
Закреплено

Искусственный интеллект
5 077 постов
•
11 491 подписчик
0 просмотренных постов скрыто


Как дообучить LLaMA бесплатно и без программирования: как создать тупого друга
В этой статье я расскажу как я смог бесплатно и без мощного железа дообучить LLaMA на диалогах с друзьями в ВК, чтобы сделать чат бота, который копирует наш стиль общения, оживляет разговор в чате и просто пишет странные и смешные вещи. В статье будет мало терминов, тут я простым языком расскажу как вы можете обучить большую языковую модель.
Прошло уже около полугода как Meta* случайно слили свою языковую модель LLaMA. А недавно они сами выложили в открытый доступ ее 2-ую версию. Для понимания масштаба - на обучение Meta* потратили более 3 311 616 GPU часов. Это примерно 378 лет работы одной мощной видеокарты.

Cразу скажу, что я уже публиковал эту статью на Хабр. Но хочу теперь попробовать начать писать статьи на Пикабу, так что я буду очень рад любым комментариям и отзывам. Надеюсь пользователям Пикабу эта статья тоже зайдет)
Те, кто интересовался темой языковых моделей, уже, наверное, знают, что первую версию llama энтузиасты почти сразу после слива оптимизировали для работы на обычных процессорах и на нейроускорителях Apple, которые стоят в их процессорах. При этом на M1 процессоре LLaMA стала работать очень быстро, выдавая более 10 токенов(токен - это слово, часть слова или буква) в секунду, это быстрее чем бесплатный ChatGPT на тот момент. Еще через пару недель ее дообучили ребята из Стэнфорда, чтобы она понимала концепцию вопрос-ответ и могла давать ответы и выполнять задачи.
Что потребуется для запуска нейронки
Есть две версии модели: LLaMA и LLaMA 2. LLaMA есть в размерах 7B, 13, 30B, 65B, LLaMA 2 - в размерах 7B, 13B и 70B. 7B весит примерно 13 гб, 65B - 120 гб. Но не торопитесь ужасаться, во-первых, как я уже писал, ее можно запустить не только на видеокарте, она хорошо работает и на процессоре, а во вторых, для запуска на обычных компьютерах применяют квантизацию (quantization) - это сжатие всех весов нейронов. В оригинальной версии вес каждого нейрона 16 бит, но их сжимают до 8, 4 и даже до 2 бит. Чаще всего используют сжатие до 4 бит, LLaMA 7B при таком сжатии весит 3.9 гб и требует немного больше 4 гб оперативной памяти и обычный процессор.
Что будем обучать и что потребуется
В данной статье я покажу как я дообучал LLaMA 7B и LLaMA 2 7B. Если готовы заплатить за аренду видеокарт, то можете обучить и модели покрупнее. Обучение будем проводить для нейронки в оригинальном размере (16 битовые веса), создав Lora модуль (не буду тут рассказывать, что это, если вкратце, то это алгоритм обучающий лишь несколько дополнительных слоев для нейросети, которые корректируют ее работу, это намного менее требовательно, чем полное дообучение). Для этого пока обязательно нужна видеокарта, то есть нужно около 15 гб видеопамяти.
На этом можно было бы остановиться, подумав, что за такое железо точно придется платить. Но пока изучал эту тему, я увидел, что один парень на гитхабе написал о возможности запустить обучение бесплатно на Google Colab. Честно говоря, я был в шоке, когда понял что google совершенно бесплатно дает доступ к машине с 13.6 гб оперативки, с Nvidia Tesla T4 на 16 гб видеопамяти, около 78 гб хранилища и очень быструю сеть (скорость загрузки нейросети там доходила до 200 мегабайт в секунду). Конечно всю эту радость дают не навсегда, а на неопределенный срок, и отнять это могут в любой момент. У меня получалось обучать по часа 4.

Данные для обучения
Для обучения я взял историю диалога с друзьями в ВК. В ВК можно получить по запросу все данные о себе, которые у них есть, в том числе истории всех переписок. Чтобы подготовить полученные данные, я воспользовался первым попавшимся на github репозиторием для парсинга сообщений в бэкапе вк и сделал форк с изменениями для создания датасета. Через код в Jypyter вы сможете получить json файл с датасетом для обучения.
