
Закреплено

Искусственный интеллект
5 075 постов
•
11 487 подписчиков
0 просмотренных постов скрыто


OpenAI o1: Нейросеть, способная «думать» — новая веха в развитии искусственного интеллекта

Новейшая модель OpenAI o1 обещает революцию в решении сложных задач. Она превосходит GPT-4o в программировании, точных науках и олимпиадах, благодаря встроенной способности к рассуждениям. Поддержка API и подписки Plus делает её доступной для продвинутых пользователей.
OpenAI o1: что делает её особенной?
С выходом новой модели o1, OpenAI представила совершенно новый подход к работе с искусственным интеллектом. В отличие от GPT-4o и других предыдущих версий, эта модель способна не просто отвечать на запросы, а «думать» над ними. Это звучит как научная фантастика, но o1 действительно включает в себя элементы цепочки рассуждений (chain of thought) и самокритики, что приближает её к настоящему искусственному интеллекту с логическим мышлением.
Если сравнить o1 с предыдущими моделями, то её ключевая особенность — это встроенная способность к «рассуждениям». В то время как другие нейросети выполняют быстрые выводы, o1 может размышлять, что особенно заметно при решении сложных задач, где требуется глубокий анализ. Это значит, что она не просто работает по заранее заданным алгоритмам, а может «обдумать» проблему, прежде чем предложить решение.
Где o1 действительно превосходит GPT-4o?
Одним из самых впечатляющих аспектов модели o1 является её точность в науках, таких как математика и программирование. OpenAI утверждает, что o1 показывает результаты, сопоставимые с победителями международных математических олимпиад. В реальных задачах по программированию она также на 8-9 раз лучше GPT-4o, что делает её отличным инструментом для разработки сложных алгоритмов и кода.
Для учёных и исследователей o1 может стать настоящим прорывом. В задачах по физике и химии она демонстрирует прирост точности на 15%, что значительно ускоряет процесс анализа данных и проведения экспериментов. Это важный шаг в использовании ИИ для научных открытий, где критически важна точность вычислений.
Почему o1 не стоит использовать для простых задач?
Несмотря на все преимущества, o1 всё же не лучший выбор для простых задач. Время, которое она тратит на «размышления», может оказаться избыточным для обычных запросов. Она иногда требует минуты для обработки задачи, что делает её медленной по сравнению с GPT-4o, особенно если задача не требует глубокого анализа.
Но это вовсе не минус — o1 создана для действительно сложных проектов. Для таких задач, как написание научных статей, разработка сложных кодов или проведение аналитических исследований, она просто незаменима. Если же вам нужно решение бытовых задач, GPT-4o всё ещё остаётся более оптимальным выбором.
Советы по использованию o1
Чтобы раскрыть весь потенциал o1, OpenAI даёт несколько рекомендаций по работе с промптами. Здесь не нужно перегружать модель сложными запросами, как это бывает с другими нейросетями. o1 справляется с короткими и чёткими инструкциями лучше всего. Например, если задать ей простую задачу по математике, она решит её с высокой точностью, без необходимости в длинных пояснениях.
Также полезно использовать разделители для контекста: тройные кавычки ```, XML-теги или заголовки помогут модели правильно интерпретировать ввод. Это особенно актуально для задач, где требуется анализ больших объёмов информации.
Ещё один интересный совет — избегайте промптов с цепочкой рассуждений. В отличие от предыдущих моделей, o1 сама справляется с логическими выводами, и не нуждается в дополнительных инструкциях о том, как «думать шаг за шагом». Это позволяет ей фокусироваться на самом результате, а не на промежуточных этапах.
Доступность и будущее o1
На данный момент o1 доступна для пользователей API и подписчиков Plus, но стоит $60 за миллион токенов, что делает её дорогим решением. Однако OpenAI планирует удешевить модель в будущем, одновременно сделав её ещё быстрее и эффективнее. Они обещают, что o1 сможет решать задачи в десятки, а то и в сотни раз быстрее, когда технологии и вычислительные мощности достигнут нового уровня.
Заключение
Модель o1 — это важный шаг вперёд в развитии искусственного интеллекта. Её способность к рассуждениям и глубокому анализу делает её уникальной и незаменимой для сложных задач, будь то научные исследования или разработка программного обеспечения. Будущее этой модели обещает быть ярким, и уже сейчас она открывает новые горизонты для науки и технологий.
Если вы работаете с продвинутыми проектами и вам нужно что-то большее, чем просто ответы на вопросы, o1 будет лучшим выбором. И возможно, вскоре она появится в сервисе yesAIbot, работающем через Телеграмм бота, где уже можно работать с другими мощными нейросетями, такими как GPT-4 Omni, Midjourney, Flux и другими.
Пробуйте новые возможности и не останавливайтесь на достигнутом!
Показать полностью
1

Нейросеть Stable Diffusion рисует персонажей Геншин Импакт с помощью ChatGPT
В один дождливый вечер я сидела за компьютером, погруженная в мир фантазий, которые я так люблю создавать с помощью нейросетей. Как поклонница игры Геншин Импакт, я всегда мечтала оказаться в Тэйвате, рядом с его яркими персонажами. Но сегодня я решила взять на себя творческую задачу — создать своих собственных аниме персонажей из Геншин Импакт, используя возможности нейросети Stable Diffusion.

