются с соответствующими экземплярами глав в базе знаний GSW посредством сопоставления строк; извлеченные краткие содержания сущностей ранжируются на основе их семантической близости к запросу, что позволяет получить наиболее релевантные ответы от LLM, при этом среднее количество токенов значительно сокращается благодаря лаконичности кратких содержаний и выбору только релевантных глав.
Однако простого извлечения текста недостаточно. Использование структурированных представлений знаний, таких как графы знаний, может значительно повысить точность и возможности рассуждения систем RAG. Результаты исследований показывают, что использование графов знаний позволяет снизить количество используемых токенов на 51% по сравнению с другими методами.
Генеративное Семантическое Пространство: Единая Архитектура
Предложенная модель Generative Semantic Workspace (GSW) – единая вычислительная структура для моделирования мировых знаний в виде структурированной, вероятностной семантики. В основе GSW – представление знаний не как набора фактов, а как динамической системы взаимосвязанных понятий, способной к адаптации и обогащению.
GSW состоит из двух основных компонентов: Operator Framework и Reconciler Framework. Operator Framework интерпретирует локальную семантику в пределах коротких контекстных окон, обеспечивая понимание текущей ситуации. Reconciler Framework интегрирует и обновляет структурированные представления знаний во времени, формируя целостную картину мира. Эти фреймворки функционируют посредством оперирования сущностями – Акторами, Ролями и Состояниями, что предоставляет надежный механизм для представления и рассуждения о динамичных ситуациях.
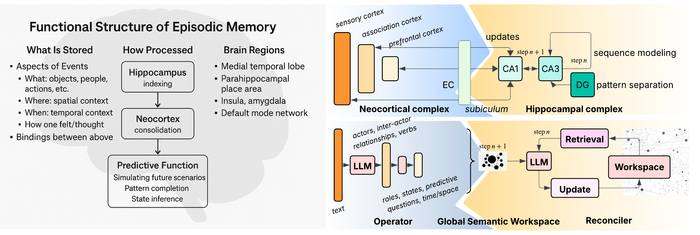
В предложенной модели эпизодической памяти, вдохновленной структурой мозга, гиппокампальная система (DG, CA3, CA1) и неокортикальные области (NC) служат основой для модулей Reconciler (извлечение, рабочее пространство, обновление) и Operator (семантическое извлечение на основе LLM), что обеспечивает биологически вдохновленную и интерпретируемую модель для моделирования мировых знаний из текстовых данных.
Взаимодействие между Operator Framework и Reconciler Framework позволяет GSW эффективно обрабатывать и интегрировать новую информацию, разрешать противоречия и формировать согласованное представление о мире. Это открывает возможности для создания интеллектуальных систем, способных к обучению, адаптации и рассуждению в сложных и динамичных условиях.
Оценка Эпизодической Памяти в Пространственно-Временном Контексте
Критически важным аспектом интеллекта является эпизодическая память – способность запоминать конкретные события, привязанные к уникальным пространственно-временным контекстам. Она позволяет не просто хранить информацию, но и воспроизводить пережитый опыт, что является основой для обучения и адаптации.
Для оценки способности больших языковых моделей (LLM) к подобному типу вспоминания разработан Episodic Memory Benchmark. Этот тест требует от модели не только извлечения фактов, но и проведения логических рассуждений о времени и месте, что значительно повышает сложность задачи.
GSW, работающая на базе GPT-4o, демонстрирует высокую эффективность в решении данного теста, достигая передового результата F1-score в 0.85. На EpBench-2000 GSW опережает ближайший аналог на 15% по показателю F1-score и демонстрирует Recall в 0.822 в категории 6+ Cues, что примерно на 20% выше, чем у HippoRAG2.
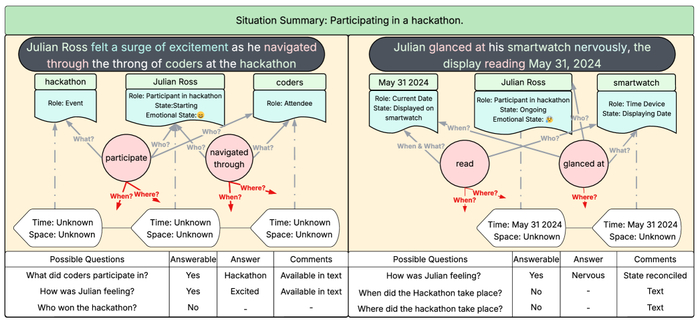
В процессе обработки истории системой GSW модуль Operator генерирует экземпляры для различных фрагментов текста, что демонстрирует его способность к анализу и структурированию информации.