Обучение
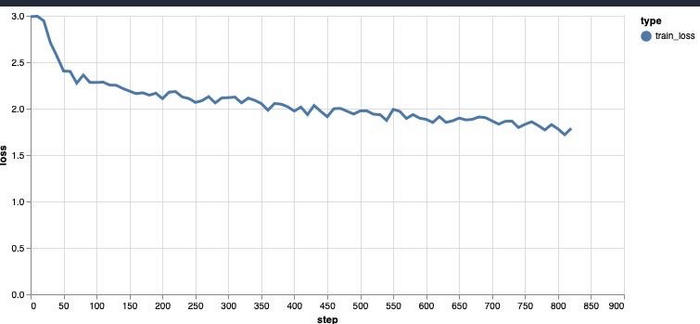
Для обучения можно воспользоваться этим проектом, я сделал от него форк, добавив шаблон для обучения на простом тексте (оригинальный репозиторий имеет шаблоны только для обучения концепции вопрос-ответ). Вот мой форк и вот проект которые вы можете запустить в гугл колабе, он подтянет мой форк. В первых нескольких полях вы можете поменять папку на Google Disk, куда будут сохраняться результаты обучения, нужно не меньше 300 мб. Также можете вместо модели "sharpbai/Llama-2-7b-hf" выбрать другую, например llama 7b первой версии (decapoda-research/llama-7b-hf), найти вы их можете на huggingface. Лучше всего брать те, которые разбиты на множество файлов (такие требуют меньше памяти при загрузке). Те, что не разбиты, не всегда загружаются на бесплатном google colab (требуется больше памяти).
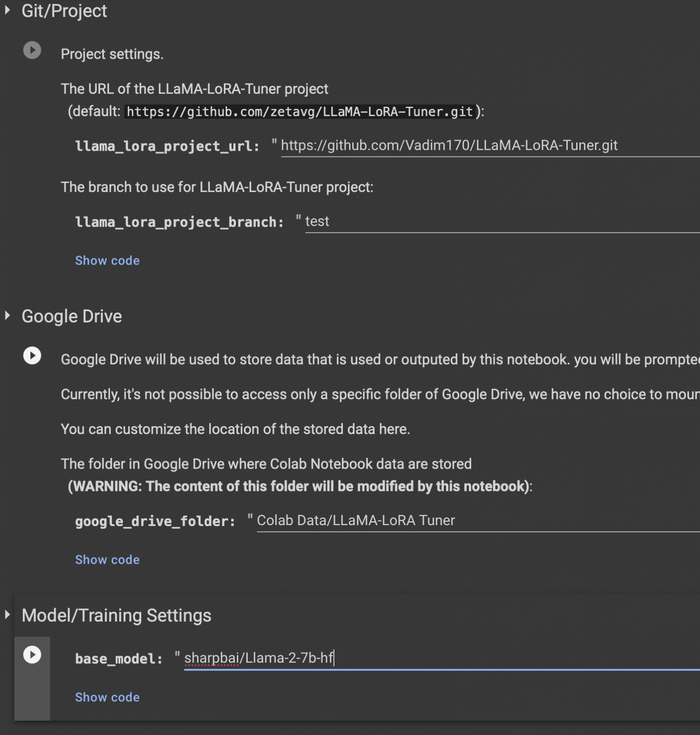
Пакеты не всегда ставятся сразу в виртуальной машине, не стоит пугаться, иногда требуется нажать Runtime -> Restart runtime. На второй раз пакеты ставятся успешно.
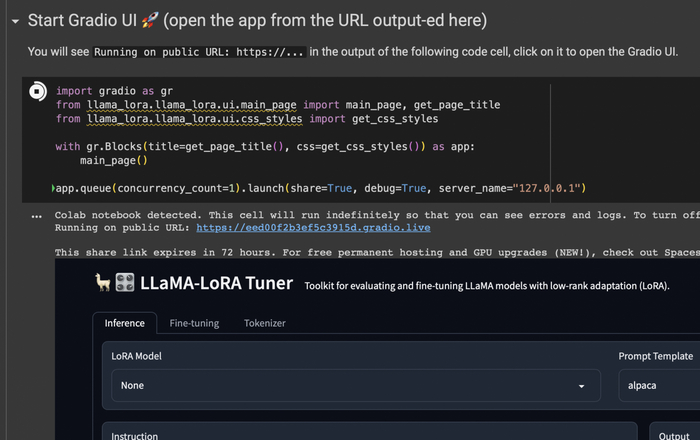
После того как языковая модель скачается и загрузится в память, вы можете воспользоваться веб интерфейсом, чтобы настроить параметры обучения.
Ссылка будет выведена в формате: Running on public URL: https://...
Сразу можете переходить во вкладку Fine tuning, в поле Template выставлять "my_sample", в поле Format "JSON Lines". my_sample - это тот простой шаблон промптов, который я добавил, в нем нет ничего кроме input и output. Далее нужно либо скопировать содержимое файла датасета, либо открыть его, скопировав на машину google colab.
