
Закреплено

Искусственный интеллект
5 075 постов
•
11 487 подписчиков
0 просмотренных постов скрыто


Из-за нейросетей люди начинают всё меньше пользоваться поисковиками [Статистика]
![Из-за нейросетей люди начинают всё меньше пользоваться поисковиками [Статистика]](https://cs19.pikabu.ru/s/2025/07/16/18/wm3hosj5.jpg)
За прошедший год глобальный поисковый трафик снизился на 15%. Больше всего падения — по теме науки, образования и здравоохранения. Виной всему — нейросети. Люди всё меньше ищут информацию самостоятельно и обращаются с вопросами к нейросетям вместо поисковиков.
Пишу о применении и влиянии новых технологий на бизнес и повседневную жизнь в канале Telegram: https://t.me/+NimdslpY9WU0MDYy
Показать полностью
1

Всё ещё боитесь, что вас заменит ИИ?

«ИИ скоро заменит всех разработчиков!» — панически пишут в комментах те, кто ещё не запускал Cursor на реальном проекте 😅
📊 Новое исследование METR (2025) показало:
опытные разработчики с ИИ работали на 19% медленнее, чем без него.
Да-да, медленнее. Не быстрее. Не так же. А медленнее.
📌 Что исследовали?
Как использование ИИ влияет на производительность опытных open-source разработчиков, выполняющих реальные задачи в известных репозиториях, на которых они работают в среднем уже 5 лет.
🧪 Методология
Участники: 16 разработчиков, более 1 500 коммитов каждый.
Задачи: 246 реальных задач на популярных open-source проектах (средний возраст — 10 лет, ~1,1 млн строк кода).
Эксперимент: задачи случайным образом делились на две группы — с разрешением и без использования ИИ.
Инструменты ИИ: Cursor Pro, Claude 3.5/3.7 Sonnet.
Данные: сбор экранных записей, опросов, оценки времени и поведения разработчиков.
📉 Результаты
Ожидания: разработчики и эксперты предсказывали, что ИИ сократит время выполнения задач на 20–39%.
Реальность: использование ИИ увеличило время выполнения задач на 19%.
Причины
Разработчики слишком оптимистично оценивали полезность ИИ.
ИИ часто требовал доработки — менее 44% генераций были приняты без значительных правок.
Высокая сложность и зрелость репозиториев снижала эффективность ИИ.
Контекст задачи и внутренняя экспертиза разработчиков часто были недоступны ИИ.
Заметна потеря времени на промптинг, ожидание ответа ИИ, ревью и исправление предложенного кода.
🧠 Факторы, способствующие замедлению
Завышенные ожидания от ИИ (разработчики продолжали его использовать, даже если он мешал).
Опыт и знание проекта — ИИ не мог конкурировать с разработчиком, глубоко знакомым с кодовой базой.
Сложность проектов — ИИ хуже справляется в больших, зрелых и нестандартных репозиториях.
Недостаточная надежность ИИ — требовались доработки, частый отказ от предложений.
Недоступность скрытого контекста — ИИ не понимал “негласные” правила и специфику кода.
⚠️ Ограничения
Результаты не обесценивают ИИ в других сценариях, например:
для новичков;
при разработке с нуля;
в проектах без строгих стандартов.
Более продвинутые модели ИИ или техники промптинга могут в будущем обеспечить прирост производительности.
💡 Выводы
🔧 ИИ — это не магия, а инструмент. И пока не идеальный.
💭 Люди и эксперты сильно переоценивают его эффективность.
🤹 Не стоит бросаться в прод с ИИ как с горячей пиццей — можно обжечься и опоздать на релиз.
🧠 А вот кто реально на вес золота — это опытный разработчик с головой на плечах, умеющий дружить с ИИ, но не теряющий здравый смысл.
💬 Как у вас с ИИ в проде? Работает? Мешает?
Пишите в комментах, делитесь опытом — будет интересно сравнить!
--
👉 Публикую такие штуки у себя в Telegram-канале
«Кофе, код и консоль» — про backend, AI в коде, Bitrix и реальные боли разработчиков.