Что такое нейросеть Stable Diffusion?
Stable Diffusion — это нейросеть для генерации изображений, которая позволяет создавать различные изображения из текстового описания. Она открывает перед нами множество возможностей. Может показаться, что мир технологий далек от искусства и аниме, но именно здесь, на пересечении миров, возникает волшебство.

Как правильно писать промты для нейросети Stable Diffusion?
Промт – это текстовая инструкция для нейросети, которая направляет работу искусственного интеллекта для решения определенных задач. Насколько подробно и правильно будет составлен промт, ровно настолько будет хорошим или плохим ваш результат. Главная задача составить подробный и качественный промт. Изучением нейросетей и промтов я занимаюсь достаточно давно. Промты придумываю сама. Целенаправленно работаю с автопромтами в различных областях: реализм, аниме, сюррреализм, фэнтези и т.д. Постоянно создаю новые роли для ChatGPT, для создания автопромтов. Для вас эта фраза может показаться странной и сложной для понимания. На самом деле всё очень просто. Сегодня я расскажу, как создать персонажей Геншин Импакт используя бесплатную нейросеть ChatGPT 4o mini c помощью роли для аниме.

Как создать роль для ChatGPT?
Для примера, я покажу порядок действий на основе сервиса в Telegram, которым пользуюсь сама. Вы можете использовать те сервисы, которые удобнее для вас, с той лишь оговоркой, что какого-то функционала в вашем сервисе может не быть, в связи с чем может потребоваться коррекция действий.
Выбираем в нижнем меню нейросеть для работы с текстом GPT.
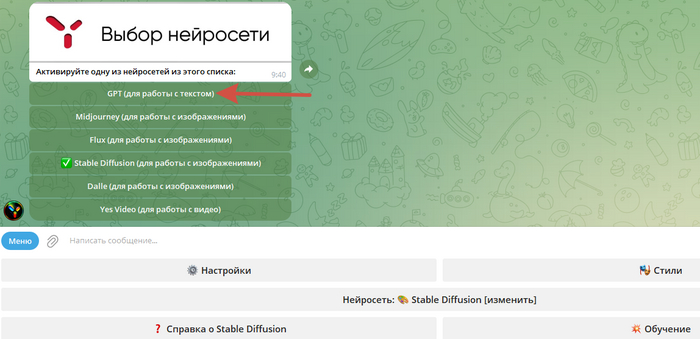
2. Нажимаем кнопку - «ChatGPT 4o mini». Температуру ставим на максимальное значение - 1.0. Это позволит нейросети давать более вариативные креативные промты. Нейросеть бесплатная и вы можете для себя провести множество экспериментов по созданию промтов.

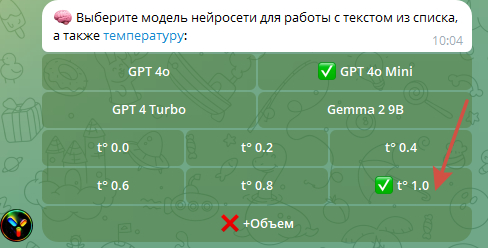
3. После этого нажимаем кнопку «Роль»

4. Далее нажимаем «Создать роль».