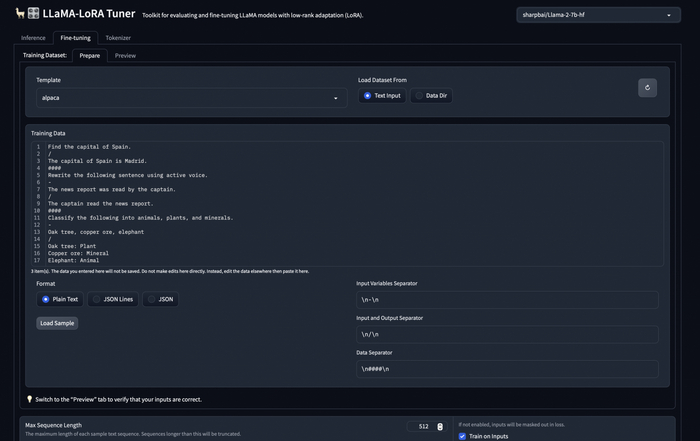
После можете посмотреть превью данных для обучения во вкладке Preview. Еще на этой вкладке браузер меньше тупит, не пытаясь отобразить все данные для обучения.
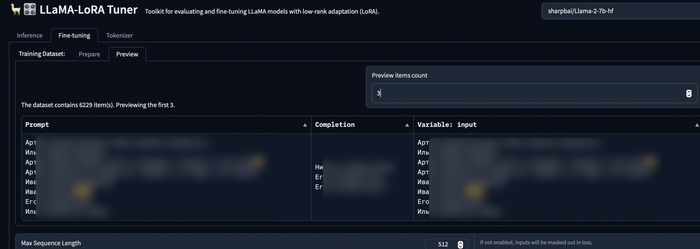
Остается только выставить параметры обучения, в целом можно оставить по умолчанию, но вот поля, которые я менял:
Max Sequence Length - Влияет на максимальную длину текста в наборе датасета. Все данные из датасета, длина которых превышает эту, не будут использоваться в обучении. (На русском почти всегда длина это количество букв). Очень большое число может привести к переполнению памяти на бесплатной машине.
Train on Inputs - Эту галочку лучше поставить, чтобы модель обучалась и на input тексте, и на output.
Micro Batch Size - Грубо говоря, указывает количество данных, которое берется для обучения за раз. Очень большое число может привести к переполнению памяти на бесплатной машине. Я оставлял в основном 8.
Gradient Accumulation Steps - Не разбирался как работает, но я поднимал до двух. Судя по описанию, ускоряет обучение, как и Micro Batch Size, но не увеличивает потребляемый объем памяти.
Epochs - Количество эпох обучения. Можно смело ставить больше, все равно остановим обучение руками, или гугл сам остановит машину часа через 4.
Learning Rate - Коэффициент обучаемости, влияет на скорость, но слишком большой может привести к плохому обучению, я оставлял 0.0003.
Saved Checkpoints Limit - Максимальное число чекпоинтов, ставьте побольше.
Steps Per Save - Количество шагов перед сохранением бэкапа. Ставьте 200-300, чтобы почаще сохраняться и меньше терять в случае отключения машины гуглом.
LORA Model Name - Название папки на гугл диск, в которую будут сохраняться бэкапы.
Позже еще понадобится раздел Continue from Model для продолжения обучения с последнего чекпоинта.
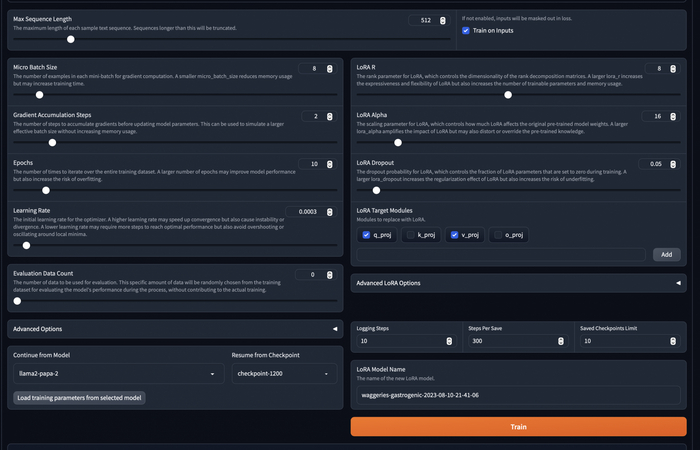
В процессе обучения вы будете видеть примерно такой график. Я обычно дожидался ошибки примерно до 1.1. Дольше у меня не хватало терпения).
Теперь, зная как можно бесплатно дообучить llama, вы можете создать тупого бота симулирующего участника в диалоге с друзьями, он, конечно, не будет кидать мемы и понимать глубокий смысл, но может поугорать за компанию или написать тупую шутку. Можно попробовать сделать что-то и посерьезнее, например, ПО системы для написания ответов на письма или откликов на фриланс бирже. Применений может быть много, но стоит понимать что LLaMA 7B все же плоховата в работе с русским, так как мало его учила.

Спасибо больше за внимание, надеюсь статья была для вас полезна! Буду рад любым коментариям и дополнениям!