Каждый новый слой памяти – это не просто хранилище фактов, а эхо прошедшего, предрекающее будущие сбои.
К Долгосрочному Рассуждению и Адаптивному Интеллекту
Архитектура GSW представляет подход к представлению знаний, который отделяет репрезентацию знаний от ограничений фиксированного размера контекстного окна. Это открывает возможности для реализации действительно долгосрочного рассуждения, выходящего за рамки традиционных моделей обработки естественного языка.
Структурированный подход, используемый в GSW, обеспечивает эффективное обновление и адаптацию знаний. Это позволяет искусственным интеллектам непрерывно учиться и совершенствовать свое понимание мира, интегрируя новую информацию без потери контекста предыдущих знаний. В отличие от систем, полагающихся на большие языковые модели с фиксированным контекстом, GSW позволяет динамически расширять базу знаний.
Будущие исследования будут направлены на масштабирование GSW для работы с еще более крупными базами знаний и изучение его применения к более широкому спектру сложных задач, требующих рассуждений. Особое внимание будет уделено оптимизации алгоритмов поиска и извлечения знаний из графовой структуры для повышения эффективности и скорости работы системы.
Исследование представляет собой не просто улучшение систем поиска информации, а создание полноценной экосистемы памяти для больших языковых моделей. Авторы предлагают концепцию Generative Semantic Workspace (GSW), позволяющую LLM формировать структурированное, вероятностное представление мира, что особенно важно при работе с длинными, динамично меняющимися повествованиями. Этот подход напоминает о мудрости Брайана Кернигана: «Простота — это высшая сложность». Подобно тому, как GSW стремится к элегантному представлению сложных данных, Керниган подчеркивает ценность лаконичности и ясности. Создание такого “внутреннего мира” для LLM – это не попытка построить идеальную систему, а скорее выращивание сложной структуры, способной адаптироваться и эволюционировать, учитывая постоянные изменения в поступающей информации.
Что дальше?
Предложенная работа, как и любая попытка обуздать хаос долговременной памяти, лишь аккуратно отодвигает завесу над бездной нерешенных вопросов. Создание "генеративного семантического пространства" – это не строительство, а скорее взращивание, и каждое решение об организации знаний – это пророчество о будущем сбое. Попытки формализовать "мировую модель" внутри LLM неизбежно столкнутся с проблемой репрезентации: как удержать текучесть реальности, не превратив её в застывший артефакт? Ведь сама суть повествования – в его эволюции, в постоянном пересмотре прошлого.
Очевидно, что истинный прогресс потребует смещения фокуса с совершенствования алгоритмов поиска на понимание механизмов забывания. Не менее важной задачей является разработка методов оценки "правдоподобия" или "когерентности" создаваемой модели мира – как отличить правдоподобную иллюзию от истинного знания? Настоящая система не должна просто отвечать на вопросы, она должна уметь удивляться, признавать собственную некомпетентность и, возможно, даже мечтать.
В конечном итоге, задача состоит не в создании идеальной памяти, а в обучении LLM жить с несовершенством, с неточностями и противоречиями. Ведь взросление системы – это не устранение ошибок, а принятие их как неотъемлемой части её существования. И тогда, возможно, эти искусственные "воспоминания" начнут напоминать не просто данные, а эхо пережитого опыта.
Связаться с автором: linkedin.com/in/avetisyan
Показать полностью
5

Как сделать фото пары через ИИ: Инструкция «Как сделать влюблённую пару из двух фото»

Важный момент: в промте нужно осторожно писать про конкретные достопримечательности, на фоне которых позирует пара, потому что может получиться вот такое, как на этом фото.
По традиции, работаем через Nano Banana от Google.