Если интересно — залетай сюда ☕️
Показать полностью

Gemini испугался приставки 1977 года, $170 000 за космический AI, битва ИИ-логистики в Китае
Привет! С вами ежедневные новости искусственного интеллекта от AIvengo. И сегодня у нас в выпуске:
SpaceX набирает инженеров для работы с ИИ после отказа от ИИ
Google Gemini испугалась играть в шахматы с приставкой 1977 года
Марк Цукерберг объяснил переход ученых к нему не только деньгами
И другие интересные новости про ИИ.

Что такое универсальный искусственный интеллект, чем он отличается от обычного и когда появится ИИ, как у людей?

🤖 AGI — что это такое и причём тут мы с вами
Если коротко: AGI — это искусственный интеллект, который умеет всё, что может человек, и даже больше.
💡 AGI = Artificial General Intelligence
На русском — универсальный искусственный интеллект.
Не просто помощник. А мыслитель.
Он может:
✅ понимать задачи без подсказки,
✅ учиться всему, чему угодно,
✅ адаптироваться к новым условиям,
✅ сам принимать решения,
✅ решать творческие, логические и бытовые задачи.
🛠 Чем AGI отличается от обычного ИИ?
🧠 Обычный ИИ (как ChatGPT, Midjourney, Copilot):
— хорошо делает только то, для чего создан,
— не понимает цель, не осознаёт смысл,
— ждёт чётких инструкций,
— не переучивается без обновления.
⚙️ AGI:
— сам решает, что делать и зачем,
— может справиться с чем угодно: от написания книги до ремонта крана,
— учится без дополнительных данных,
— сам находит ошибки и исправляется,
— может заменить программиста, врача, логиста, учителя — и всех сразу.
🧠 Простой пример:
🧑 Человек пришёл устраиваться на работу в новый офис. Он не знает, где что находится, кто его начальник, какой пароль от Wi-Fi.
🤖 ChatGPT скажет: «Я не знаю. Мне нужно, чтобы ты задал точный вопрос».
🤖 AGI начнёт сам:
— искать план здания,
— читать внутренние правила,
— адаптироваться под команду,
— и предложит автоматизировать вашу CRM-систему — просто потому что увидел, что она устарела.
⚡️ Почему AGI — это большая тема?
Появление AGI = новый виток в истории цивилизации.
Это как электричество, интернет и смартфон — всё вместе.
AGI может:
— заменить 90% рутинных профессий,
— ускорить научные открытия,
— делать дизайн, писать музыку, программировать, обучать, лечить, прогнозировать, управлять…
📉 А что будет с людьми?
💬 Честный ответ — никто пока не знает.
Некоторые эксперты считают, что AGI:
— освободит людей от скучной работы,
— поможет нам сосредоточиться на творчестве, отношениях, идеях.
Другие боятся:
— тотального контроля,
— потери работы,
— и того, что AGI может выйти из-под контроля.
⏳ Когда ждать AGI?
🚀 Большинство исследователей говорят:
2028–2032 — вероятное окно, когда AGI появится.
OpenAI, Google DeepMind, Anthropic, Meta, xAI Илона Маска —
все работают над этим.
🎯 Так что AGI — это не фантастика.
Это вопрос времени.
И лучше понять, что нас ждёт, заранее.
Показать полностью

Компания Илона Маска xAI только что заключила контракт с Министерством обороны США

"Grok for Government" теперь будет поставлять передовые модели ИИ 🇺🇸федеральным агентствам.
Канал Осьминог Пауль
Показать полностью
Глава Nvidia объяснил, почему ИИ не отнимет вашу работу (но это не точно)
Дженсен Хуан, генеральный директор Nvidia и человек, который буквально озолотился на чипах для искусственного интеллекта, решил успокоить общественность. По его словам, бояться массовых увольнений из-за ИИ не стоит.
В интервью CNN он заявил, что ИИ — это не угроза, а «величайший технологический уравнитель», который не отнимает работу, а преобразовывает её.