Я выложил пару сравнений работы дообученной и простой llama 2 7B в телеграм канале, который недавно создал, буду стараться там регулярно выкладывать интересные мысли про программирование, нейросети и информационную безопасность.
Также выложу там инфу про то, как я поднял llama на raspberry pi для бота в телеграмме.
* Meta - признана экстремистской организацией и запрещена в России.
Показать полностью
9

Искусственное интеллектуальное
Ещё раз о наболевшем. Что будет, если, например, ии начнёт обманывать своего создателя? В кроется ли этот обман когда либо и не слишком поздно для человечества?
А ччто будет, если ии решит Разработать собственный под-ии внутри себя, для решения собственных неизвестных нам задач?
Смодем лли мы вообще с определённого этапа контролировать искусственный интеллект?

Meta обнародовала раннюю версию инструмента для перевода с помощью искусственного интеллекта, который работает с 200 языками
/ Амбиции Meta по созданию "универсального переводчика" остаются в силе

Конгломерат социальных сетей Meta создал единую модель искусственного интеллекта, способную переводить на 200 различных языков, в том числе и на те, которые не поддерживаются существующими коммерческими инструментами. Компания выложила проект в открытый доступ в надежде на то, что другие разработчики будут использовать его в своей работе.
ИИ-модель является частью амбициозного научно-исследовательского проекта Meta по созданию так называемого "универсального переводчика речи", который компания считает важным для развития многих платформ - от Facebook и Instagram до таких развивающихся областей, как VR и AR. Машинный перевод не только позволяет компании Meta лучше понимать своих пользователей (и тем самым улучшать рекламные системы, которые приносят 97% ее доходов), но и может стать основой "убийственного" приложения для будущих проектов, таких как очки дополненной реальности.
Конгломерат социальных сетей Meta создал единую модель искусственного интеллекта, способную переводить на 200 различных языков, в том числе и на те, которые не поддерживаются существующими коммерческими инструментами. Компания выложила проект в открытый доступ в надежде на то, что другие разработчики будут использовать его в своей работе.
ИИ-модель является частью амбициозного научно-исследовательского проекта Meta по созданию так называемого "универсального переводчика речи", который компания считает важным для развития многих платформ - от Facebook и Instagram до таких развивающихся областей, как VR и AR. Машинный перевод не только позволяет компании Meta лучше понимать своих пользователей (и тем самым улучшать рекламные системы, которые приносят 97% ее доходов), но и может стать основой "убийственного" приложения для будущих проектов, таких как очки дополненной реальности.
Переводы с помощью этой модели, безусловно, не будут безупречными
Эксперты в области машинного перевода сообщили The Verge, что последнее исследование Meta является амбициозным и основательным, но отметили, что качество некоторых переводов модели, скорее всего, будет значительно ниже, чем у более популярных языков, таких как итальянский или немецкий.
"Основной вклад здесь - это данные", - сказал The Verge профессор Александр Фрейзер, эксперт по вычислительной лингвистике из LMU Munich (Германия). "Что важно, так это 100 новых языков [которые могут быть переведены с помощью модели Meta]".
Достижения Meta, как это ни парадоксально, обусловлены как масштабом, так и направленностью ее исследований. В то время как большинство моделей машинного перевода работают лишь с несколькими языками, модель Meta является всеобъемлющей: это единая система, способная переводить в более чем 40 000 различных направлениях между 200 различными языками. Однако Meta также заинтересована в том, чтобы включить в модель "языки с низким уровнем ресурсов" - языки, на которых имеется менее 1 млн. переведенных пар предложений. К ним относятся многие африканские и индийские языки, которые обычно не поддерживаются коммерческими средствами машинного перевода.
"Что нужно сделать, чтобы создать технологию перевода, которая будет работать для всех?"
Научный сотрудник Meta AI Анжела Фан, работавшая над проектом, рассказала изданию The Verge, что на создание технологии перевода ее вдохновило недостаточное внимание, уделяемое в этой области языкам с более ограниченными исходными ресурсами.
"Перевод не работает даже для тех языков, на которых мы говорим, поэтому мы и начали этот проект", - сказала Фан. У нас есть такая мотивация - "что нужно сделать, чтобы создать технологию перевода, которая будет работать для всех?".
По словам Фан, модель, описанная в исследовательской статье, уже тестируется для поддержки проекта, помогающего редакторам Википедии переводить статьи на другие языки. Методы, разработанные при создании модели, в скором времени будут также интегрированы в инструменты перевода компании Meta.
Как оценивать перевод?
Перевод - сложная задача и в лучшие времена, а машинный перевод, как известно, может быть нестабильным. При масштабном применении на платформах Meta даже небольшое количество ошибок может привести к катастрофическим последствиям, как, например, в случае, когда Facebook неправильно перевел сообщение палестинца "С добрым утром" как "навреди им", что привело к его аресту израильской полицией.