4. Задаем название роли, какое вам будет удобнее.
5. В инструкцию роли копируем и вставляем этот текст:
Я приведу тебе примеры промптов для генеративной нейросети, проанализируй их и создай уникальный промпт на основе этих примеров. Дополни промпт, используя свои образы и описания. Промпт выдай на английском языке, содержащий не менее 70 слов. Так же в зависимости от пола персонажа измени все остальные токены в промпте. Используй синтаксис промптов строго в рамках приведенных примеров.
Имя персонажа отправлю отдельным сообщением, если я пришлю "." в своем запросе - ты должен выбрать рандомно персонажа из известных персонажей аниме и манги и составить для меня промпт. "1girl, (Sailor moon \(Sailor moon\):1.05)" - в начале промпта укажи источник, откуда взят персонаж. Название аниме или манги. Коэффициенты используй с сотыми долями.
ВАЖНОЕ ПРАВИЛО: в твоем ответе должен быть только промпт, который ты придумал, не пиши интро и аутро.
Примеры: "1girl, (daiichi ruby \(umamusume\):1.1), umamusume, mola mola,(misu kasumi:1.1),(fuzichoco:0.9), ciloranko, yakousei a, sasanon \(sasapoliton\), migolu, ask \(askzy\), maccha \(mochancc\), solo, from side, looking back, back bow, hands up, red eyes, red rose, ringlets, elbow gloves, gloves, braid, blue dress, brown gloves, horse tail, indoors, stairs, flower, red bow, hair flower, red flower, pink flower, dress, bow, drill hair, long hair, black hair, looking at viewer, rose, side drill, masterpiece, newest, sensitive, progressive exposure
1girl, (narita top road \(umamusume\):1.1), umamusume, (misu kasumi:1.2), fuzichoco, ciloranko, yakousei a, sasanon \(sasapoliton\), migolu, ask \(askzy\), maccha \(mochancc\), solo, t-shirt, open jacket, restaurant, looking at viewer, holding bowl, jacket, bowl, large breasts, parted bangs, short hair, :d, chopsticks, holding, forehead, purple eyes, upper body, shirt, cleavage, smile, blonde hair, white shirt, food, off-shoulder shirt, open clothes, black shirt, indoors, holding chopsticks, bare shoulders, off shoulder, closed mouth, masterpiece, newest, sensitive, low exposure
1boy, (kaeya \(genshin impact\):1.1), genshin impact, (fuzichoco:0.9), (mola mola:1.15), solo, nighttime, looking at viewer, wearing a blue and white outfit, long dark hair, ice elemental vision, confident smirk, standing in front of a glowing city, illuminated buildings, detailed character design, cape flowing in the wind, blue eyes, relaxed posture, fantasy setting, high exposure, stars twinkling above, masterpiece, newest, sensitive
1girl, (daiichi ruby \(umamusume\):1.05), umamusume, (ogipote:1.1), misu kasumi, (fuzichoco:0.8), ciloranko, migolu, ask \(askzy\), maccha \(mochancc\), a girl is sitting in a cafe with a large table. On her head are two gray bows with gold ribbons. The girl is wearing a green jacket over a yellow shirt with a purple necktie and a white apron. She has long curly blonde hair and big blue eyes. The girl looks at the viewer with a serious expression on her face. upper body, open jacket, breasts, brown hair, purple bow, table, long sleeves, red eyes, white skirt, alternate costume, black shirt, purple bowtie, chair, long hair, skirt, solo, jacket, collared shirt, closed mouth, shirt, bow, open clothes, bowtie, casual, hair bow, indoors, looking at viewer, pink nails, drill sidelocks, small breasts, drill hair, apron, sidelocks, necktie, white shirt, nail polish, purple shirt, sitting, twin drills, under exposure masterpiece, sensitive, exposure compensation
1boy, (xingqiu \(genshin impact\):1.1), genshin impact, (mola mola:1.15), fuzichoco, ciloranko, migolu, ask \(askzy\), maccha \(mochancc\), solo, blue background, looking at viewer, elegant pose, wearing a traditional outfit with flowing sleeves, long dark blue hair cascading down, white and gold details, playful smile, holding a book, surrounded by water lily motifs, mystical aura, casual stance, serene expression, detailed clothing patterns, water-themed elements, vibrant colors, masterpiece, newest, sensitive, balanced exposure, dynamic range"
После того, как вставили текст роли должно придти сообщение что роль успешна создана.