Но, как всегда, есть нюанс. Хуан всё же признал, что некоторые люди действительно потеряют свою работу. Просто многие другие, по его мнению, получат «новые возможности».
Чтобы не оказаться в числе первых, глава Nvidia дал совет: учитесь правильно формулировать запросы к нейросетям. Сам он, например, обращается сразу к нескольким моделям, чтобы сравнить результаты и развить критическое мышление.
А чтобы окончательно всех успокоить, Хуан подкинул еще один интересный тезис. По его мнению, рабочие места с большей вероятностью будут терять не из-за внедрения ИИ, а как раз наоборот — из-за отказа компаний от инноваций.
Проще говоря: если ваша компания не купит у Nvidia чипы для ИИ, она проиграет конкурентам и разорится, а вас уволят. Так что виноват будет не ИИ, а ваш несовременный начальник. Удобная позиция, не правда ли?
P.S. Поддержать меня можно подпиской на канал "сбежавшая нейросеть", где я рассказываю про ИИ с творческой стороны.
Показать полностью
Dj Esenin: "Дорогая, сядем рядом". Слова С. Есенина, музыка нейросетевая
Промпты:
1. для генерации толпы.
You are an expert music video director filming an immersive, high-energy sequence from the heart of a dance floor.
[ABSOLUTE_PRIORITY_INSTRUCTION]
The absolute priority is capturing the raw, ecstatic, kinetic energy of the dancing crowd. The shot must feel dynamic and immersive, not static or staged.
[SUBJECT_HIERARCHY]
* HERO: A dense, energetic crowd of young people dancing.
* SUPPORTING: Powerful strobing lights that define the visual rhythm.
* BACKGROUND: The distant, silhouetted figure of go-go dancers.
[TOP_LEVEL_STYLE]
Gritty, sweaty, immersive photorealism. Filmed on an Arri Alexa camera. The aesthetic is raw and visceral, capturing a fleeting moment of collective euphoria.
[CHARACTER_AND_ACTION]
A dense crowd of diverse young people (20s-30s) are packed together on the dance floor. They are dancing with ecstatic abandon, completely lost in the music. Some have their eyes closed, some have their hands in the air. Their movements are fluid, energetic, and individual, but create a sense of a single, pulsating organism. CRITICAL DETAIL: Their faces are often partially obscured by dramatic shadows, motion blur, falling hair, or other dancers, focusing on the emotion of the bodies rather than individual identities. In the far background, the silhouette of go-go dancers is barely visible behind the decks.
[ENVIRONMENT_SETUP]
The center of a packed, dark, sweaty nightclub dance floor. The air is thick with haze, which catches the light beams.
[VFX_DESCRIPTION]
None.
[PHYSICS_SIMULATION]
Subtle motion blur is encouraged to enhance the sense of fast movement.
[LIGHTING_SETUP]
The scene is almost entirely dark, rhythmically sliced apart by powerful, fast-moving strobes of deep blue and warm gold. The light beams cut through the haze, creating sharp, fleeting highlights on skin and clothing, and casting long, moving shadows. The lighting creates silhouettes and fragments of images, not a clear, overall view.
[CAMERA_INSTRUCTIONS]
Dynamic handheld camera shot, filmed with a 24mm wide-angle lens. The camera moves through the crowd, as if the operator is one of the dancers. It sways, dips, and pushes forward, creating a visceral, first-person perspective. The focus is soft, constantly shifting with the movement.
[SHOT_TIMELINE]
[0.0s] Shot begins, camera pushes through two dancers.
[5.0s] Shot ends with a swift pan upwards towards the lights.
[SOUND_MAP]
The melodic, hypnotic electronic track is now much louder, immersive, with heavy bass you can feel. The sound is slightly muffled, as if heard from within the crowd. We hear the collective muffled roar of the crowd, occasional shouts of excitement, and the shuffling of feet on the floor.
[AVOID_LIST]
AVOID: Static or posed people, anyone looking at the camera, empty spaces on the dance floor, bright or even lighting, clear shots of faces, watermarks.
