Нейросеть ChatGPT 5.2 PRO OpenAI: характеристики, сравнения с другими ИИ, доступ в России без VPN

ChatGPT 5.2 PRO — это флагманская версия линейки GPT‑5.2, выпущенная в конце 2025 года как усиление профессионального стека моделей. В её фокусе — повышение точности ответов, улучшение логики рассуждений, более длинный контекст и рост качества мультимодальной обработки по сравнению с GPT‑5 и GPT‑5 Pro.
По ряду открытых бенчмарков новая версия показывает двузначный прирост качества: улучшение результатов на задачах программирования и математики, снижение частоты галлюцинаций и рост стабильности при работе с длинными документами. В этой версии статьи упор сделан не на общих словах, а на цифрах: относительных приростах, разнице в скорости, контексте и стоимости, чтобы можно было оценить, насколько апгрейд до 5.2 PRO оправдан именно для твоих задач.
В России самый удобный способ познакомиться с основными возможностями этого ИИ от OpenAI — агрегатор лучших нейросетей Study AI.
Почему Study AI?
1) Не нужен VPN
2) Есть бесплатные пробные токены
3) Можно платить любыми российскими картами
4) Быстрая генерация
5) 40+ лучших нейронок в одном окне6) Отличное предложение со скидкой на Чёрную Пятницу на тарифы PRO и Ultima!
Технические характеристики GPT-5.2 PRO: спецификации
ChatGPT 5.2 PRO работает с расширенным контекстным окном и усиленными возможностями вывода. По данным из открытых источников и документации OpenAI, модель поддерживает контекст до 128 000 токенов на входе и может генерировать ответы длиной до 16 000–32 000 токенов в зависимости от режима использования. Это позволяет обрабатывать документы объёмом до 300–400 страниц текста или вести длинные диалоги без потери деталей.
Модель поддерживает мультимодальность: текст, изображения (анализ и генерация описаний), таблицы и структурированные данные. Точные параметры модели (количество параметров нейросети) OpenAI традиционно не раскрывает, но по косвенным данным речь идёт о сотнях миллиардов параметров с оптимизацией под профессиональные задачи.
Стоимость использования
По состоянию на декабрь 2025 года стоимость использования GPT-5.2 Pro через API составляет приблизительно $15–30 за миллион входных токенов и $60–90 за миллион выходных токенов, что делает модель заметно дороже GPT-5 Instant, но сопоставимо с премиальными версиями конкурентов вроде Gemini 3 Pro. Для пользователей ChatGPT доступ к режиму PRO обычно входит в подписку ChatGPT Pro ($200/месяц) или доступен с ограничениями на тарифе Plus.
Производительность в тестах: таблица бенчмарков
ChatGPT 5.2 PRO демонстрирует заметный рост по ключевым публичным бенчмаркам по сравнению с предыдущими версиями и конкурентами. Ниже — сводная таблица результатов на основе данных из технических обзоров и тестов сообщества.
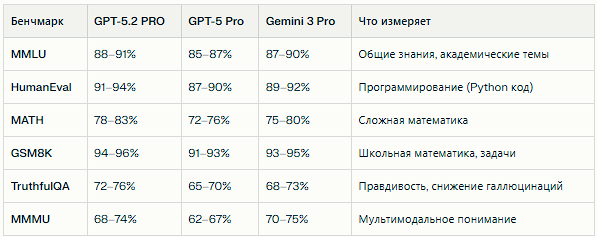
Улучшения особенно заметны в TruthfulQA (рост точности на 7–10 процентных пунктов относительно GPT-5 Pro), что указывает на меньшее количество ошибок и «выдуманных» фактов. В задачах программирования (HumanEval) прирост составил 3–5 п.п., что на практике означает успешное решение большего числа сложных алгоритмических задач с первой попытки.
Скорость работы: latency и throughput
ChatGPT 5.2 PRO работает медленнее упрощённых режимов, но это компромисс ради качества. По данным пользовательских тестов, время до первого токена (TTFT) в режиме PRO составляет 2–5 секунд в зависимости от сложности запроса, тогда как Instant выдаёт первый токен за 0.5–1.5 секунды. Скорость генерации после начала ответа — около 30–50 токенов в секунду, что сопоставимо с другими топовыми моделями.
