

Потенциал экселя изучен только на 1%
В этот раз эксперты показали, как создать елочку в таблице.
Самое время наряжать сметы, коллеги!
В этот раз эксперты показали, как создать елочку в таблице.
Самое время наряжать сметы, коллеги!
Экспорт данных из базы данных в Excel — это общая задача для разработчиков, которым необходимо анализировать или составлять отчеты о данных. В этой статье мы продемонстрируем, как использовать Free Spire.XLS для Python, библиотеку, которая позволяет создавать и манипулировать файлами Excel без необходимости установки Microsoft Excel. Мы рассмотрим настройку вашей среды, подключение к базе данных MySQL и экспорт данных в файл Excel.
Spire.XLS для Python — это мощная библиотека, позволяющая разработчикам создавать, читать и манипулировать файлами Excel в различных форматах без необходимости установки Microsoft Excel. Библиотека поддерживает операции, такие как чтение и запись данных ячеек, форматирование и создание диаграмм.
Перед тем как погрузиться в код, необходимо правильно настроить вашу среду разработки. Вот шаги, чтобы начать:
1. Установите Python: Убедитесь, что Python установлен на вашем компьютере. Вы можете скачать его с официального сайта Python.
2. Установите необходимые библиотеки: Вам нужно установить библиотеку Spire.XLS и соединитель MySQL. Используйте следующие команды в терминале или командной строке:
pip install spire.xls.free
pip install mysql-connector-python
3. Настройте MySQL: Если вы еще не сделали этого, установите MySQL на вашем компьютере. Вы можете скачать его с официального сайта MySQL. После установки создайте базу данных для работы. Вы можете сделать это с помощью клиента MySQL, такого как MySQL Workbench, или через командную строку:
CREATEDATABASE excel_db;
Теперь, когда ваша среда настроена, мы можем перейти к подключению к базе данных MySQL.
Чтобы взаимодействовать с базой данных MySQL, вам необходимо установить соединение. Следующий код показывает, как это сделать:
import mysql.connector
# Установите соединение с базой данных MySQL
connection = mysql.connector.connect(
host="localhost",
user="your_username", # Замените на ваше имя пользователя MySQL
password="your_password", # Замените на ваш пароль MySQL
database="your_database"# Замените на имя вашей базы данных
)
cursor = connection.cursor()
Шаг 1. Извлечение данных из базы данных
Чтобы экспортировать данные из MySQL в Excel, вам сначала нужно извлечь их. Вот как получить имена столбцов и данные конкретной таблицы в вашей базе данных:
# Получите имена столбцов
cursor.execute("SHOW COLUMNS FROM table_name")
column_names = [column[0] for column in cursor.fetchall()]
# Получите данные
cursor.execute("SELECT * FROM table_name")
data = cursor.fetchall()
Шаг 2. Запись данных в Excel
Далее вы запишите извлеченные данные в файл Excel с помощью Spire.XLS. Вот как это сделать:
from spire.xls import *
from spire.xls.common import *
# Создайте объект курсора
cursor = connection.cursor()
# Создайте объект Workbook
workbook = Workbook()
# Удалите стандартные таблицы
workbook.Worksheets.Clear()
# Добавьте таблицу и назовите ее
worksheet = workbook.Worksheets.Add("FromDatabase")
# Запишите имена столбцов в таблицу Excel
for col_index, column_name inenumerate(column_names, start=1):
worksheet.SetValue(1, col_index, column_name)
# Запишите данные в таблицу Excel
for row_index, row inenumerate(data, start=2):
for col_index, value inenumerate(row, start=1):
worksheet.SetValue(row_index, col_index, str(value))