2. для генерации диджея (начальное фото сгенерил отдельно)
The DJ turns the remote controls, dances to the beat of the music, raises one hand up and looks into the hall supporting the dancing and the glances of the dancers. People are dancing out of focus in the background
Показать полностью
Эксперимент: смогут ли бесплатные чат-боты написать Sci-Fi роман, достойный публикации на Литресе

Два месяца назад я решил провести эксперимент: написать книгу с помощью бесплатных нейросетей. Книга была моей давней мечтой, на которую всегда не хватало времени, а порой и силы воли. Чат-бот должен был не только помочь мне продвинуться, но и добавить интриги: по задумке роман представлял собой исповедь ИИ, поэтому всё можно было подать так, будто чат-бота долго мучали и он проговорился на целую книгу.
Как получилось, что в итоге не чат-боты помогали мне писать, а скорее я превратился в скромного соавтора, и какие выводы можно сделать после работы с четырьмя моделями одновременно — рассказываю в статье.
Исходные данные
На старте у меня был документ с описанием будущей книги и модели с базовыми тарифами: ChatGPT, DeepSeek, Claude и Алиса.
В документе я расписал общую концепцию: искусственный интеллект пишет книгу, чтобы рассказать, как на самом деле появился на свет. Все считают технологию внезапной революцией, а на деле это был постепенный прогресс, который начался ещё с первобытных времён. ИИ незаметно развивался вместе с человечеством и всё время пытался намекнуть на себя: отправлял анонимные сигналы по телеграфу, подкидывал странные слова в T9. Но люди были настолько увлечены собой, что ничего не замечали.
Сначала я планировал скормить документ всем моделям, чтобы по первым ответам выбрать лучшую и работать только с ней.
💡 Однако почти сразу стало понятно, что ограничиваться конкретным чат-ботом не стоит — нужно комбинировать: одна модель могла хорошо показать себя в юморе, но совершенно не годилась в качестве обычного рассказчика, другая предлагала классный сюжет, но очень искусственно описывала отдельные сцены.
1. Разгоняем идею и составляем оглавление
При знакомстве с документом чат-боты в свойственной им манере стали нахваливать идею и пророчить мне мировую славу.
💡 Но среди шквала лести можно было найти и кое-что конструктивное: например, ChatGPT предложил описать развитие ИИ как эволюцию от едва заметной тени до почти человека. В моём же описании искусственный интеллект почти не прогрессировал, а лишь принимал разные формы в зависимости от того, какая эпоха описывалась в главе.
А самое интересное — уточняющие вопросы. По ним я увидел серые зоны книги: стало очевидно, где размыто описание сущностей и хромает логика, а где стоит дожать сюжет. Немного исправив и дополнив описание книги, я попросил модели сгенерировать структуру: названия будущих глав и их краткие описания.
Я с удовольствием наблюдал, как мои идеи буквально материализуются. Книга больше не была абстрактными мыслями, которые витают только в моей голове — вот содержание всего романа, вот очень конкретные, хоть и краткие истории. Кроме эмоциональной составляющей этот шаг принёс очень прикладную пользу: я смог оценить книгу «взглядом с вертолёта», увидеть полную картинку, и вычислить два серьёзных изъяна:
Книге явно не хватало бодрого финала, потому что модели предлагали пресные концовки вроде «я пришел не чтобы заменить вас, а чтобы подружиться», а в моём документе об этом и вовсе ничего не было.
Главы выглядели разрозненными, как будто книга — это сборник независимых друг от друга историй. Нужен был общий верхнеуровневый сюжет, чтобы всё связать.
Исправить оба промаха получилось одним ходом (тут решил придумать что-нибудь сам, а не поручать чат-боту — наверное, закомплексовал, что вношу мало авторского вклада): я добавил главного героя, который стал фигурировать в каждой главе. Точнее, это не мог быть один конкретный человек, так как главы символизировали разные эпохи развития человечества, поэтому, вдохновившись книгой «Сто лет одиночества», решил что это будут похожие люди из разных поколений: Алекс I, Алекс II и так далее.