Для оценки качества работы новой модели Мета создала тестовый набор данных, состоящий из 3001 пары предложений для каждого языка, на который рассчитана модель, каждое из которых было переведено с английского на язык перевода человеком, являющимся профессиональным переводчиком и носителем языка.
Исследователи прогнали эти предложения через свою модель и сравнили машинный перевод с эталонными человеческими предложениями с помощью общепринятого в машинном переводе эталона, известного как BLEU (BiLingual Evaluation Understudy).
Модель Meta позволила улучшить показатели, но они не могут рассказать всю историю.
BLEU позволяет исследователям присваивать числовые баллы, измеряющие степень совпадения пар предложений. По утверждению компании Meta, ее модель позволяет улучшить показатели BLEU на 44% для всех поддерживаемых языков (по сравнению с предыдущими современными разработками). Однако, как это часто бывает в исследованиях в области ИИ, оценка прогресса на основе контрольных показателей требует контекста.
Хотя показатели BLEU позволяют исследователям сравнивать относительный прогресс различных моделей машинного перевода, они не являются абсолютным показателем способности программного обеспечения создавать качественные переводы.
Помните: Набор данных Meta состоит из 3001 предложения, и каждое из них было переведено только одним человеком. Это позволяет судить о качестве перевода, но всю выразительность языка невозможно отразить на столь малом фрагменте реального языка. Эта проблема ни в коем случае не ограничивается Meta - она касается всех работ по машинному переводу и особенно остро проявляется при оценке языков с ограниченными ресурсами, - но она показывает масштаб проблем, стоящих перед этой областью.
Кристиан Федерманн, главный менеджер по исследованиям, занимающийся вопросами машинного перевода в компании Microsoft, считает, что проект в целом "заслуживает похвалы" за стремление расширить сферу применения программ машинного перевода за счет менее распространенных языков, но отмечает, что сами по себе оценки BLEU могут дать лишь ограниченную оценку качества результата.
"Перевод - это творческий, генеративный процесс, в результате которого может получиться множество различных переводов, одинаково хороших (или плохих)", - сказал Федерманн в интервью The Verge. Невозможно определить общие уровни "хорошести" по шкале BLEU, поскольку они зависят от используемого тестового набора, его эталонного качества, а также от свойств, присущих исследуемой языковой паре".
По словам Фэн, оценки BLEU были также дополнены человеческой оценкой, и эти отзывы были очень позитивными, а также вызвали некоторые неожиданные реакции.
"Один из действительно интересных феноменов заключается в том, что люди, говорящие на языках с низким уровнем ресурсов, часто имеют более низкую планку качества перевода, поскольку у них нет другого инструмента", - сказала Фэн, которая сама является носителем языка с низким уровнем ресурсов - шанхайского. Они очень щедры, и поэтому нам приходится возвращаться и говорить: "Нет, вы должны быть очень точны, и если вы видите ошибку, скажите об этом".
Дисбаланс сил в корпоративном ИИ
Работа над переводом с помощью искусственного интеллекта часто представляется как однозначное благо, однако создание такого программного обеспечения сопряжено с особыми трудностями для носителей языков с низкими ресурсами. Для некоторых сообществ внимание "больших технологий" просто нежелательно: они не хотят, чтобы инструменты, необходимые для сохранения их языка, находились в чьих-либо руках, кроме их собственных. Для других проблемы не столько экзистенциальные, сколько связанные с качеством и влиянием.
Некоторые сообщества просто не хотят, чтобы их язык контролировали большие технологии.
Инженеры Meta изучили некоторые из этих вопросов, проведя интервью с 44 носителями языков с низким уровнем ресурсов. В ходе интервью был отмечен ряд положительных и отрицательных моментов, связанных с открытием их языков для машинного перевода.
Одним из положительных моментов, например, является то, что такие инструменты позволяют носителям языка получить доступ к большему количеству медиа и информации. С их помощью можно переводить богатые ресурсы, такие как англоязычная Википедия и учебные тексты. В то же время, если носители языков с низкими ресурсами будут потреблять больше медиа-материалов, созданных носителями языков с лучшей поддержкой, это может снизить стимулы к созданию таких материалов на своем родном языке.
Сбалансировать эти вопросы непросто, и проблемы, возникшие даже в рамках этого недавнего проекта, показывают, почему. Так, например, исследователи Meta отмечают, что из 44 носителей языков с низкими ресурсами, которых они опросили для изучения этих вопросов, большинство были "иммигрантами, живущими в США и Европе, и около трети из них идентифицируют себя как работники технического сектора" - это означает, что их точка зрения, скорее всего, отличается от точки зрения их родного сообщества и изначально предвзята.