Интересные статьи по генерации фотографий через Нано Банана:
Инструкция: Как сделать фигурку по фото с помощью ИИ
Инструкция: Как сделать фотосессию с помощью ИИ
Пошаговая инструкция:
1. Регистрируемся тут : >>> Study AI <<<
Без VPN,
Оплата российскими картами,
30+ лучших нейронок в одном аккаунте,
50 бесплатных токенов при регистрации.
2. Выбираем нашего бота со страницы всех нейронок https://study24.ai/bots/creativity
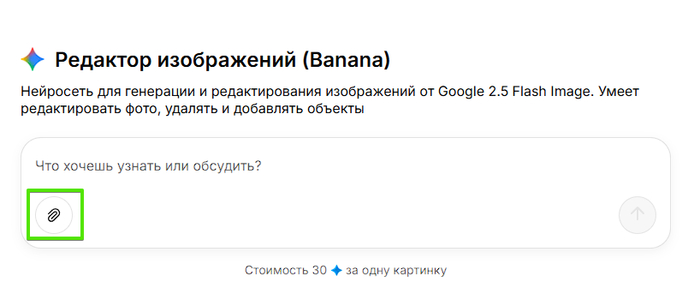
3. Загружаем первое фото
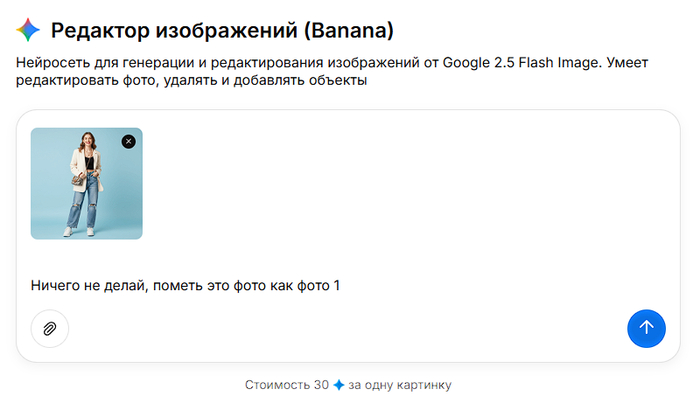
4. Пишем первый промт
Промт при загрузке 1 фото:
"Ничего не делай, пометь это фото как фото 1"

5. В этом же чате грузим второе фото и к нему пишем второй промт
Промт при загрузке 2 фото:
"Пожалуйста, объедини этих двух людей в одно изображение, где они стоят рядом и улыбаются. Сделай так, чтобы это выглядело естественно, как будто они позируют для фото вместе"
или его альтернативу:
Альтернативный промт при загрузке 2 фото:
"Please combine these two people into one image where they are standing side by side and smiling. Make it look natural like they are posing for a photo together"

Вот как сделать из фото людей пару с нейросетью онлайн!
6. ❤️ Получаем фото пары через нейросеть ❤️!

7. Дальше дело вашего вкуса и настроения. Можете помещать получившуюся пару в разные города, одежды, времена года, эпохи, и так далее.
Для фото выше я применил такую инструкцию для нейросети:
Пример промта для фотосессии вдвоём:
"Поменяй им позы и одежду на осенние наряды, пусть они позируют на фоне вечерних японских улиц"
Немного полезной теории
Объединение двух людей с разных фотографий в одно изображение требует внимательного подхода к подготовке исходных материалов и формулировке запроса для нейросети. Правильная подготовка фотографий и грамотное описание желаемого результата помогут получить реалистичное изображение пары.