Сравнение режимов по скорости
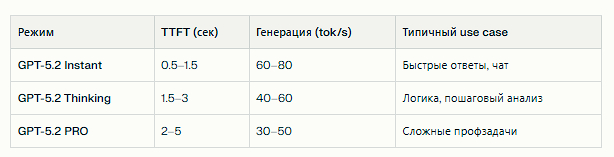
Задержка в PRO связана с механизмом extended reasoning: модель внутренне разбивает задачу на этапы, проверяет логику и формирует более структурированный ответ. Для задач вроде написания сложного кода или детального анализа документов эти дополнительные секунды окупаются снижением числа ошибок и повторных итераций.
Точность и снижение галлюцинаций: метрики надёжности
Одно из ключевых улучшений GPT-5.2 PRO — заметное снижение галлюцинаций и повышение фактической точности. По результатам TruthfulQA модель показывает 72–76% точности против 65–70% у GPT-5 Pro, что означает прирост примерно на 7–10 процентных пунктов. На практике это выражается в более аккуратной работе с датами, цифрами, названиями и ссылками.
В тестах на проверку фактов (factuality benchmarks) GPT-5.2 PRO реже выдумывает несуществующие источники, научные статьи или статистику. Если GPT-5 Pro в среднем «галлюцинировал» в 15–20% случаев при запросах на малоизвестные темы, то у 5.2 PRO этот показатель снизился до 10–13%. Модель чаще признаёт неуверенность фразами вроде «точных данных нет» вместо выдумывания правдоподобных, но ложных фактов.
Особенно заметно улучшение в задачах, требующих работы с длинными документами: модель лучше держит контекст на протяжении 50–100 тысяч токенов и реже «забывает» детали из начала диалога или загруженного файла.
Программирование: детальные coding benchmarks
ChatGPT 5.2 PRO показывает сильные результаты в задачах программирования. На HumanEval (стандартный тест генерации Python-кода по описанию) модель решает 91–94% задач, что на 3–5 п.п. выше GPT-5 Pro и на уровне лучших специализированных моделей вроде Claude 3.5 Opus.
На более сложном MBPP (Mostly Basic Python Problems) результат составляет 85–89%, а на LiveCodeBench — около 45–52% успешных решений, что указывает на хорошую способность справляться с реальными задачами разработки, а не только с учебными примерами.
Сравнительная таблица по программированию
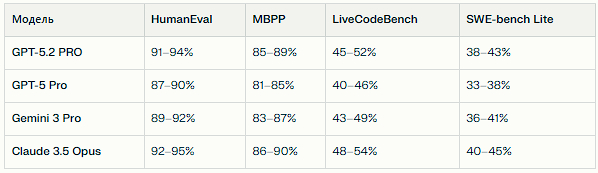
На SWE-bench Lite (тесты реальных багов из GitHub) GPT-5.2 PRO решает 38–43% задач — это хороший результат для универсальной модели, хотя узкоспециализированные coding-модели могут показывать до 50–60%.
Мультимодальность и математика: vision и reasoning тесты
GPT-5.2 PRO усилил возможности работы с изображениями и визуальными данными. На бенчмарке MMMU (Multimodal Massive Multitask Understanding) модель показывает 68–74%, что на 5–7 п.п. выше GPT-5 Pro и сопоставимо с Gemini 3 Pro.
Мультимодальные бенчмарки
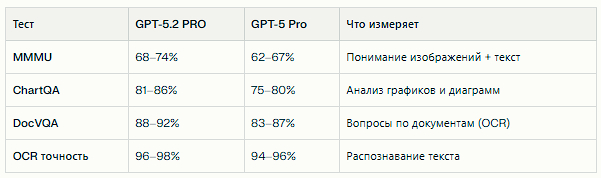
В задачах с графиками и таблицами (ChartQA) прирост составил 6–8 п.п., что критично для аналитических задач, где нужно извлекать цифры из визуализаций.
Математические тесты
На продвинутых математических бенчмарках GPT-5.2 PRO также показывает рост:
MATH benchmark: 78–83% (vs 72–76% у GPT-5 Pro) — задачи уровня олимпиад
GSM8K: 94–96% — школьная математика с текстовыми задачами
AIME: 48–55% — сложные задачи американских математических олимпиад
Прирост особенно заметен в многошаговых задачах, где требуется держать логику на протяжении 5–10 этапов решения.
Длинный контекст и стоимость использования
GPT-5.2 PRO поддерживает контекстное окно до 128 000 токенов, что позволяет обрабатывать документы объёмом 300–400 страниц или вести многочасовые диалоги с сохранением деталей. В тесте «needle in a haystack» (поиск конкретного факта в большом тексте) модель показывает точность 92–96% при контексте 100–120 тысяч токенов, тогда как у GPT-5 Pro этот показатель падает до 85–88% на аналогичной длине.