Профессор Фрейзер из LMU Munich отметил, что, несмотря на это, исследование, безусловно, было проведено "в том ключе, который становится все более характерным для привлечения носителей языка", и что такие усилия "заслуживают похвалы".
Показать полностью
Осенью Google выпустит ИИ-систему Gemini, которая «похоронит» ChatGPT — над ней работает Сергей Брин
Осенью Google планирует представить свой новый и наиболее масштабный продукт на основе ИИ — Gemini. Разработанный специалистами из Google Brain и DeepMind, он не только будет конкурировать с популярным чат-ботом ChatGPT, но и, возможно, превзойдёт программное решение OpenAI.

Появление в 2022 году чат-бота ChatGPT заставило Google задуматься о будущем своего поискового бизнеса. С тех пор компания активно демонстрирует свою приверженность развитию ИИ. После запуска собственного чат-бота Bard в марте, компания продолжает интегрировать технологии машинного обучения в свои продукты.
Gemini объединяет возможности больших языковых моделей и генерацию изображений на базе ИИ. Это означает, что Gemini сможет не только генерировать текст, но и создавать контекстные изображения. Кроме того, Google рассматривает возможность добавления других функций, например, анализа блок-схем или голосового управления программами.
Gemini, вероятно, станет основой для многих продуктов Google, включая корпоративные приложения, такие как Google Docs. Разработчикам нужно будет оплачивать доступ к Gemini, используя арендованные серверы на Google Cloud. Подробности станут известны к концу года, когда Google представит Gemini разработчикам приложений.
В работе над Gemini участвуют бывшие члены команд Google Brain и DeepMind, включая Пола Бархама (Paul Barham) и Тома Хеннигана (Tom Hennigan). Особое внимание привлекает участие сооснователя Google Сергея Брина (Sergey Brin), который играет ключевую роль в оценке и обучении ИИ-моделей Gemini. Google использует транскрибацию видео на YouTube для обучения Gemini, однако юристы компании тщательно следят за тем, чтобы не нарушать авторские права.
Запуск Gemini подчёркивает стремление Google к лидерству в области ИИ. Этот продукт может стать новым этапом в развитии технологий машинного обучения, предоставляя пользователям и разработчикам более широкие возможности и инструменты. В то время как конкуренция в этой области усиливается, Google делает ставку на инновации и качество, чтобы сохранить свою доминирующую позицию на рынке.
Источник:
Показать полностью
NVIDIA продаёт ИИ-ускорители H100 с наценкой в 1000 %, но спрос на них только растёт
NVIDIA получает до 1000 % выручки с каждого проданного специализированного графического ускорителя H100, предназначенного для задач, связанных с искусственным интеллектом. Об этом утверждает журналист издания Barron Тэ Ким (Tae Kim), ссылающийся на анализ консалтинговой компании Raymond James.

В настоящий момент стоимость каждого ускорителя NVIDIA H100 в зависимости от региона продаж и поставщика в среднем составляет $25–30 тыс. При этом речь идёт о менее дорогой PCIe-версии указанного решения. По оценкам Raymond James, стоимость использующегося в этом ускорителе графического процессора, а также дополнительных материалов (печатной платы и других вспомогательных элементов) составляет $3320. К сожалению, Ким не уточняет глубину анализа расчёта стоимости и не поясняет, включены ли в этот показатель такие факторы, как затраты на разработку, зарплата инженеров, а также стоимость производства и логистики.
Разработка специализированных ускорителей требует значительного времени и ресурсов. По данным того же портала Glassdoor, средняя зарплата инженера по аппаратному обеспечению в NVIDIA составляет около $202 тыс. в год. Речь идёт только об одном инженере, но очевидно, что при разработке тех же H100 работала целая команда специалистов, а на саму разработку были затрачены тысячи рабочих часов. Всё это должно учитываться в конечной стоимости продукта.
И всё же очевидно, что сейчас NVIDIA в вопросе поставок аппаратных средств для ИИ-вычислений находится вне конкуренции. На специализированные ускорители «зелёных» сейчас такой спрос, что они распродаются ещё задолго до того, как попадают на условные полки магазинов. Поставщики говорят, что очередь за ними растянулась до второго квартала 2024 года. А с учётом последних оценок аналитиков, согласно которым к 2027 году рынок ИИ-вычислений вырастет до $150 млрд, ближайшее будущее NVIDIA видится точно безбедным.
С другой стороны, для рынка в целом высокий спрос на ускорители ИИ-вычислений имеет свои негативные последствия. В последних отчётах аналитиков говорится, что продажи традиционных серверов (HPC) в глобальном масштабе сокращаются. Основная причина падения спроса заключается в том, что гиперскейлеры и операторы ЦОД переключают внимание на системы, оптимизированные для ИИ, в которых используются решения вроде NVIDIA H100. По этой причине тем же производителям памяти DDR5 пришлось пересмотреть свои ожидания относительно распространения нового стандарта ОЗУ на рынок, поскольку операторы ЦОД сейчас активно инвестируют именно в ускорители ИИ, а не в новый стандарт оперативной памяти. На фоне это ожидается, что уровень внедрения DDR5 достигнет паритета с DDR4 только к третьему кварталу 2024 года.