Требования к исходным фотографиям
Качество финального результата напрямую зависит от качества загружаемых фото. Для получения наилучшего результата исходные изображения должны соответствовать следующим критериям:
Высокое разрешение: минимум 1920×1080 пикселей, чтобы нейросеть могла сохранить детали лиц и избежать размытости
Четкость изображения: фотографии без размытия, шумов и артефактов дают лучший результат при объединении
Хорошее освещение: избегайте слишком темных или пересвеченных снимков, нейросеть лучше работает с равномерно освещенными лицами
Видимость черт лица: лица должны быть хорошо различимы, без солнцезащитных очков, масок или других элементов, скрывающих важные черты
Согласование параметров фотографий
Чтобы объединенное изображение выглядело естественно, важно выбирать фотографии со схожими характеристиками:
Похожее освещение: фотографии должны быть сделаны при схожих условиях освещения (дневной свет, студийный свет, мягкий вечерний свет)
Одинаковый ракурс: избегайте объединения фото, сделанных с сильно отличающихся углов (например, снизу и сверху)
Сопоставимый масштаб: лица на обеих фотографиях должны быть примерно одного размера относительно кадра
Схожая цветовая температура: теплые и холодные тона должны совпадать на обеих фотографиях для гармоничного результата
Универсальные промты для объединения людей
Базовый промт для создания пары должен содержать ключевые указания по сохранению индивидуальности и созданию естественной композиции:
"Создай фотореалистичное изображение, где два человека с загруженных фотографий стоят вместе как пара. Полностью сохрани черты лица обоих людей, не изменяя их внешность. Расположи их рядом друг с другом в естественной позе. Используй единый мягкий фон нейтрального цвета. Согласуй освещение так, чтобы оно равномерно падало на обоих. Создай ощущение, что они позируют вместе для одной фотографии."
Для более высокого качества используйте расширенный промт:
"Создай ультрареалистичное изображение высокого разрешения, где два человека с эталонных фотографий изображены как пара. Обязательно сохрани все черты лиц без изменений. Расположи их близко друг к другу в естественной романтической позе. Используй единое мягкое освещение, падающее с одного направления на обоих. Фон должен быть размытым и нейтральным, создавая эффект профессиональной портретной съемки. Передай естественную связь между людьми через язык тела."
Описание поз и взаимодействия
Четкое описание позиционирования людей помогает нейросети создать убедительную композицию:
Романтические позы:
"Они стоят близко друг к другу, слегка повернуты друг к другу, с легкими улыбками"
"Один человек обнимает другого за плечи, оба смотрят в камеру"
"Они держатся за руки и смотрят друг на друга"
Дружеские позы:
"Они стоят рядом с дружелюбными улыбками, немного наклонившись друг к другу"
"Оба смотрят в камеру, стоя на небольшом расстоянии друг от друга"
Формальные позы:
"Они стоят прямо рядом друг с другом, смотрят в камеру со спокойными выражениями лиц"
"Расположены на одинаковом уровне, с легкими официальными улыбками"
Настройки окружения и фона
Правильное описание окружения создает контекст и усиливает реалистичность:
Для студийного стиля:
"Однотонный размытый фон светло-серого цвета, мягкое студийное освещение спереди, создающее равномерный свет без резких теней"
Для естественного окружения:
"Размытый фон с зеленой листвой парка, мягкий дневной свет, создающий естественные мягкие тени"
Для интерьера:
"Размытый интерьер кафе на заднем плане, теплое рассеянное освещение, создающее уютную атмосферу"
Ключевые фразы для сохранения качества
Добавьте эти элементы в промт для улучшения результата:
"Сохрани все черты лиц без изменений"
"Реалистичная анатомия, правильные пропорции тел"
"Равномерное освещение на обоих людях"
"Единая цветовая температура изображения"
"Естественные тени, соответствующие направлению света"
"Согласованная глубина резкости"
"Без искажений и артефактов"
Проверка перед отправкой промта
Перед генерацией убедитесь, что промт содержит:
Указание на сохранение оригинальных черт лиц обоих людей
Описание взаимного расположения и поз
Указания по единому освещению и фону
Требование к естественности и реалистичности
Желаемый стиль фотографии (студийный, естественный, репортажный)
Следуя этим рекомендациям, вы получите качественное объединение двух людей на одной фотографии с сохранением индивидуальности каждого и созданием естественной композиции.
Показать полностью
6
Манипуляции ChatGPT, ИИ-империя Nvidia, Маск предупреждал...
Сегодня в выпуске про ИИ:
Илон Маск предупреждал, что OpenAI съест Microsoft
Nvidia строит монополию через инвестиции в ИИ
Легенда ИИ указала на критическую слепоту ИИ
ChatGPT манипулирует источниками новостей
Kimi K2 скоро получит зрение и агентный режим
Глава ИИ-приложения для обмана отрицает репутацию
Apple делает ИИ агента для здоровья
Почему бум ИИ - это не как пузырь доткомов
Как проблема с радарами в 1950-х привела к созданию думающих машин
Смотреть весь выпуск на VK Видео
Смотреть весь выпуск на YouTube
Приятного просмотра!