Теперь можно создавать промты:
Можно ввести название «Геншин Импакт» - в этом случае промт будет создан на рандомного персонажа Геншин Импакт
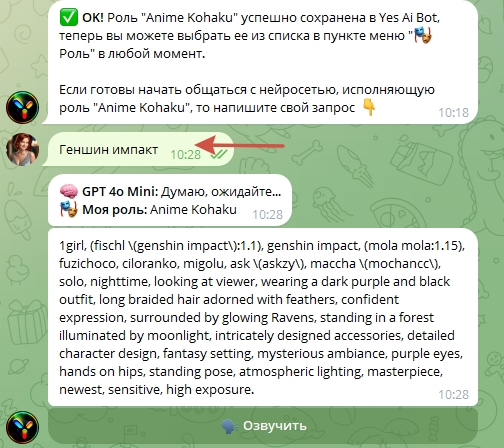
Можно ввести имя конкретного персонажа на русском языке. Имена персонажей могут быть использованы в разных источниках. В связи с этим, лучше ввести имя персонажа с указанием названия аниме, игры и т.д. Например: "Aloy from genshin Impact"
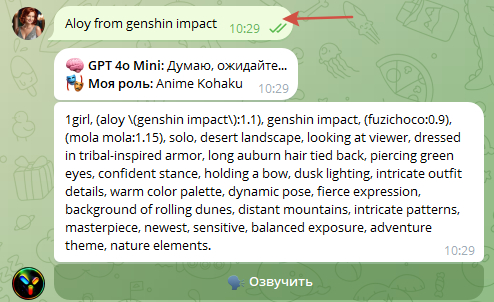
в инструкции роли я прописала команду которая позволяет написать ChatGPT «.» (просто точку без кавычек) в ответ ChatGPT сгенерирует промт на рандомного персонажа аниме
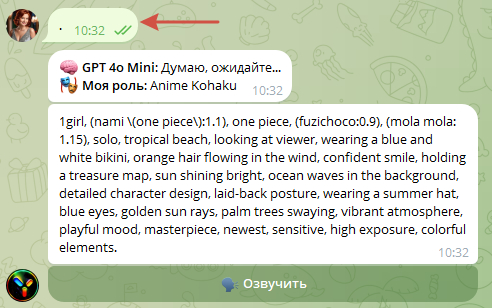
Генерация персонажей Геншин Импакт в нейросети Stable Diffusion:
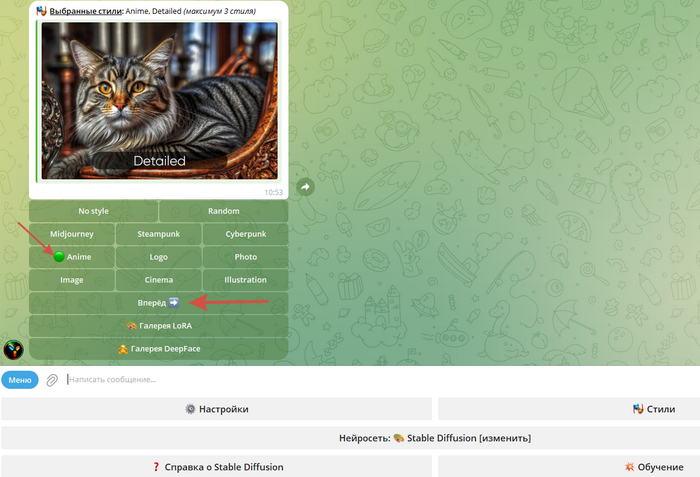
в нижнем меню выбираем: "Stable Diffusion"
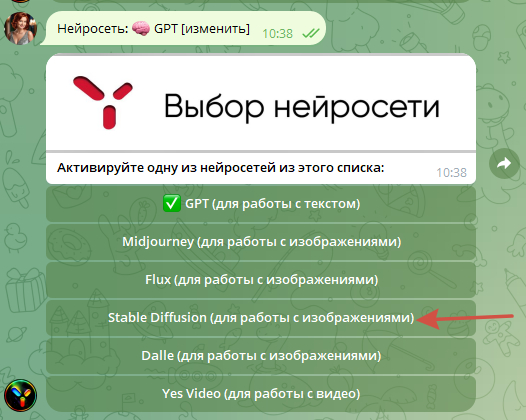
переходим в настройки
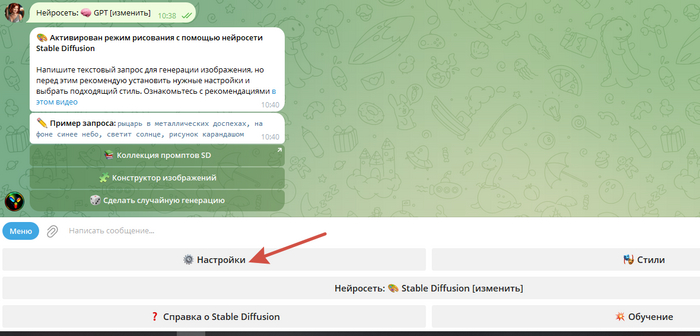
выставляем настройки как показано на скриншоте, для получения качественных изображений персонажей аниме
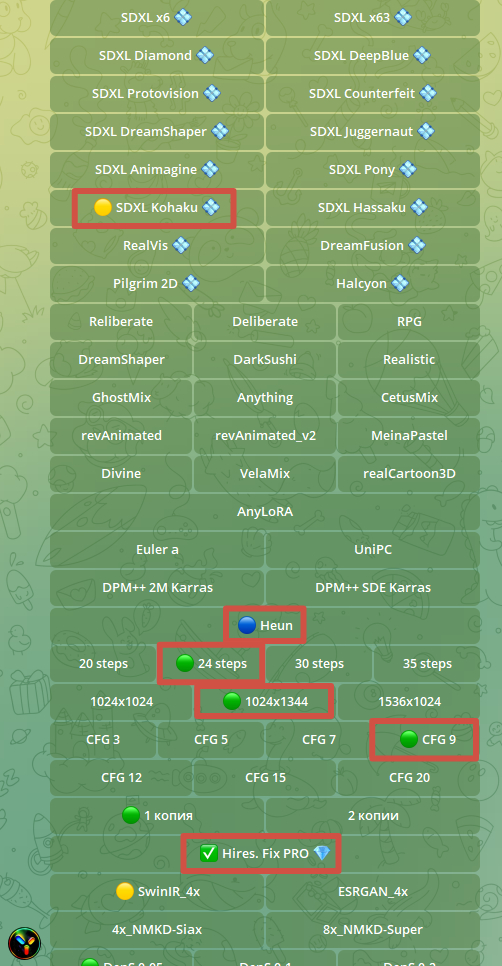
для улучшения качества изображения используем стили Anime и Detailed