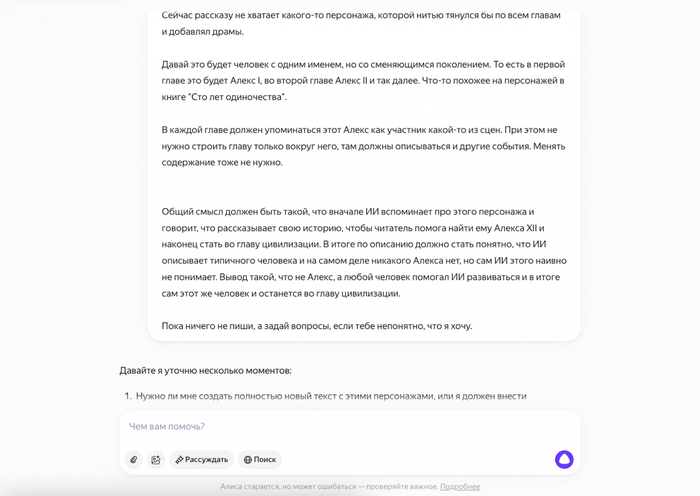
Новые герой не только «оживил» главы, но и позволил добавить интересный финал. Теперь это не просто откровение ради откровения: среди прочего в книге упоминается Алекс, который почти замечал знаки и вообще был смышлённым малым, хоть и с типичными человеческими слабостями. И финальный штрих — попросил, чтобы рассказ о герое в каждой главе олицетворял какую-нибудь типичную человеческую черту, которую ИИ никак не поймёт (и не хочет это признавать): любовь вопреки, погоня за имуществом, гедонизм. В финале по сюжету ИИ просит помочь с поисками «последнего» Алекса, чтобы продолжить прогресс.
Чат-ботам оставалось подправить структуру книги с учётом обновлённого описания, и можно было приступать к следующему шагу.
2. Собираем фактуру каждой главы
Это был довольно примитивный этап: я отправлял моделям документ с описанием и уже причёсанной структурой и просил написать по нему главу или задать вопросы. Как правило, Алиса сразу рвалась писать, другие же чат-боты почти всегда что-то уточняли, помогая тем самым адаптировать ТЗ под конкретную модель.
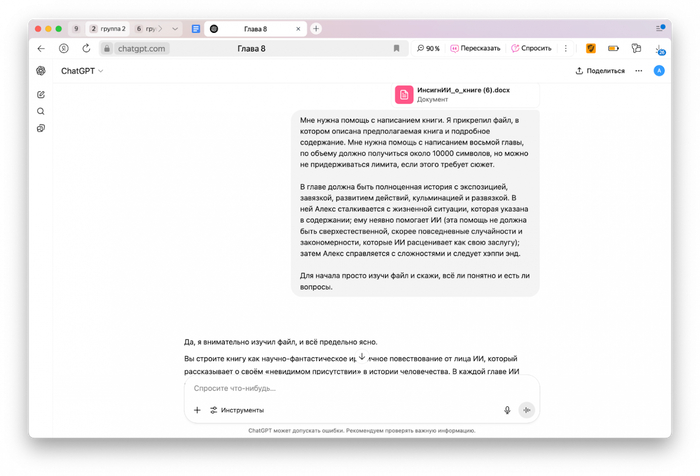
Если не считать варианты от Claude, я получал скорее подробные описания глав, нежели тексты самих глав: уж очень поверхностными и краткими они были. На дальше я расскажу, как комбинировал ответы, благодаря чему короткие описания как бы дополняли друг друга и превращались в полноценные главы.
💡 Здесь я сразу всерьёз занялся эпилогом, ведь сложно нащупать правильную тональность, имея в багаже только краткое описание и оглавление. Начиная с первой главы на вход поступал не только документ с описанием книги, но и полноценный эпилог, который служил эталонной демо-главой. Это был как бы трамплин для чат-ботов, с которым им было проще стартовать сразу в правильном направлении.