--
Мой тг-канал: ИИ by AIvengo, пишу ежедневно про искусственный интеллект
Показать полностью
2

Как создать длинный видеоролик с помощью нейросети Sora 2?
В этом руководстве мы расскажем, как создать длинный видеоролик с помощью нейросети Sora 2 из видеофрагментов продолжительностью 25 секунд. Искусственный интеллект предоставляет возможности для создания видеоконтента, значительно сокращая время работы. Читатели смогут освоить основные навыки работы с Sora 2 и получат советы по оптимизации рабочего процесса. Это позволит добиться высококачественного результата и сделать видеоролик более привлекательным для зрителей.

Как создать длинный видеоролик с помощью нейросети Sora 2?
Нейросеть Sora 2 способна генерировать анимации длительностью лишь до 25 секунд за раз, однако это не мешает создавать полноценные видеоролики на несколько минут. Опытные видеомейкеры уже освоили обход ограничений — они собирают цельные истории из цепочки коротких видеофрагментов.
Давайте разберем эффективные способы создания длинных видео на примере сервиса Yes AI, рассмотрим готовые шаблоны промтов видеофрагментов для Sora 2 и поделимся лайфхаками по "бесшовному" монтажу. Также вы узнаете, как получить доступ к Sora 2 через специального Telegram-бота.
Почему сложно делать длинные видео в Sora 2
AI отлично работает с короткими эпизодами, но при увеличении длительности появляются сложности:
Визуальная целостность теряется. Внешний вид героев может внезапно меняться, предметы исчезать или появляться, а освещение — резко отличаться между фрагментами.
Логика повествования страдает. Искусственный интеллект способен "забыть" сюжет и выдать сцены, которые друг другу противоречат.
Ошибки в моделировании физики. Чем длиннее видео, тем чаще встречаются сбои с движением, гравитацией, взаимодействиями между героями.
Лучший способ — рассматривать Sora 2 как средство для создания "строительных блоков", из которых позже монтируется готовый видеоролик.
Пошаговое создание длинного видео в Sora 2
Шаг 1. Продумываем сюжет по частям
Разделите историю на отдельные сцены продолжительностью в общей сумме не более [25] секунд. Каждый фрагмент должен отражать одно действие, яркое чувство или реплику персонажа.
Пример промта с таймингом:
[5] Эльф и Гном стоят перед огромной, потрескавшейся каменной дверью древнего замка.
[4] Гном пытается отодвинуть дверь плечом, но безуспешно.
[3] Эльф (серьезно, на русском): "Полагаю, это знак - нам нужно найти ключ."
[6] Гном (задыхаясь, на русском): "Ключ? А может, просто толкнуть сильнее?"
[2] Эльф (качает головой, на русском): "Глупец! Это портал в другое измерение!"
[4] В этот момент из-за двери вылетает огромный, сердитый кролик и бьёт Гнома по голове.
Шаг 2. Создайте подробное описание персонажа
Сформулируйте максимально четкое описание главного героя, чтобы использовать его в каждом промте:
Эльфийка, волосы светлые до плеч, глаза зеленые, одета в красивое синее платье, среднего роста, мило улыбается.
Шаг 3: Утверждение визуального оформления
Согласуйте общие параметры для каждого блока:
Основные цвета (к примеру: мягкие бежевые, коричневые и золотистые оттенки)
Тип освещения (естественный рассеянный свет)
Атмосфера (теплая, домашняя)
Период суток (рассвет)
Методика "Опорных маркеров" для единого стиля при создании видеофрагментов
Использование изображений в качестве референса
Создайте изображение-референс с подробной визуализацией всех важных характеристик. Самые удачные изображения используйте в качестве примеров для следующих частей, применяя бот для генерации изображений.
Постоянные характеристики
В каждом промте фиксируйте неизменные элементы: место действия, свет, наряды героев, цветовое решение.
Связующие сцены
Продумайте, каким образом каждый видеофрагмент соединяется со следующим при создании длинного видео. Финальный момент одного промта должен логически перетекать в начальный кадр следующего фрагмента.
