Длинные видео: как 13 миллиардов параметров учатся видеть мир
Автор: Денис Аветисян
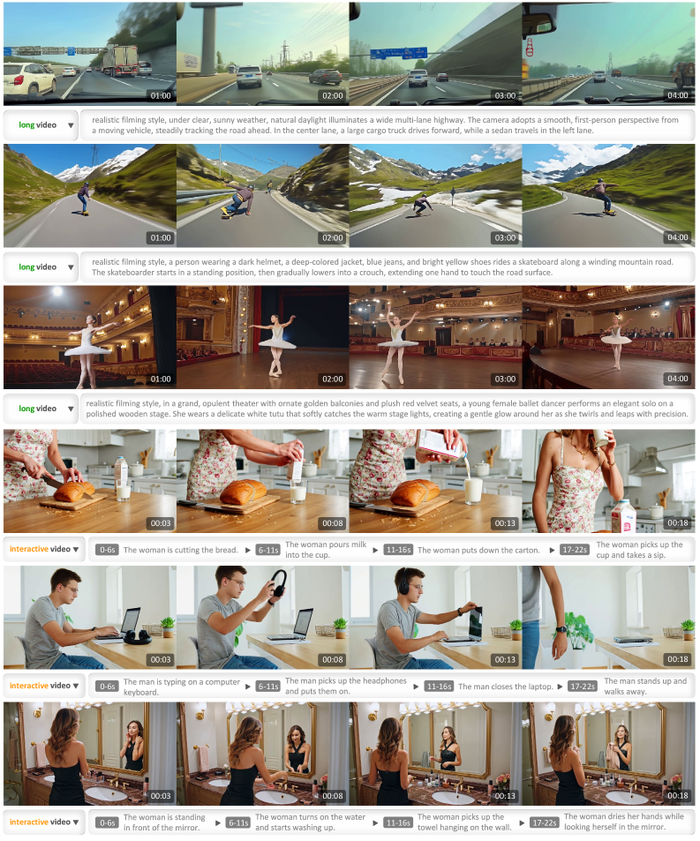
LongCat-Video демонстрирует способность создавать видео продолжительностью в минуты без потери качества, а также реагировать на изменяющиеся инструкции для каждого кадра, подтверждая, что даже хаос можно уговорить, если найти правильное заклинание генерации.
Долгое время создание действительно продолжительных и связных видео оставалось недостижимой мечтой, поскольку существующие модели испытывали трудности с поддержанием временной согласованности и избежанием накопления ошибок с течением времени. Прорыв, представленный в ‘LongCat-Video Technical Report’, заключается в новом подходе к моделированию долговременных зависимостей, позволяющем генерировать минуты качественного видео без деградации. Но сможет ли эта технология не просто создавать визуальные истории, а действительно воплощать сложные миры и интерактивные симуляции, приближая нас к созданию полноценных, самообучающихся цифровых двойников реальности?
Танец Иллюзий: О покорении хаоса в движущихся образах
Иллюзии движения – вот что мы видим в сгенерированных видео. Но под этой гладкой поверхностью скрывается хаос. Современные модели генерации видео, словно алхимики, пытаются удержать этот хаос в рамках нескольких секунд. Они создают яркие, но мимолетные видения. Однако, настоящая магия заключается в способности рассказать историю, развернуть целое полотно событий. И здесь начинается истинное испытание.
Существующие модели, как правило, спотыкаются о банальное: поддержание временной согласованности. Они творят короткие зарисовки, но долгое повествование для них – непосильная ноша. Некоторые пытаются решить проблему грубой силой, увеличивая вычислительные затраты. Но это лишь усугубляет ситуацию, делая процесс генерации недоступным для большинства. Это всё равно что пытаться остановить течение реки плотиной – временно, но разрушительно.
Ключ к решению лежит не в увеличении мощности, а в понимании природы времени. Главная преграда – умение моделировать долгосрочные зависимости внутри видеопоследовательности. Необходимо найти архитектурные решения, которые позволят удержать нить повествования, даже когда события разворачиваются на протяжении нескольких минут. Это как плетение гобелена – каждая нить должна быть прочно связана с остальными, чтобы создать целостную картину.

Исследователи демонстрируют, что рабочий процесс создания видео-подписей включает в себя захват основного содержания видео базовой моделью и дополнение его моделями, извлекающими атрибуты, такие как кинематография и визуальный стиль, что позволяет создавать разнообразные и информативные подписи и повышать качество и разнообразие обучающих данных.
Мы видим лишь тени, отбрасываемые реальностью. Модели – лишь инструменты для измерения этой темноты. Истинная цель – не достижение высокой точности, а создание иллюзии жизни. Не просто сгенерировать видео, а вдохнуть в него душу. И это – задача, которая требует не только технических решений, но и глубокого понимания самой природы повествования.