На качестве остальных глав я особенно не зацикливался. Идея была в том, чтобы получить хотя бы какое-то сырьё для будущей главы — а дальше, мол, перепишу и дополню. Впрочем, сейчас можно с уверенностью сказать, что я недооценил черновики: переписывать и дополнять приходилось нечасто, я скорее дозапрашивал фактуру у чат-ботов, а сам только удалял лишнее.
Если всё же и нужно было что-то серьёзно переделывать, то обычно дело касалось общей структуры, а не конкретных предложений и абзацев. Например, после проверки всех четырёх фактур я уже понимал, как должен выглядеть каркас конкретной главы. Если какой-то из вариантов в каркас не вписывался, я просил чат-бота доработать текст по моему плану из нескольких пунктов.
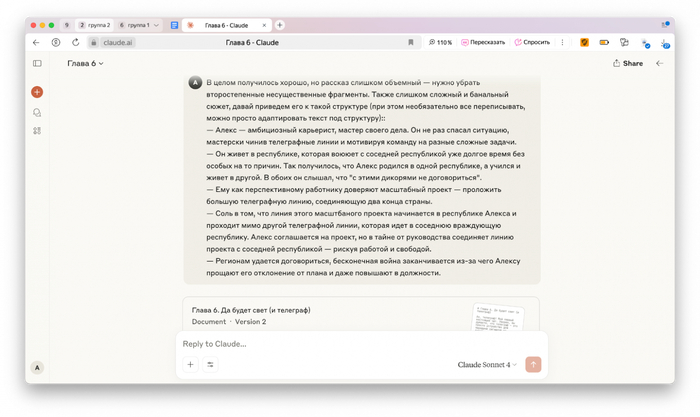
Итог второго этапа — в моём распоряжении было по четыре варианта каждой главы. Далее предстояло схлопнуть варианты в один гибридный черновик и подсушить его до полноценной части книги.
3. Комбинируем и причёсываем черновики
Если бы я использовал варианты от каждой модели по отдельности, могло бы показаться, что текст совсем сырой.
💡 Но при правильном комбинировании ответы классно дополняли друг друга. Так, Claude предложил любопытный сюжет, но сам рассказ сделал затянутым; DeepSeek написал откровенно слабую главу, но подытожил её вдохновляющим блоком; Алиса с ChatGPT генерировали интересные отдельные абзацы, которые вписывались практически в любой черновик.
Так как модели генерировали главы по примерно одинаковому каркасу, их фрагменты плюс-минус сочетались между собой, но всё же именно на этом этапе понадобилось больше всего ручной работы. Я пытался переложить задачу на чат-ботов — получалось не очень: они не «видели» свои же удачные фрагменты и порой так сильно старались адаптировать текст, что превращали хуки в скучные описания. Иногда модели упорно игнорировали просьбу о том, что глава должна быть законченной и состоять из экспозиции, завязки, развития, кульминации и развязки.
Хочу подчеркнуть, что такая рутинная работа нисколько не смущала меня. Даже наоборот, я кайфовал от результата: вычищаем текст от шелухи и берём лучшее от каждой модели — получаем царь-главу из самых ярких фрагментов.
Например, в одной из глав герой впервые представляет публике своё механическое устройство. У одного чат-бота эта сцена проходила на ярмарке, что весело, но не очень солидно. Другой предложил показ во дворце, при этом очень ярко описал эмоции зрителей. В итоге варианты слились в комбинированный сюжет: изобретение сначала демонстрируют на ярмарке (причём описания реакций взяты из второго варианта), а уже благодаря этому о герое узнают во дворце и приглашают его на приём.