# Сохраните рабочую книгу в файл Excel
workbook.SaveToFile("output.xlsx")
Шаг 3. Настройка вывода в Excel
Вы можете дополнительно настроить вывод в Excel, применяя стили, форматирование или добавляя диаграммы, улучшая визуальную привлекательность вашего файла Excel. Например, вы можете сделать заголовок жирным, настроить ширину столбцов и высоту строк:
# Сделайте заголовок жирным
worksheet.Rows[0].Style.Font.IsBold = True
# Установите ширину столбцов и высоту строк
worksheet.AllocatedRange.ColumnWidth = 10
worksheet.AllocatedRange.RowHeight = 15
Полный код для экспорта данных из базы данных в Excel с помощью Python выглядит следующим образом:
from spire.xls import *
from spire.xls.common import *
import mysql.connector
# Установите соединение с базой данных MySQL
connection = mysql.connector.connect(
host="localhost",
user="root",
password="admin",
database="excel_db"
)
# Создайте объект курсора
cursor = connection.cursor()
# Получите имена столбцов
cursor.execute("SHOW COLUMNS FROM office_cost")
column_names = [column[0] for column in cursor.fetchall()]
# Получите данные
cursor.execute("SELECT * FROM office_cost")
data = cursor.fetchall()
# Создайте объект Workbook
workbook = Workbook()
# Удалите стандартные таблицы
workbook.Worksheets.Clear()
# Добавьте таблицу и назовите ее
worksheet = workbook.Worksheets.Add("FromDatabase")
# Запишите имена столбцов в таблицу Excel
for col_index, column_name inenumerate(column_names, start=1):
worksheet.SetValue(1, col_index, column_name)
# Запишите данные в таблицу Excel
for row_index, row inenumerate(data, start=2):
for col_index, value inenumerate(row, start=1):
worksheet.SetValue(row_index, col_index, str(value))
# Установите ширину столбцов и высоту строк
worksheet.AllocatedRange.ColumnWidth = 10
worksheet.SetColumnWidth(2, 15)
worksheet.AllocatedRange.RowHeight = 15
# Установите выравнивание
worksheet.AllocatedRange.HorizontalAlignment = HorizontalAlignType.Left
# Установите стиль шрифта
worksheet.Rows[0].Style.Font.IsBold = True
# Сохраните рабочую книгу в файл Excel
workbook.SaveToFile("output/DatabaseToExcel.xlsx")
# Закройте курсор и соединение с базой данных
cursor.close()
connection.close()

В этой статье мы прошли процесс экспорта данных из базы данных MySQL в файл Excel с помощью Spire.XLS для Python. Мы начали с настройки среды, включая установку Python, необходимых библиотек и MySQL. Затем мы рассмотрели подключение к базе данных, извлечение данных и запись их в рабочую книгу Excel. Наконец, мы обсудили настройку вывода для улучшения читаемости. Следуя этим шагам, вы можете упростить процесс экспорта данных с помощью Python.
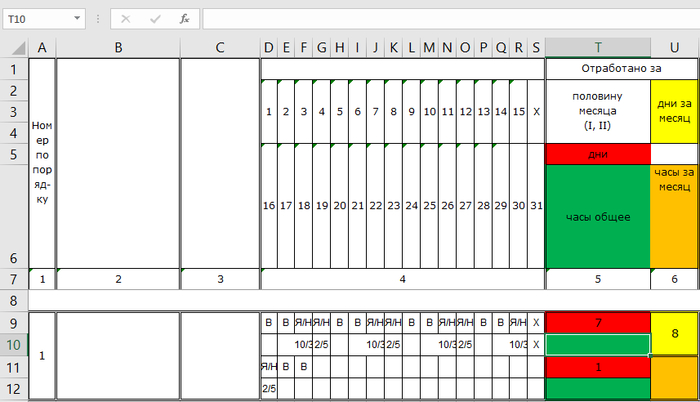
Подскажите какую формулу использовать, чтобы посчитало все целые числа на одной строке в ячейку T10. Т.е. чтобы считало 10/3 и 2/5 как = 10 + 3 + 2 + 5 = 20.
Ранее читал пост, но так и не помогло ничего Суммирование чисел, написанных через дробь
Тайные знания гильдий, секреты успешных сделок и дух старины — в нашем новом квесте.
Почему одно объединение "умное", но медленное, другое - "тупое", но честное?
Обсудим сегодня эту тему.
А пока подписывайся на мой канал На связи: SQL Там я публикую посты про особенности и нюансы SQL. Этот канал про то, как не бояться баз данных, понимать, что такое JOIN, GROUP BY и почему NULL ≠ 0. Его я веду с нуля подписчиков. Присоединяйся!
UNION и UNION ALL.
На вид - почти одно и то же.
По смыслу - разные вещи.