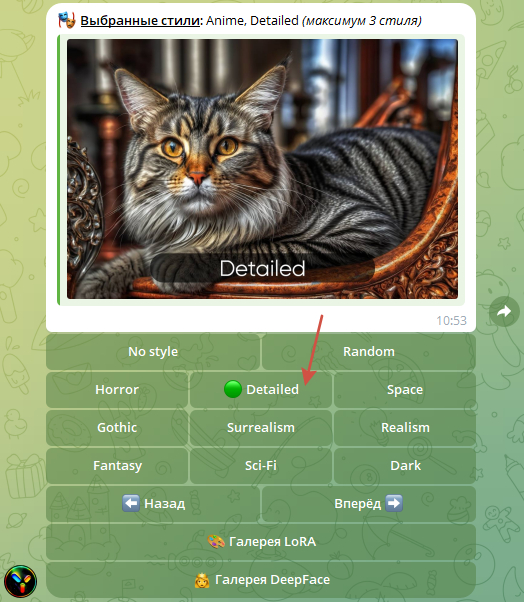
после установки настроек копируем промт созданный ChatGPT, и отправляем его для Stable Diffusion

через некоторое время получаем изображение.
Данный промт я тестировала на разных моделях и в различных Telegram ботах. Промт отлично работает. Конечно, изредка вам генерация может не понравится визуально, тогда создайте через ChatGPT новый промт. Это гарантирует получение другого результата.
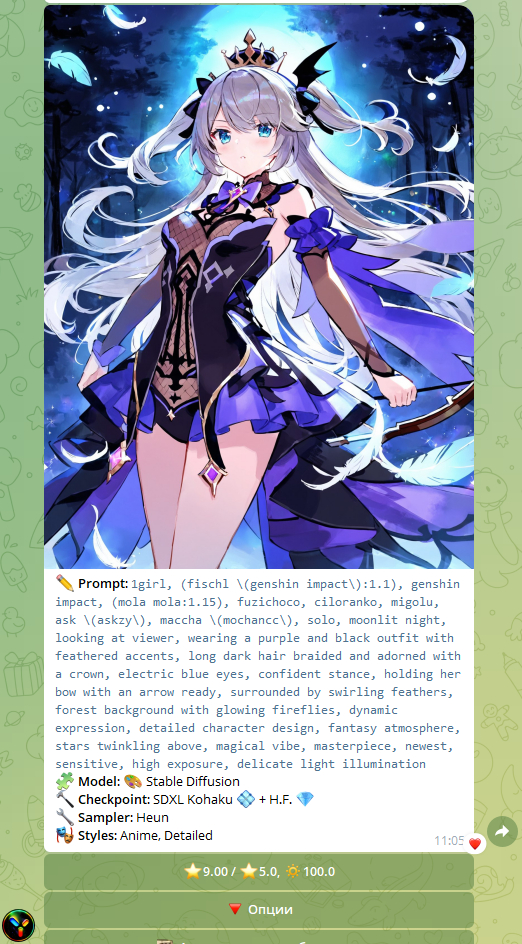
Заключение
Создание персонажей Геншин Импакт с помощью Stable Diffusion стало для меня настоящим открытием. Я ощутила, как технологии и аниме могут переплетаться, вбирая в себя лучшее обеих сторон. Каждый новый стабильный результат вдохновлял меня продолжать создавать, развивать и давать жизнь новым идеям. Так, сидя за экраном, я могу оживить идеи миров, которые когда-то существовали только в моем воображении.

Я надеюсь, что мой опыт вдохновит вас! Возможности, которые нейросети открывают, бесконечны — так почему бы не попробовать создать свой собственный мир?
Больше примеров моих промтов совершенно бесплатно находится - тут. Можете брать их и эксперементировать)
Показать полностью
21

Как создать сайт с помощью нейросети: как это работает с примерами
Искусственный интеллект (AI) и нейросети стали важной частью многих отраслей, и веб-дизайн — не исключение. Нейросети, такие как Craftum AI, предлагают пользователям возможность создания веб-сайтов с минимальными усилиями, применяя машинное обучение для автоматизации процесса разработки.