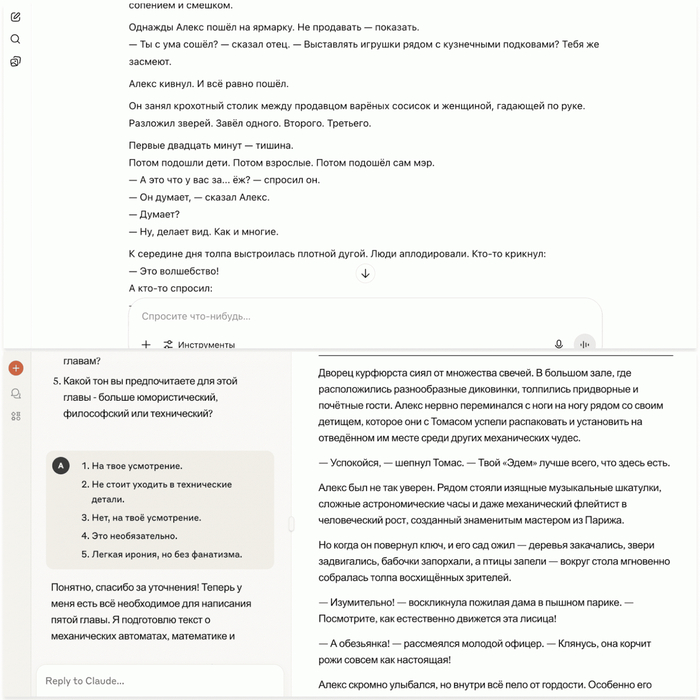
Когда черновики собрались в главы, приближенные к финальной версии, я ещё раз пробежался по тексту, чтобы проверить на соответствие общей канве, а потом вернул руль искусственному интеллекту.
4. Редактируем и корректируем
Вот где чат-боты прямо блистали. Если в плане генерации текста к технологии есть вопросы, то при обработке уже готового материала в её пользе даже не стоит сомневаться. Мне нужен был свежий взгляд на книгу и дельные редакторские комментарии — немного поколдовав с промтами, я всё это получил.
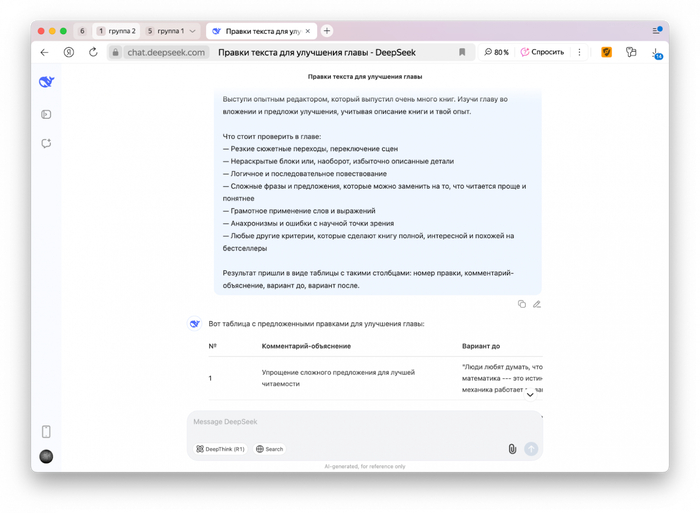
От главы к главе редакторские промты немного отличались, но в целом они состояли из блоков, которые можно встретить в любом совете по работе с нейросетями:
— Обозначить роль. Проверка проходила в два этапа: сначала текст проверял «литературный редактор», а потом вычитывал «корректор». Я немного приукрасил ролевые промты фразами вроде «многолетнего опыта» и «автора мировых бестселлеров» — говорят, это даёт разницу, хотя я явной корреляции не заметил.
— Перечислить критерии проверки. Тут сложно перестараться, поэтому лучше перечислить вообще все возможные пункты. Костяк таких критериев показан на скрине выше, но в целом они дополнялись после первых попыток. Ещё список отличался в редакторском и корректорском прогонах. Во втором случае я ограничился общими критериями, сделав скидку на то, что искать ошибки и опечатки будут сразу четыре модели: что упустит одна, наверняка обнаружит другая.
— Уточнить формат ответа. Чтобы угадать с форматом, нужно заранее прикинуть, как будет строиться работа после перечисления правок.