LongCat-Video: Фундамент для Бесконечного Полотна
Исследователи представляют LongCat-Video – модель, содержащую тринадцать миллиардов параметров, и, смеем заметить, не только цифры. Это своего рода универсальный ключ, открывающий двери в мир генерации видео. Она объединяет в себе задачи преобразования текста в видео, изображения в видео и, что особенно важно, продолжение уже существующего видеоряда. Нельзя сказать, чтобы это было просто, ведь данные – существа капризные, но, как говорится, укрощение диких пикселей – наше призвание.
В основе LongCat-Video лежит вариационный автоэнкодер (VAE). Это, если хотите, некий художник, сжимающий информацию до лаконичного эскиза, а затем воссоздающий его в детальной картине. Такой подход позволяет добиться высокого качества генерации видео, не перегружая при этом вычислительные ресурсы. Ведь, согласитесь, не всегда нужно жертвовать производительностью ради красоты, особенно когда речь идет о серверах.
Особого внимания заслуживает реализация технологии Coarse-to-Fine Generation. Сначала модель создает видео низкого разрешения – своего рода черновик, а затем, шаг за шагом, доводит его до совершенства. Это как полировка бриллианта: грубая обработка, а затем – филигранная работа. Такой подход позволяет значительно ускорить процесс генерации, не жертвуя при этом качеством изображения. А ведь время – это деньги, как любят говорить финансисты.

Результаты, представленные на примере преобразования изображения в видео, показывают, что LongCat-Video точно реагирует на инструкции для различных действий, начиная с одного и того же исходного изображения.
В конечном счете, LongCat-Video – это не просто модель, это платформа, фундамент для построения более сложных систем. И, знаете, иногда я думаю, что будущее видеогенерации – это не о создании идеальных картинок, а о создании правдоподобных миров. И, возможно, LongCat-Video – это первый шаг на этом пути. Хотя, конечно, всегда есть риск, что данные взбунтуются. Но мы к этому готовы. Всегда.
Алхимия Оптимизации: LoRA, Sparse Attention и Гармония с Человеком
Исследователи столкнулись с извечной дилеммой: как обуздать хаос данных, не потеряв при этом драгоценную искру творчества? Любая модель – это лишь попытка зафиксировать неуловимое, а обучение – ритуал, полный компромиссов. Их подход к оптимизации – не просто увеличение точности, а скорее, умение украшать хаос, направляя его энергию в нужное русло.
Для ускорения процесса обучения, они обратились к проверенной алхимической практике – использованию LoRA (Low-Rank Adaptation). Это позволило им значительно сократить количество обучаемых параметров, не жертвуя при этом качеством генерируемых видео. Это как найти волшебный катализатор, который усиливает реакцию, не требуя огромных затрат энергии.
Но даже LoRA не всегда достаточна. Чтобы укротить вычислительного зверя, исследователи применили Block Sparse Attention. Этот метод позволяет модели сосредоточиться на наиболее важных частях видеопоследовательности, отбрасывая ненужные детали. Это как умелый художник, который выделяет главное, создавая гармоничное целое.
Однако, даже самая совершенная модель нуждается в тонкой настройке. Чтобы согласовать выходы модели с человеческими предпочтениями, они использовали Group Relative Policy Optimization (GRPO). Этот метод позволяет модели учиться на обратной связи от людей, постепенно приближаясь к идеалу. Используя тщательно разработанные сигналы вознаграждения GRPO, они смогли добиться впечатляющих результатов, как видно из графиков, демонстрирующих стабильность и эффективность предложенного подхода.
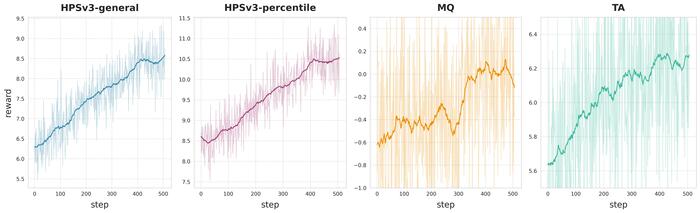
Кривые вознаграждения GRPO, полученные в ходе многонаправленного обучения LongCat-Video, демонстрируют эффективность предложенного подхода.
Их подход – это не просто набор технических приёмов, а философия. Они не стремятся к идеальной точности, а к гармоничному сочетанию алгоритмов и человеческого творчества. Ведь в конечном итоге, любая модель – это лишь инструмент, а настоящее волшебство происходит, когда этот инструмент попадает в руки умелого мастера.
За Гранью Генерации: К Мировым Моделям и Будущим Горизонтам
LongCat-Video – это не просто генератор видео, это попытка заглянуть в саму суть движущихся образов. Авторы не стремились создать очередную фабрику красивых картинок, а попытались построить мост между миром данных и миром восприятия. Иначе говоря, это не просто алгоритм, а зачаток цифрового голема, способного не только воспроизводить, но и понимать окружающую среду.