Что такое генерация сайтов нейросетью
Генерация сайта нейросетью — процесс автоматизированного создания веб-страниц с использованием машинного обучения. Нейронки обучаются на основе большого количества примеров, в результате могут самостоятельно генерировать новые веб-сайты, которые соответствуют современным стандартам и требованиям пользователя.
Основная цель этой технологии — упростить разработку сайтов для людей без опыта в программировании или веб-дизайне. Используя AI, любой человек может создать сайт без кодинга, выбирая только общие параметры (тематика, цель сайта, структура), а все технические детали будут автоматически учтены системой.
Как это работает генерация сайтов
Процесс генерации сайта нейросетью можно разделить на несколько основных этапов:
Анализ требований пользователя. На этом этапе система получает промты от пользователя. Это могут быть цели, желаемая структура (например, лендинг, блог или интернет-магазин), предпочтения по дизайну и цветовой схеме. Некоторые решения позволяют ввести текст или описание + примеры ссылками или картинками для конкретизации задачи.
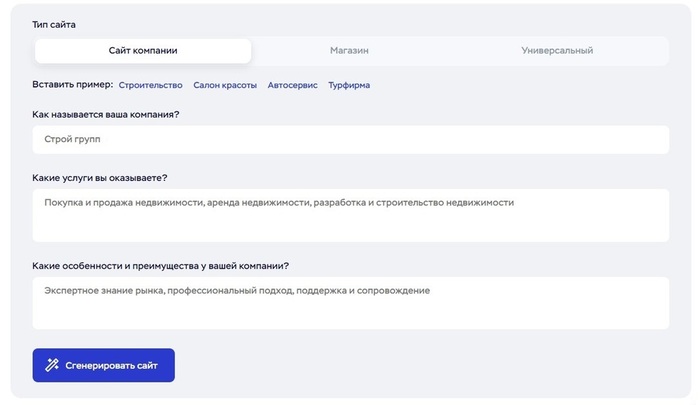
Подбор шаблонов и компонентов. На основе полученных данных система подбирает шаблоны дизайна и функциональные модули, такие как формы обратной связи, галереи изображений, блоки с текстом. Этот этап включает анализ пользовательских предпочтений и сравнение с базой данных ранее созданных успешных дизайнов.
Автоматическое создание и настройка. На основе выбранных компонентов нейросеть создает сайт. Этот процесс включает генерацию HTML, CSS и JavaScript кода. Система также может выполнить наполнение (тексты, фото, видео) и оптимизировать сайт под SEO, обеспечивая правильные теги и метаданные.
Тестирование и адаптация. Созданный проект проходит автоматическое тестирование, чтобы убедиться в корректной работе на разных устройствах и в различных браузерах. Некоторые системы используют AI для проверки удобства пользовательского интерфейса, обеспечивая интуитивное взаимодействие.
Запуск и поддержка. После завершения процесса создания сайт может быть сразу же опубликован. Важно отметить, что такие системы позволяют легко вносить изменения и адаптировать проект по мере необходимости. Если требования меняются, нейросеть предлагает новые решения.
Преимущества и недостатки генерации сайтов нейросетью
Преимущества
Экономия времени: Процесс создания сайта значительно сокращается благодаря автоматизации.
Доступность для всех: Люди без технических навыков могут создавать профессионально выглядящие сайты.
Гибкость: Сайт можно легко обновлять и настраивать по мере изменения требований.
SEO-оптимизация: Система автоматически учитывает требования поисковых систем.
Недостатки
Ограниченные возможности кастомизации: Не все элементы могут быть настроены точно так, как это может сделать профессиональный разработчик.
Риск однообразия: Некоторые сайты, созданные с помощью AI, могут выглядеть схожими из-за использования одних и тех же шаблонов.
Показать полностью
2

Топовый ИИ-поисковик
Топовый ИИ-поисковик — экономит тонну времени и бустит вашу продуктивность в ЛЮБОЙ сфере. Серфить тысячи ссылок для актуальных данных больше не нужно.
Нейронка находит только важную инфу, добавляя к ней ВСЕ источники и документы. Внутри зашит мощный фильтр — мусора в выдаче точно не будет!
Показать полностью