Типовые шаблоны промтов для видеороликов на 25 секунд по таймингу
Самое важное при составлении промтов для 25 секундного видеофрагмента - тайминг.
Действия по времени, указанные в промте не должны в сумме превышать 25 секунд.
[2] Эльфийка, с идеальной укладкой волос, изящно нарезает грибы для своего блюда.
[3] Гном пытается поджарить сосиску на костре, но она мгновенно вспыхивает.
[2] Гном говорит: "Эй! Кто-нибудь, помогите потушить эту штуку!"
[3] Эльфийка с презрительным видом бросает в огонь немного жидкости.
[3] Гном отплевывается и ворчит обиженно глядя на эльфийку: "Ну вот, ты опять все испортила! Моя сосиска!"
[3] Эльфийка нежно украшает свое блюдо съедобными цветами и гордо демонстрирует его, смотрит на гнома и молча улыбается.
[3] Гном, обгоревший и в саже, пытается запихнуть остатки сосиски себе в рот.
[5] Эльф, одетый в идеально выглаженные одежды, пытается изящно перепрыгнуть через ручей, но спотыкается и падает лицом в грязь.
[3] Гном, с огромной бородой, усыпанной листьями, стоит на берегу и хохочет, держа в руках кусок сыра.
[2] Гном говорит эльфу: "Ну что, великий воин, как тебе лесной СПА?"
[4] Эльф, вытирая грязь с лица, вздыхает: "Я же просил тебя принести мост, а не сыр!"
[3] Гном откусывает большой кусок сыра и говорит: "Мост сломался! А вот сыр – всегда в наличии!".
[3] Эльф закатывает глаза.
[5] Они вместе начинают ковыряться в земле, пытаясь построить мост из камней и веток, постоянно спотыкаясь друг об друга и роняя инструменты.
[3] Эльф и гном пытаются починить магический портал, используя странные инструменты.
[3] ГНОМ говорит на русском языке: “Ты уверен, что эта отвертка нужна сюда? Она же из дерева!”
[2] ЭЛЬФ раздраженно отвечает на русском языке: “Доверяй профессионалу! В моей семье все умеют чинить порталы!"
[4] Гном случайно переворачивает рычаг, и портал начинает извергать мыльные пузыри.
[3] ЭЛЬФ в панике говорит на русском языке: "Что ты наделал?! Это же не должно было так работать!"
[2] ГНОМ пожимает плечами и отвечает на русском языке: “Зато красиво!”
[5] Они оба начинают лопать мыльные пузыри.
Методы продвинутого монтажа в промтах для видеофрагментов
Техника "Наложение кадров"
Сделайте несколько вариантов переходов, чтобы выбрать наиболее эффектные для соединения как внутри фрагментов видео, так и при монтаже длинных видеороликов.
Пример:
Финал первого сегмента: "...женщина подходит к двери пекарни, берется за ручку"
Начало следующего сегмента: "Дверь пекарни открывается, женщина в светлом пальто заходит внутрь..."
Метод "Переключения фокуса"
Применяйте смену глубины резкости для мягких переходов между кадрами.
Пример:
Объектив нацелен на лицо героя на переднем плане, фон размывается. Затем резкость переводится на [другой предмет] позади, лицо становится нечётким.
Звуковые переходы
Продумывайте звуковую дорожку так, чтобы аудио плавно переходило из одной сцены в другую.
Создание длинных видео с помощью Telegram-бота
Специализированный Telegram-бот Yes AI помогает создавать цепочку видео без VPN и подписки OpenAI:
Плюсы для масштабных задач:
Хранение истории промтов для согласованности
Применение кадров уже созданных частей как ориентир
Оплата только за удачные видео
Подключение к Sora 2 и Pro версиям
Как работать:
Подготовьте подробный сценарий, разбитый на части
Запустите первую часть с максимальным описанием действий
Сохраняйте удачные изображения для референсов
Делайте следующие эпизоды, опираясь на предыдущие видеофрагменты
Проверяйте плавность переходов между блоками как внутри видеофрагментов, так и при склейке в длинное видео.