И вот почему
UNION ALL — «тащит всё как есть»
UNION ALL просто берёт результаты двух запросов и клеит их друг под другом:
SELECT name FROM customers
UNION ALL
SELECT name FROM partners;
Никаких проверок, дубликатов, умностей.
- Если в обоих списках есть «Иван», то итоговый результат будет два «Ивана».
- Если порядок в исходных таблицах хаотичный, в результате он будет ещё хаотичнее.
UNION ALL = быстро + честно + без фильтров.
UNION делает то же самое, но перед тем как вернуть результат, он удаляет дубликаты:
SELECT name FROM customers
UNION
SELECT name FROM partners;
Чтобы убрать дубли, PostgreSQL/Oracle/MySQL вынуждены:
отсортировать результат
или построить hash-сет
и только потом вернуть данные
Это дорого.
На миллионах строк может стать тормозом №1 в отчёте.
UNION = красиво, чисто, но медленно.
Например, получить список всех пользователей, независимо от источника:
SELECT user_id FROM old_system
UNION
SELECT user_id FROM new_system;
Например, когда запросы пересекаются, а ты не хочешь вручную писать DISTINCT.
Практически везде, там где не надо удалять дубликаты, т.к. их по определению нет.
Например объединение отчетных данных за разные периоды.
SELECT * FROM sales_2024
UNION ALL
SELECT * FROM sales_2025;
Ни в UNION, ни в UNION ALL.
Если хочешь порядок — дописывай: ORDER BY
UNION ALL — как корзина: «скидываем всё подряд».
UNION — как фильтр: «скидываем всё, но потом отбираем уникальное».
Мой канал На связи: SQL ждет тебя, если ты тоже хочешь познакомиться с базовым языком для аналитики данных. Подписывайся!
Недавно приходит клиент. Запрос стандартный — улучшить результаты в контексте. Спрашиваю, как сейчас считаете.
— Да у нас всё в порядке, всё посчитано. Вот файл.
И присылает… один-единственный Excel.
120 мегабайт. 27 листов. Название файла: Отчет_сводный_финал_НОРМАЛЬНЫЙ_точно_этот(2).xlsx.
Открываю. Компьютер задумывается на минуту, загружается ад перфекциониста:
Лист НОВАЯ_СВОДНАЯ_ИТОГ
Лист НОВАЯ_СВОДНАЯ_ИТОГ_Новая
Лист Копия_старый_не трогать
Лист ЛЕНЕ НЕ ЛЕЗТЬ
В одной из таблиц нахожу колонку с названием итог_новый_итог2(ok). Как потом узнал, именно из неё генеральный берет цифру для презентации акционерам. Спрашиваю:
— Откуда цифры-то в файле появляются?
— Ну как… Маркетолог по понедельникам выгружает из Яндекс.Директа в csv, девочка из колл-центра – из телефонии, менеджер – из CRM, а Лена всё это сводит.
Лена сидит напротив. Кивает. Мол, да, я тут работаю главным интегратором данных. Человек-ETL.
Оказывается, процесс выглядит так:
Каждый месяц создаётся новая вкладка: Октябрь_НОВЫЙ, Октябрь_НОВЫЙ(2), Октябрь_правки_ИРА.
Формулы протягивают вручную: «тут просто тяни вниз до конца, а потом ещё чуть-чуть».
Если формула слетает (а она слетает), все идут к Лене. Только она знает, какая из трёх цифр «Прибыль» настоящая.
Решил сверить показания. Беру октябрь:
В листе Свод по каналам – 187 лидов.
В листе Отчет для директора за тот же период — уже 163.
В CRM, куда мне дали доступ, – вообще 191.
— И где правда? — спрашиваю.
Повисла пауза. Директор смотрит на Лену. Лена вздыхает и открывает ещё один лист (скрытый!): ПРОВЕРЕНО_ЛЕНА.
— Вот эта, – говорит. – Эти 163 мы руками перепроверяли, там в CRM дубли были, а в своде по каналам тестовые заявки не убрали.
Картина маслом: бизнес с миллионными оборотами держится на одном экселе и честном слове Лены.