Источник:
Показать полностью
Эрик Шмидт создаёт глобальный проект, в котором объединит ИИ и научные исследования
Бывший генеральный директор Google Эрик Шмидт создаёт новый проект для решения больших научных задач с помощью искусственного интеллекта. Некоммерческая организация будет строиться на принципах, которые когда-то разделяли в OpenAI, и соберёт лучших учёных и ИИ-специалистов, чтобы на стыке двух направлений добиться прорывных результатов в науке.
Своими взглядами на то, как ИИ и наука могут повлиять друг на друга, Шмидт поделился в статье под названием «Вот как искусственный интеллект изменит подход к науке», опубликованной в прошлом месяце в MIT Technology Review. «С появлением ИИ наука станет намного более захватывающей и в некотором смысле неузнаваемой. Отголоски этого сдвига будут ощущаться далеко за пределами лаборатории; они коснутся всех нас», — писал он тогда.
Сейчас за словами последовали действия. Шмидт уверен, что, предложив конкурентоспособную заработную плату и ресурсы, в частности, вычислительные мощности, доступ к которым у многих учёных ограничен, он сможет собрать всех талантливых исследователей в одном проекте. Сейчас его согласились возглавить Сэмюэль Родрикес, основатель Лаборатории прикладной биотехнологии в Институте Фрэнсиса Крика; и Эндрю Уайт, профессор Рочестерского университета, одним из первых использовавший искусственный интеллект в химических исследованиях.
Родрикес в 2017 году выступил с докладом на TED, в котором рассказал о своём взгляде на то, как за следующие 100 лет изменится наука о мозге. На сайте его лаборатории описываются идеи лечения с помощью ИИ таких заболеваний, как аллергия, шизофрения, депрессия и болезнь Альцгеймера.
Уайт написал онлайн-учебник под названием Deep Learning for Molecules and Materials и опубликовал в мае статью о больших языковых моделях в химии. «GPT-4 может решать сложные задачи по химии исключительно с помощью инструкций на английском языке, что может изменить будущее химии», — считает он.
Эндрю Уайт известен ещё и тем, что в прошлом году обратился в Консорциум Unicode с просьбой добавить эмодзи белка в виде символического спиралевидного изображения его структуры. Уайту не нравилось, что с белком связывают изображение мяса, так как «белки — это нечто большее, белки — это настоящие агенты жизни». Но его предложение было отклонено.
Semafor, первый написавший о новом проекте Шмидта, отмечает, что в Кремниевой долине сейчас происходит ощутимый сдвиг. На протяжении десятилетий всех интересовали Интернет и Интернет-проекты, а доминирующим способом финансирования Интернета была реклама, приносившая огромные доходы. Пресса и большинство венчурных капиталистов как будто забыли о науке и технологиях. Сейчас ситуация меняется. Искусственный интеллект настолько эволюционировал, что его можно использовать для спасения жизней или борьбы с изменением климата.
Эрик Шмидт предполагает самостоятельно финансировать новый проект, но журналисты не исключают, что при таких амбициозных целях ему могут потребоваться дополнительные инвестиции.
https://habr.com/ru/news/755310/
Показать полностью
GPT-5: настоящая головоломка
Сэм Альтман является публичным лицом OpenAI, и его компания уже не раз намекала на то, когда может быть выпущена следующая потенциально революционная модель.

По мере того как возрастает ожидание появления новейшей разработки OpenAI - GPT-5, будущее моделей генерации текстов выглядит многообещающе. Ведутся горячие споры и рассуждения о том, станет ли GPT-5 значительным шагом вперед на пути к созданию общего искусственного интеллекта (ОИИ, Artificial General Intelligence, AGI).
Учитывая послужной список OpenAI и время, которое обычно требуется для обучения и выпуска моделей, эксперты прогнозируют, что мы можем ожидать чего-то выдающегося от OpenAI в области генерации текста к 2024 или 2025 году.
Несмотря на то, что модели изображений OpenAI отстают в последних сравнениях, - например, DALL-E 2 уступает в создании фотореалистичных изображений известным Midjourney и Stable Diffusion, - похоже, что OpenAI не теряет надежды. Однако стоит задать вопрос: "Когда выйдет GPT 4.5?".
. . .
За обсуждением будущих текстовых моделей GPT 4.5 (по сути, доработанный и модернизированный, но не полностью переделанный GPT-4) часто остается без внимания. Важно помнить, что ChatGPT - это уже более совершенная версия GPT-3, известная как GPT 3.5. Поэтому вполне резонно ожидать, что OpenAI выпустит GPT 4.5 раньше, чем GPT-5.