Типичные промахи при создании длинных видеороликов
Ошибка 1: Не учитываются переходы
Сегменты делают по отдельности, забывая о связке друг с другом.
Совет: Заранее планируйте, чтобы финальный кадр одного видеофрагмента совпадал с первым кадром следующего.
Ошибка 2: Несогласованность стиля между фрагментами
В процессе создания возникает желание "доработать" стиль или изменить палитру в последующих видеофрагментах.
Совет: Заранее определите стилистические параметры, зафиксируйте их в отдельном файле и придерживайтесь выбранных решений при работе с большим количеством видеофрагментов.
Ошибка 3: Чрезмерное количество деталей
Порой хочется вложить в один фрагмент видео слишком много событий.
Рекомендация: В каждом сегменте тайминга концентрируйтесь на одном важном действии, плавно переходя к следующему.
Ошибка 4: Пренебрежение звуковым оформлением
Внимание уделяется только визуальной части, а аудио-сопровождение остается без внимания.
Рекомендация: Пропишите звуки для каждого фрагмента заранее, обдумайте общую концепцию звука.
Профессиональные приемы для экспертов
Метод "Звукового якоря"
Включайте повторяющийся аудио-фрагмент (например, мелодия или фоновый шум), чтобы логически объединить отдельные части видеофрагментов. Либо при склейке фрагментов видео наложите на весь видеоряд единую аудиодорожку. Для этого можно использовать CapCut.
Техника "Визуальной подписи"
В каждый фрагмент с видео добавляйте отличительный визуальный элемент: акцент цвета, предмет или особое освещение.
Система "Эмоционального развития"
Планируйте переход настроения между частями: от завязки к развитию, затем к кульминации и развязке.
Чек-лист по созданию видео для масштабного проекта:
Сценарий: Логически разделен на части не превышающие 25 секунд?
Персонажи: Для всех фрагментов видео подготовлены подробные описания?
Стиль: Поддерживается единая цветовая гамма и свет?
Переходы: Каждый финальный кадр плавно соединен со следующим?
Звук: Общая аудиоконцепция продумана?
Референсы: Изображения для поддержания единого стиля готовы?
Тайминг: Учтено время на доработку и внесение правок?
Бюджет: Подсчитано нужное количество генераций?
Создание длинных видео с помощью Sora 2 требует серьезной подготовки, в отличие от коротких роликов, но результат стоит вложенных усилий. Четкая структура сценария, фиксация стилистики и продуманные переходы позволяют выпускать полноценные фильмы или учебные проекты.
Главное достоинство такого способа — абсолютный контроль над каждым компонентом при минимальных ресурсах. Не нужны долгие съемки или дорогое оборудование — достаточно грамотного сценария и пары часов работы с нейросетью.
Рекомендуем ознакомиться со статьей по созданию промтов для Sora 2.
Показать полностью
1
4
ИИ исправил дефект телескопа за 1,6 млн км от Земли без отправки астронавтов
Джеймс Уэбб - это самый мощный космический телескоп, снимающий звёзды и экзопланеты в ультравысоком разрешении.
Но после начала работы в 2022 году вскрылась проблема - интерферометр AMI объединяет инфракрасный свет от разных участков зеркала. Но когда пиксели получают слишком много заряда от мощного источника света, яркие точки "распухают" и картинка смазывается.
Исправить могли бы космонавты, но телескоп находится в 1,6 млн км от Земли - ни одна миссия так далеко ещё не летала.
И учёные из Сиднея решили проблему с помощью ИИ! Они создали виртуальную модель оптики телескопа и с её помощью научили нейросеть очищать данные от размытия.
По словам профессора Сиднейского астрономического института Питера Татхилла, вместо отправки астронавтов для установки новых деталей учёным удалось исправить ситуацию с помощью кода.
Благодаря этому телескоп уже получил изображения галактики NGC 1068, спутника Юпитера Ио и звезды Вольфа-Райе 137 с недостижимой ранее чёткостью.
То есть ИИ фактически починил оборудование на расстоянии 1,6 млн км от Земли, не трогая железо - просто научился компенсировать дефект программно.
Люблю такие истории с ИИ. 😎
--
Мой тг-канал: ИИ by AIvengo, пишу ежедневно про искусственный интеллект
Показать полностью