Я предложил простой мысленный эксперимент:
— Представьте, Лена завтра ушла в отпуск. В горы. Без связи. Кто сможет объяснить директору и финансам, почему в отчёте 163 лида, а не 187? И почему колонка называется новый_новый_ИТОГ? И самое главное, как на основании цифр принимать решения?
Повисло молчание.
В итоге мы сели и начали разматывать этот клубок. Нашли, где теряются заявки при экспорте, где менеджеры забывают менять статусы, а где данные просто правят руками «потому что так красивее».
Вообще, Excel – нормальный инструмент. Но когда на нём “завязана” вся аналитика – это уже лотерея “сработает-не сработает”.
Что сделали:
Настроили прямую выгрузку из кабинетов, CRM и телефонии. Без ручного копипаста и csv-файлов.
Свели всё в единое хранилище (базу данных).
Разделили доступы: маркетингу – свои дашборды, продажам – свои, директору – только ключевые цифры.
Excel оставили, куда же без него, но для локальных задач.
Через пару недель директор пишет:
«Слушай, впервые вижу, что цифры в отчёте маркетинга, в CRM и в финансах совпадают. И Лену дёргать не надо».
Лена, кстати, никуда не делась. Просто перестала работать «костылём» для системы и занялась нормальной аналитикой, а не копированием ячеек.
Проблема не в том, что вы ведете аналитику в Excel. Проблема, когда вся логика вашего бизнеса, все связи и формулы живут в одном файле и в голове одного сотрудника.
В жизни каждой сильной и независимой женщины наступает момент, когда она решает вступить в ряды Адепта Соритас полностью погрузиться в лор Вахи. А то я каждый раз застреваю на полпути при изучении столь обширного лора.
Вопрос к заядлым фанам Вахи. Какие-нибудь новые важные глобальные события/изменения произошли в лоре Вахи? Что-нибудь капитально изменилось, кроме женщин-Кустодес (до сих пор считаю это ересью)? Император всё ещё на троне сидит? Кадия стоит? Почему все шутят про Жиллимана и Эксель?
Сейчас декабрь, все закрывают квартал/год, делают бюджет на следующий год, но а я в поиске работы. Нет, начала поиск я не в декабре, а в октябре. Из результатов за 2 месяца - один оффер, но я отказалась от него. Не из-за содержания работы, а из-за процесса оформления - он вызвал сомнения.

И пока я продолжала поиск, я начала анализировать, что вообще происходит вокруг. Почему раньше всё работало одним способом, а теперь - совсем иначе.
Сейчас из каждого утюга слышу, что работу найти сложно, что на поиск работы надо закладывать 6 месяцев и т.д. и т.п. Ну ОК, подумала я, и вот в октябре начала искать, отрыла резюме на hh.ru для всех желающих, стала повторять теорию, нарешивать задачки и т.д.
Просматриваю вакансии, отбираю в избранное, потом анализирую, что и как там может быть. И наблюдаю за своим резюме. В итоге:
- просмотров резюме - кот наплакал,
- на отклики, релевантные моему опыту - отказы
- предложения только с релокацией в другую страну
Смотрю я статистику своего резюме: последний раз искала работу через HH в 2021 году, просмотров резюме по 10 в день. А сейчас дай бог 3 в неделю.
Резюме у меня одно, я его обновляю и дополняю по мере изменения моего опыта.
Читаю информацию про текущее положение на рынке, везде слышу, что рынок работодателя, что вакансий мало, резюме много. А дальше, очень часто натыкаюсь на то, что все разом говорят - надо делать резюме под конкретную вакансию
Причиной всего этого - автоматизация процессов. Первый скрининг резюме проводит не HR, а AI-агент, настроенный под конкретные триггерные слова.
Раньше мы писали резюме для людей.
Теперь - сначала для алгоритмов
Эпоха универсальных резюме закончилась.
Не потому, что специалисты стали хуже.
А потому что требования стали более структурированными, а инструменты поиска - более автоматизированными.
И теперь у меня вместо одного резюме - 4 резюме, с нотками особенностей под конкретные направления.
Опыт один и тот же.
Но фокус - разный.
И именно фокус видят алгоритмы.