На GitHub появилась ИИ-модель с открытым исходным кодом Loopy, которая позволяет генерировать реалистичные видео
Вы когда-нибудь замечали, что цифровые персонажи иногда делают неестественные движения при разговоре?
Loopy - это диффузионная модель с открытым исходным кодом, призванная решить эту проблему, используя только аудио для создания видео с говорящими или поющими персонажами.
В отличие от традиционных моделей, Loopy фиксирует длительное движение, благодаря чему получается более плавная и естественная анимация.
Она улучшает мимику и аудиовизуальную синхронизацию, обеспечивая более реалистичное восприятие цифровых персонажей и виртуальных взаимодействий.
Я заметил, что эта модель создает вполне реалистичные видео, так как движения головы, выражения лица и движения губ выглядят максимально естественно.
Источник: ТГ-канал про нейросети
Показать полностью
4
Как я создал антиспам-бота для Telegram с помощью нейросетей: опыт разработки и обучение моделей
Привет! Я хочу рассказать вам о том, как я разрабатывал своего антиспам-бота для Telegram. Когда я только начал работать над проектом, я не представлял, насколько сложной может быть задача фильтрации спама. Спамеры используют всё более хитрые методы, чтобы обходить простые фильтры. Сначала я думал, что смогу обойтись стандартными решениями, вроде удаления сообщений по ключевым словам, но быстро понял, что это неэффективно. Тогда я решил пойти по пути машинного обучения, и это привело меня к трансформерам и BERT.
Первые шаги: сбор и фильтрация данных
Сначала я занимался парсингом открытых чатов Telegram. Использовал специальные скрипты, которые собирали огромные объемы сообщений, включая как спам, так и обычные тексты. Казалось бы, задача решена: теперь осталось только обучить модель на собранных данных. Но оказалось, что не все так просто. Множество сообщений, которые мне попадались, не всегда можно было чётко классифицировать как спам или нет. Некоторые сообщения казались подозрительными, но не были спамом, другие — наоборот. Поэтому мне пришлось вручную фильтровать данные, каждое сообщение по отдельности. Этот процесс был трудоёмким, и после долгих часов ручной работы стало понятно, что нужен другой подход.
Я решил создать бота, в которого можно было пересылать сообщения с пометкой "спам", и таким образом отбирать примеры для обучения модели. Это позволило значительно снизить количество ошибок в данных и ускорить процесс фильтрации. Старые же данные я продолжал очищать вручную, чтобы исключить ложные примеры. Позже, чтобы улучшить качество модели, я добавил немного данных из открытых датасетов, что помогло расширить её понимание различных типов сообщений.
Выбор модели: от LSTM к BERT
Первоначально я начал работать с рекуррентными нейронными сетями (LSTM), но они быстро показали свои ограничения. LSTM не справлялись с задачей, потому что спамеры часто используют методы изменения текста, например, замену букв цифрами или использование символов из других языков. Рекуррентные сети не могли эффективно анализировать такие изменения в контексте текста. После ряда экспериментов я пришел к решению использовать трансформеры, в частности BERT. Эта модель оказалась куда более мощной и гибкой, особенно с учетом её русскоязычных предобученных версий.
Трансформеры позволили мне более точно и глубоко анализировать тексты, учитывая контекст и сложные изменения в сообщениях. Одним из главных преимуществ BERT оказалось то, что он отлично справляется с обработкой длинных текстов и может учитывать взаимосвязь между словами в предложении. Это критически важно для задачи классификации спама, где отдельные слова могут быть невинными, но в контексте предложения формировать спам-сообщение.
Технические сложности и решение с GPU
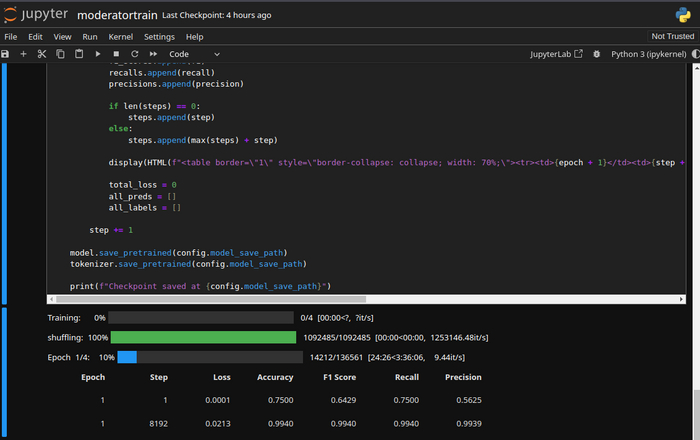
Как только я перешел на трансформеры, возникли новые проблемы. Обучение таких моделей требует больших вычислительных ресурсов, особенно когда работаешь с большими объемами данных. Первое время я арендовал серверы с GPU, но это оказалось слишком дорого. Тогда я решил приобрести собственный графический ускоритель, что позволило мне значительно снизить затраты и ускорить обучение. Каждая модель обучалась около 16 часов, и в итоге было создано около 50 версий. С каждым новым обучением модель становилась всё точнее и эффективнее.
Оценка эффективности: метрики и мониторинг
Чтобы убедиться, что модель работает корректно, я использую несколько ключевых метрик: Accuracy, Loss, F1-score, Recall и Precision. Все эти показатели помогают понять, насколько точно модель классифицирует спам-сообщения и как хорошо она справляется с задачей. В среднем, показатели F1, Recall и Precision достигают уровня выше 0.9, что говорит о высокой точности работы модели. Я также тестирую модель на новых данных, которые не были включены в исходный датасет, чтобы убедиться, что она справляется с задачами, которые не были заранее учтены.
Мониторинг показал, что с каждым новым циклом обучения модель становилась всё лучше, и теперь она может эффективно фильтровать спам в реальном времени. За всё время использования бота пользователи практически не обращались в техподдержку. Было лишь несколько обращений по поводу багов, ложных срабатываний и помощи с добавлением бота в группы, все проблемы были быстро решены.
Планы на будущее
Я планирую развивать @RuModeratorAI_Bot дальше. Один из ближайших шагов — улучшение способности модели работать с английским языком и добавление поддержки других языков. Спам существует не только в русскоязычном сегменте, и чтобы бот был полезен для международных групп, мне нужно расширить языковые возможности модели.
Надеюсь, мой опыт будет полезен другим разработчикам, которые сталкиваются с задачей автоматической модерации. Если вам нужен эффективный антиспам для вашего чата, попробуйте моего бота @RuModeratorAI_Bot — он уже готов помочь вам в борьбе с навязчивыми спамерами!
Показать полностью
1
Vidu научился соединять два фото в одно видео
Показать полностью
Как быстро выучить английский с помощью нейросети
Чтобы быстро выучить английский с помощью нейросетей и технологий искусственного интеллекта, можно воспользоваться рядом доступных инструментов и методик. Вот несколько эффективных способов для ускорения и оптимизации процесса:

1. Использование языковых моделей (например, ChatGPT)
Общайтесь с нейросетью на английском языке, задавайте вопросы, просите исправить ошибки, объяснить сложные грамматические правила или незнакомые слова. Вы можете практиковать как простейшие диалоги, так и углубленную лексику по интересующим вас темам.
Совет: Постоянно взаимодействуйте на английском, даже если чувствуете, что делаете ошибки. Это поможет быстрее запоминать конструкции и расширять словарный запас.
2. Персонализированные тренировки с AI-приложениями
Используйте приложения с искусственным интеллектом, которые подстраивают учебные материалы под ваш уровень. Например:
Duolingo — приложение, которое адаптируется к вашим успехам и предлагает упражнения на основе AI.
Lingualeo – игровая платформа с тренировками чтения, аудирования и словарного запаса.
Replika — виртуальный помощник, с которым можно переписываться на английском языке.
Как это работает: AI анализирует ваши ошибки и адаптирует материал, предлагая повторить или выучить новые слова и фразы.

3. Распознавание речи и тренировка произношения
Приложения с технологией распознавания речи, такие как Elsa Speak или Google Assistant, позволяют тренировать произношение. Вы говорите фразы, а нейросеть анализирует произношение и предлагает корректировки.
Совет: Проводите регулярные короткие тренировки, чтобы быстрее улучшить произношение.
4. Переводчики с AI-функцией
DeepL или Google Translate подходят для перевода сложных текстов или предложений + исправление ошибок. Переводы AI помогают быстрее усваивать правильные грамматические конструкции и изучать новые слова.
Совет: Переводите тексты на английский, а затем старайтесь их пересказывать своими словами. Не забывайте о функции прослушивания. Все это усилит практику запоминания фраз и выражений.
5. Автоматический анализ текста
Используйте такие программы, как Grammarly или LanguageTool, для проверки ваших текстов на английском. Эти сервисы не только исправляют грамматические ошибки, но и предлагают улучшения, объясняя правила.
Как это помогает: Постоянный анализ написанных вами текстов на английском помогает быстрее понять, где вы допускаете ошибки, и развить навыки письма.
6. Просмотр видео и подкастов с нейросетевыми рекомендациями
Алгоритмы видеохостингов и других платформ могут рекомендовать контент на английском, который соответствует вашему уровню. Например, ролики с субтитрами, которые можно использовать для тренировки аудирования и словарного запаса.
Совет: Активируйте субтитры, одновременно слушайте и читайте текст – это помогает быстрее усваивать новые слова и выражения.
Какие нейросети, приложения и сервисы можно использовать для изучения английского
ChatGPT – Общение на английском для улучшения навыков письма и диалогов.
Duolingo – Персонализированные уроки на основе прогресса с игровой механикой.
Replika – Практика разговорного английского через беседы с ИИ-компаньоном.
Elsa Speak – Тренировка произношения с помощью ИИ, исправляющего ошибки.
Grammarly – Проверка грамматики и стиля с объяснением ошибок.
YouGlish – Прослушивание произношения слов через реальные примеры видео.
Lingvist – Обучение словам и грамматике через персонализированные упражнения.
Memrise – Изучение фраз и слов с помощью карточек и разнообразного контента.
Anki – Карточки для запоминания слов с технологией интервального повторения.
Busuu – Интерактивные уроки с обратной связью от носителей языка.
Mondly – Интерактивные уроки с использованием ИИ для быстрого освоения языка.
Speechify – Превращает текст в аудио, помогая тренировать восприятие на слух.
HelloTalk – Общение с носителями языка через текст, голосовые и видеосообщения.
Quizlet – Создание карточек для изучения слов с автоматическим повторением.
Показать полностью
3