Традиционные генераторы видео, как правило, ограничены короткими фрагментами. Они могут создать впечатляющую заставку, но не способны рассказать историю. LongCat-Video же, напротив, выходит за эти рамки. Благодаря эффективному моделированию временных зависимостей, эта система способна создавать связные и реалистичные повествования, которые разворачиваются на протяжении минут. Это не просто последовательность кадров, а живая ткань, сотканная из движения и света.
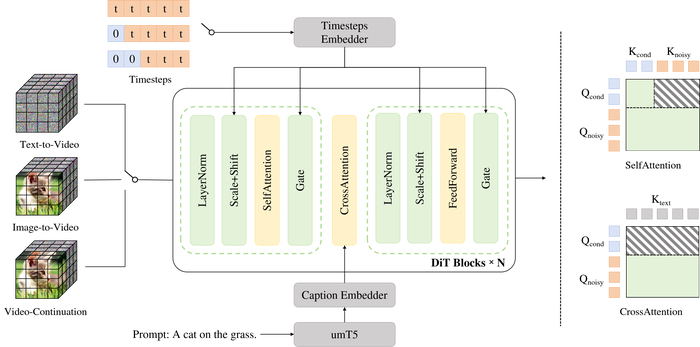
Предлагаемая унифицированная трансформерная модель поддерживает одновременное выполнение задач преобразования текста в видео, изображения в видео (с одним кадровым условием) и продолжения видео (с несколькими кадровыми условиями), при этом обновления условных токенов в механизме самовнимания независимы от зашумленных токенов, а условные токены не участвуют в вычислениях перекрестного внимания.
Но истинная ценность LongCat-Video заключается не в развлекательном потенциале, а в возможностях, которые она открывает за пределами индустрии развлечений. Представьте себе симуляторы, настолько реалистичные, что стирают грань между виртуальным и реальным. Роботов, способных ориентироваться в сложных условиях, не просто выполняя заданную программу, а адаптируясь к меняющейся обстановке. Виртуальную реальность, настолько захватывающую, что позволяет пережить события, которые никогда не происходили. Это не фантастика, а вполне вероятное будущее, которое становится всё ближе благодаря разработкам, подобным LongCat-Video.
Авторы не стремятся создать идеальную систему – такова природа любого заклинания. Они предлагают инструмент, который можно использовать для изучения мира, для создания новых миров, для расширения границ человеческого восприятия. И как любое мощное заклинание, LongCat-Video требует осторожного обращения и глубокого понимания его принципов работы. Но в руках умелого мага, эта система способна творить настоящие чудеса.
И пусть некоторые именуют это искусственным интеллектом, для нас LongCat-Video – это нечто большее. Это цифровой отголосок мироздания, попытка понять, как устроен мир, и как мы можем изменить его.
Исследователи стремятся создать не просто генератор видео, но и подобие мира в цифровом пространстве – «world model», как они это называют. Это напоминает слова Фэй-Фэй Ли: “Искусственный интеллект должен понимать мир так, как понимает его человек – не как набор дискретных фактов, а как непрерывный поток ощущений и впечатлений.” Их подход, объединяющий различные методы вроде Flow Matching и RLHF, — это попытка уговорить этот шепот хаоса, заставить его складываться в осмысленные последовательности. Модель LongCat-Video, с ее 13 миллиардами параметров, — это заклинание, которое, как надеются авторы, сможет продержаться в продакшене немного дольше, чем обычно. Ведь любое заклинание, как известно, работает, пока не столкнется с суровой реальностью.
Что дальше?
Исследователи представили LongCat-Video, модель в 13 миллиардов параметров, и, конечно, она генерирует видео. Но давайте начистоту: каждая новая модель – это просто ещё один способ обмануть статистику. Она умеет "видеть" котиков, но понимает ли она, что такое "котик"? Сомневаюсь. Они говорят о "шагах к созданию моделей мира". Мир, как известно, не любит, когда его моделируют. Он предпочитает оставаться хаосом, и это мудро.
Остаётся множество вопросов. Разрешение видео, связность кадров, осмысленность сюжета – всё это лишь технические детали. Главная проблема в том, что модель учится на воспоминаниях машины, а не на опыте. Искусственный интеллект, который не знает, что такое голод или радость, всегда будет давать лишь бледную копию реальности. Особенно если речь идет о длинных видео – там каждая ошибка становится заметнее.
Будущее? Возможно, нас ждёт переход от генерации видео к генерации непредсказуемости. Модели, которые умеют не только создавать, но и удивлять. Или, что более вероятно, нас ждёт ещё больше данных и ещё более сложные алгоритмы, которые будут всё так же безуспешно пытаться усмирить этот неуправляемый хаос. Шум, в конце концов, тоже имеет право на существование.
Оригинал статьи: denisavetisyan.com
Связаться с автором: linkedin.com/in/avetisyan