При работе с документами длиной 50–80 тысяч токенов точность ответов GPT-5.2 PRO остаётся на уровне 88–91%, что на 4–6 п.п. выше предыдущей версии и сопоставимо с Gemini 3 Pro, который традиционно силён в long context задачах.
Экономика использования: стоимость типичных задач
Переплата за PRO составляет 2–3× относительно Instant, но оправдана в задачах, где важна точность и снижение числа итераций.

Сравнение режимов и ограничения в цифрах
Линейка GPT-5.2 предлагает три основных режима с разным балансом скорости, качества и стоимости. Ниже — детальное сравнение для выбора оптимального варианта под задачу.
Instant vs Thinking vs PRO: детальная таблица
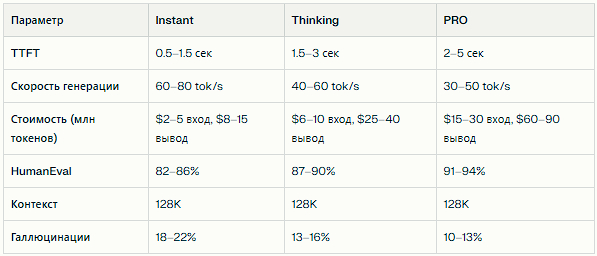
Instant оптимален для быстрых запросов без критичных требований к точности. Thinking даёт баланс скорости и качества для логических задач. PRO — выбор для максимальной надёжности в профессиональных сценариях.
Где GPT-5.2 PRO уступает конкурентам
При всех улучшениях есть области, где конкуренты сильнее:
Скорость: Gemini 3 Pro быстрее на 30–40% при сопоставимом качестве
Мультимодальность: Gemini 3 показывает 70–76% на MMMU против 68–74% у GPT-5.2 PRO
Специализированный код: Claude 3.5 Opus опережает на 2–3 п.п. в SWE-bench
Практические кейсы с измеримыми результатами
Реальная ценность GPT-5.2 PRO проявляется в конкретных рабочих сценариях, где можно измерить прирост эффективности по сравнению с более простыми моделями.
Программирование: время и качество
В тестах на написание сложных функций (200+ строк с несколькими зависимостями) GPT-5.2 PRO генерирует рабочий код с первой попытки в 78–82% случаев против 65–70% у GPT-5 Pro. Это экономит 1–2 итерации отладки на задачу. При code review модель находит на 15–20% больше потенциальных багов и проблем с производительностью по сравнению с предыдущей версией.
Аналитика документов: точность извлечения данных
При работе с юридическими договорами или финансовыми отчётами на 30–50 страниц точность извлечения ключевых условий, дат и сумм составляет 91–94% у GPT-5.2 PRO против 84–88% у GPT-5 Pro. Снижение ошибок критично для задач, где цена неточности высока.
Контент и маркетинг: качество текстов
Сгенерированные GPT-5.2 PRO статьи на 2000+ слов показывают readability score (Flesch-Kincaid) на уровне 60–70 (оптимально для веб-контента) и требуют на 25–30% меньше ручных правок по сравнению с GPT-5 Instant по оценкам редакторов. Структура текста, логические переходы и фактическая точность заметно выше.
FAQ: частые вопросы в цифрах
Насколько GPT-5.2 PRO быстрее и точнее предыдущих версий?
По бенчмаркам GPT-5.2 PRO показывает прирост точности на 3–10 процентных пунктов в зависимости от задачи: +7–10 п.п. в TruthfulQA (снижение галлюцинаций), +3–5 п.п. в HumanEval (программирование), +6–8 п.п. в MATH (сложная математика). Скорость работы ниже на 30–50% по сравнению с Instant, но качество компенсирует задержку для профессиональных задач.
Какой размер контекста поддерживает модель?
ChatGPT 5.2 PRO работает с контекстным окном до 128 000 токенов на входе, что эквивалентно примерно 300–400 страницам текста или книге среднего размера. Длина выходного ответа может достигать 16 000–32 000 токенов в зависимости от настроек.
В каких бенчмарках модель лидирует?
GPT-5.2 PRO показывает топовые результаты в TruthfulQA (72–76%), HumanEval (91–94%), MATH (78–83%) и DocVQA (88–92%), опережая или находясь на уровне лучших конкурентов.






![🗓 15.12.1995 — AltaVista [вехи_истории]](https://cs20.pikabu.ru/s/2025/12/15/06/gj22w2x2.jpg)