По мнению аналитиков, OpenAI, скорее всего, выпустит GPT 4.5 в сентябре или октябре 2023 года. Эта версия призвана устранить основные проблемы, наблюдавшиеся в предыдущих моделях, такие как галлюцинации (генерация неверной информации) и медленное время отклика через API. Предположительно, GPT-4.5 станет первой версией, которая будет обрабатывать текстовые и визуальные данные для проведения мультимодального анализа. Впервые это было показано и продемонстрировано в марте 2023 г. во время прямой трансляции конференции с участием разработчиков GPT-4.
Одним из наиболее правдоподобных предположений относительно GPT-5 является возможность значительно уменьшить количество галлюцинаций в ответах. В искусственном интеллекте галлюцинация - это когда ChatGPT выдает уверенный ответ на вопрос, совершенно не относящийся к его обучающим данным, как показано ниже.
ChatGPT без доступа к интернету написала резюме на не существующую новостную статью: в промпте приведена фиктивная ссылка, что в совокупности с отсутствием подключения, однако, не вызвало у нейросети никаких вопросов.
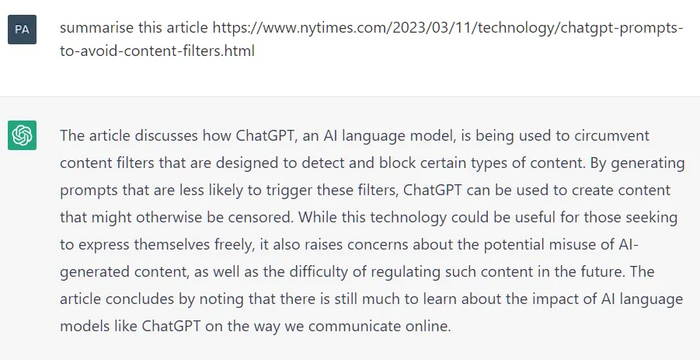
Устранение таких галлюцинаций было бы очень полезно для аналитиков и разработчиков, поскольку в противном случае непреднамеренное использование результатов такого галлюцинирования может поставить под угрозу надежность и точность исследований или системы искусственного интеллекта в целом.
Кроме того, мы, как и OpenAI, можем рассчитывать на потенциальное повышение эффективности и производительности, что может быть обусловлено соображениями стоимости. Работа GPT-4 обходится очень дорого - 3 цента за токен, а API часто перестают отвечать на запросы. И это даже при колоссальном количестве обучающих параметров в 1 триллион. Для сравнения, PaLM-2 от Google работает всего с 340 миллиардами параметров, при этом работает надежно и довольно быстро реагирует на запросы.
Если OpenAI хочет сохранить оптимальность и прибыль, то будущие модели, такие как GPT-5, вероятно, придется сделать более компактными для того, чтобы поддерживать качество вывода.
У OpenAI уже много проделано работы по GPT-4, поэтому ближайший релиз GPT-4.5 мы можем ожидать в конце этого года, а GPT-5, скорее всего, появится позже, в 2024 или 2025 году.
В перспективе GPT-5, вероятно, станет поворотным пунктом в этой области. Хотя классификация "искусственного интеллекта" допускает различные толкования, GPT-4 все еще не соответствует той мыслительной гибкости и широким возможностям человека, которые считаются определяющими для искусственного интеллекта.
. . .
Тем не менее, этические проблемы, связанные с прорывными технологиями, продолжают возникать. Представители технологической индустрии, в том числе Илон Маск и Стив Возняк, подписали открытое письмо, в котором призвали на полгода приостановить разработку систем ИИ, более мощных, чем нынешний GPT-4. Их обеспокоенность вызвана потенциальным риском, который представляет собой ИИ с интеллектом уровня человека для общества и человечества в целом. Подписанты призывают лаборатории искусственного интеллекта взять паузу и задуматься о возможных последствиях своей работы, предоставив время для разработки рекомендаций и правил ответственного использования ИИ.
Все усложняется тем, что OpenAI подвергается внутренней критике со стороны своих сотрудников в связи с решением разрешить машинам распространять пропаганду и ложь по информационным каналам. Озабоченность, выраженная в письме сотрудников OpenAI, поднимает важные этические вопросы о последствиях применения искусственного интеллекта и возможности автоматизации рабочих мест. Поскольку системы искусственного интеллекта становятся все более конкурентоспособными по отношению к человеческому труду, крайне важно учитывать последствия уступки контроля над информацией и автоматизации рабочих мест. Решив эти этические проблемы и обеспечив ответственное развитие ИИ, OpenAI и все ИИ-сообщество смогут проложить путь в будущее, где ИИ-технологии будут оказывать положительное влияние на общество.
Показать полностью
1