И вот в этой статистике, которую вещает HH.ru - ссылка на презентацию здесь
Говорится о динамики среднего числа вакансий и резюме
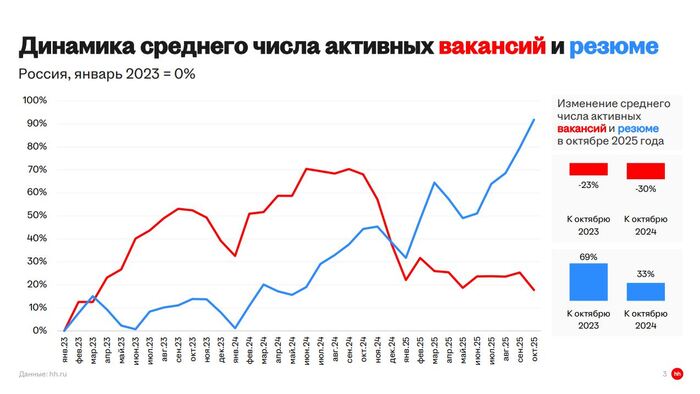
Сопоставление вакансий идет к количеству резюме - не к количеству кандидатов.
Если даже возьмем меня, то у меня 4 резюме (планируется еще одно), т.е. количество резюме (в моем случае надо разделить на 4). А если это применить ко всем резюме, то может быть и картина то изменится. И не будем мы использовать слово рынок работодателя - а может быть другой рынок. Например рынок AI-ассистентов
Со стороны соискателей, тоже идет автоматизация. Соискатели в ручную откликаются на 100 вакансий из идеи - а что-то да и сработает. Либо также настраивают автоотклик, автообновление. Все это приводит к тому, что на одну вакансию HR-ы получают 400-3000 откликов, что руками нереально разобрать.
Поэтому компании:
- ставят автоскоринг
- ранжируют по ключевым словам
- убирают резюме, которые хоть чуть-чуть не совпадают
- сортируют по «свежести обновления»
И это не плохо и не хорошо — это новая норма.
Но к ней нужно адаптироваться.
Искать работу в конце 2025 года — это уже не про то, чтобы быть «идеальным кандидатом».
Это про то, чтобы быть заметным в мире, где первые фильтры проходят не люди, а алгоритмы.
Ну а я в своем канале про SQL буду продолжать делиться полезной информацией, интересными задачками и продолжать вдохновлять людей для изучения аналитики.
Если тебе интересно, подписывайся На связи: SQLЭтот канал я веду с нуля.
Приветствую всех.
Есть таблица, в которой забиты числа.
В каждой строке, есть, в конце, ячейка, куда формула считает сумму всех чисел в строке.
Надо: в следующую ячейку (вправо), после суммы, рассчитать - сколько процентов от 300 (трёхсот) составит значение в ячейке суммы.
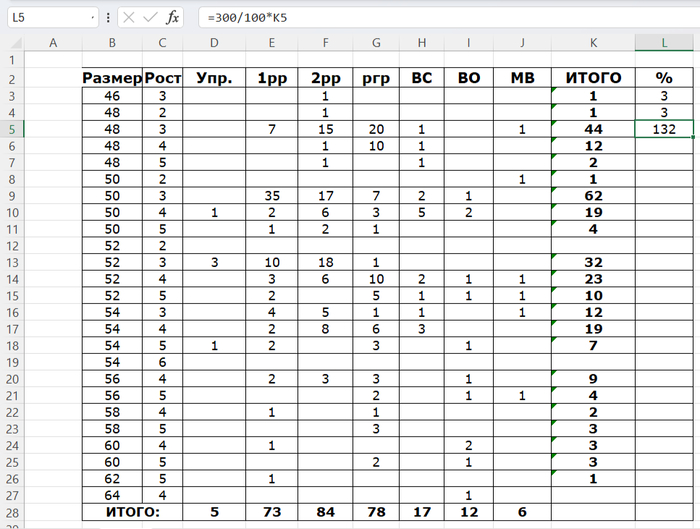
На скрине видны мои безуспешные попытки решить эту задачку...
Прошу подсказать - как правильно составить формулу.
Заранее всем спасибо :-)
UPD: Похоже я неясно выразился. В ячейке L5 нужно высчитать, сколько % от 300 составит значение ячейки K5.
UPD 2: Всё получилось :-)
Всем спасибо.