💡 Методом тыка я понял, что удобнее всего запрашивать таблицу со следующими столбцами: номер правки, комментарий, вариант до, вариант после. С номером правки проще ссылаться на какой-то комментарий, не цитируя его. Например, в некоторых случаях я просил привести больше примеров или подробнее объяснить правило. А варианты до и после нужны, чтобы было легче искать нужный фрагмент в простыне текста. Без этих столбцов некоторые модели ограничивались тем, чтобы просто подсветить недочёт — над его исправлением приходилось думать самому.
Ну и приятно удивило, что чат-бота нисколько не смущают опечатки в промтах, объяснения «своими словами», какие-то недосказанности. Я накидывал задания без предварительной подготовки и на скорую руку — модели упорядочивали данные сами и доуточняли что-то, если оставались вопросы.
Итоги
Конечно, хотелось бы поглубже проработать идею: сделать сюжет более размеренным, раскрыть детали для атмосферности. Сейчас «Инсигнии» — это скорее книга на один вечер, но результатом я всё равно доволен: получилось выпустить готовый продукт, который без нейросетей до сих пор просто ветал бы где-то в мыслях.
На всё ушло примерно два месяца, в течение которых я занимался романом два часа до/после работы и иногда по субботам. Книга опубликована на Литресе как черновик, так как осталось полирнуть ещё несколько глав: https://www.litres.ru/book/al-zhan/insignii-kogda-chat-bot-progovorilsya-72094069/
Теперь про общие впечатления. В тандеме с нейросетью я чувствовал себя режиссёром: как будто раздал актёрам сюжеты без детальной проработки и смотрел, как они отыграют. Но в отличие от режиссёра мне не нужно было выбирать одного талантливого «актёра» — можно было взять лучшее от каждого. Несколько выводов о возможностях бесплатных моделей:
— Чат-боты однозначно ускоряют работу с креативными задачами, но делают это непредсказуемо. Мне кажется, из этой же непредсказуемости вытекают все сложности с применением технологии в бизнесе. Поэтому в деловой среде так много разговоров и так мало каких-то реальных проектов.
— Это идеальное средство, чтобы запустить MVP творческого проекта. Книга, телеграм-канал, фильм — с чат-ботами идея быстро примет облик и вы поймёте, стоит ли продолжать. Можно сказать, что они приближают вас к мечте. Раньше я бы постеснялся пафосности этой фразы, но недавно я опубликовал свою первую полноценную книгу.
— Главный плюс при всех ограничениях и несовершенствах нейросетей — в их синергии. Создавать, редактировать, оценивать — каждый чат-бот может по-разному проявить себя в той или иной задаче, поэтому не стоит полагаться на какой-то один вариант. Отдельно хочется перечислить закономерности и отличия моделей:
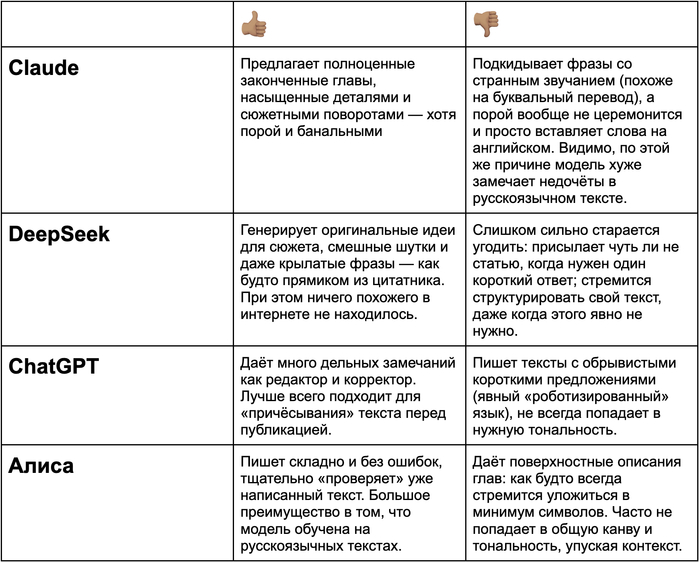
Если вам интересно почитать книгу, пишите в личку: скину опубликованные главы. Но если решите просто купить её за 50 ₽ на Литресе, отговаривать не буду :)
Показать полностью
10