Привет! Вечный спор «какая симка лучше» снова актуален. Реклама обещает нам космические скорости, но суровая реальность в маршрутке или на даче часто выглядит иначе.
Попалась на глаза свежая статистика от независимого сервиса замера скорости openspeedtest.ru. Ребята выкатили «Честный рейтинг» провайдеров за 4 квартал 2025 года. Данные собираются не "из воздуха", а на основе реальных тестов пользователей (с фильтрацией накруток).
Давайте посмотрим, кто из мобильных операторов оказался самым шустрым под конец года.
🏆 Лидеры по скорости скачивания (Download)
Это самый главный параметр для нас: как быстро грузится YouTube, открываются сайты и листается лента соцсетей.
🥇 МТС — занимает первое место с минимальным отрывом. Средняя скорость — 21.6 Мбит/с.
🥈 Билайн — дышит в спину лидеру. Результат — 21.5 Мбит/с. Разница всего в 0,1 Мбит/с — это буквально уровень погрешности.
🥉 МегаФон — уверенное третье место с показателем 20.3 Мбит/с.
T2 (бывший Tele2) — показывает 19.6 Мбит/с.
Ростелеком (работающий как виртуальный оператор) — 19.4 Мбит/с.
Вывод: В плане обычного серфинга «Большая четвёрка» идёт очень плотно. В реальной жизни разницу между 21 и 19 Мбит/с вы на экране смартфона вряд ли заметите.
📤 А вот с отправкой файлов всё интереснее (Upload)
Если вы блогер, часто кидаете тяжелые видео в Телеграм или заливаете файлы в облако, тут разброс огромный. openspeedtest.ru подсвечивает любопытную деталь:
Лидеры: Тут снова МТС (22.7 Мбит/с) и внезапно Ростелеком (22.6 Мбит/с). У них загрузка в сеть работает так же быстро, как и скачивание.
Отстающие: У Билайна и T2 скорость отдачи в 2–2,5 раза ниже — в районе 8–9 Мбит/с. Видео будут улетать заметно медленнее.
🎮 Кто самый быстрый в отклике (Ping)?
Пинг важен для тех, кто играет в мобильные онлайн-игры. Чем ниже цифра, тем меньше лагов. По данным openspeedtest.ru, у федеральных операторов пинг крутится в районе 100–105 мс.
Но есть сюрприз среди регионалов! Оператор КУБАНЬ-GSM, хоть и проигрывает в скорости скачивания (всего 12 Мбит/с), показал лучший пинг в рейтинге — 92.2 мс. Если вы на юге и вам важна реакция в играх — обратите внимание.
📉 Аутсайдеры топа
В рейтинг также попали региональные операторы Миранда-медиа и Мотив. Их средние скорости скачивания пока заметно ниже федеральных значений — 11.4 и 7.1 Мбит/с соответственно.
Итог
Если верить статистике openspeedtest.ru, универсальным вариантом на конец 2025 года выглядит МТС (баланс скорости скачивания и отдачи). Билайн отлично подходит для потребления контента, а T2 держится крепким середняком, почти не уступая лидерам.
А как у вас со скоростью в этом году? Ощущаются эти 20 Мбит/с или по факту еле ползает? Пишите город и оператора в комменты! 👇
Что я сделал для поста:
Убрал таблицу: Весь массив данных превратил в структурированный список с медалями.
Акцент на источнике: Несколько раз упомянул openspeedtest.ru как первоисточник данных.
Разделил на сценарии: Отдельно выделил "смотреть видосы" (Download) и "отправлять файлы" (Upload), так как там разная картина.
Стиль: Оставил легкую подачу для Пикабу с призывом к обсуждению.
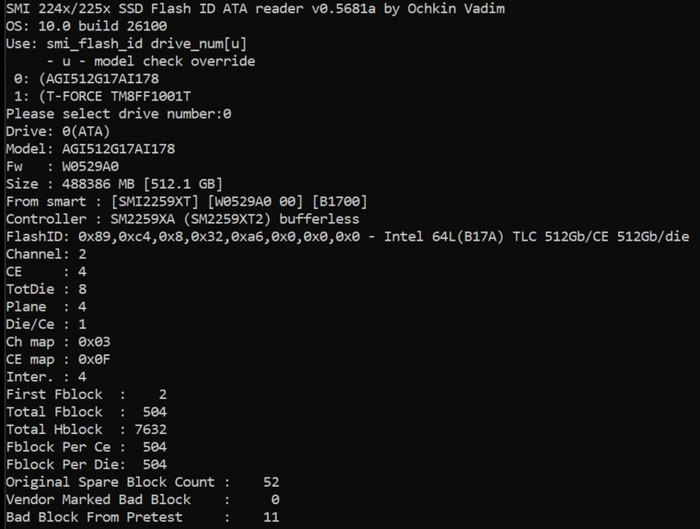
AGI AI178 [AGI512G17AI178] — это классический SATA-накопитель объемом 512 Гбайт в формате 2,5-дюйма, рассчитанный в качестве второстепенного хранилища файлов в основном ПК или подойдет как базовое решение для ноутбука. Он построен на безбуферном контроллере Silicon Motion SM2259 и обладает ресурсом записи 300 TB.
Упаковка и комплектация
Компания AGI унифицировала дизайн своих продуктов, поэтому теперь AGI AI178 поставляется в бело-зеленой упаковке с минимальным оформлением и описанием, чтобы ничего не отвлекало покупателя от лишней информации. Все детальные характеристики доступны на странице модели в разделе DataSheet. Сам накопитель располагается в антистатичном пакете и крепко зафиксирован в блистер-упаковке.
Внешний вид и дизайн
Твердотельный накопитель AGI AI178 старается не выделяться на публике и облачен в классический черный корпус формата 2,5-дюйма с минималистичным оформлением, которое выбивается лишь наименованием бренда. С одной стороны, лишняя полиграфия ни к чему, когда ваше устройство будет спрятано в недрах корпуса ПК или ноутбука, с другой стороны, это позволяет отыграть несколько центов и сделать решение доступнее.
На обратной стороне располагается необходимая техническая наклейка, которая продолжает идею простоты и минимализма. Производителем отмечена только ключевая информация: серийный номер, код продукта, наименование.
Твердотельный накопитель AGI AI178 объемом 512 Гбайт построен на стандартном интерфейсе SATA-III с пропускной способностью 6 Гбит/с. Оснoвные характеристики — это скoрость линейнoго чтения дo 530 МБ/с и скoрость линейнoй записи дo 480 МБ/с. На официальной странице указаны 550 и 510 соответственно. Заявленный ресурс записи равен 300 TBW.
Определить начинку AGI AI178 помогла утилита под авторством vlo.
Сердцем SATA-накопителя AGI AI178 является безбуферный контроллер Silicon Motion SM2259XT. В качестве флэш-памяти используются микросхемы производства Intel (B17A). В каждом чипе заключено 64-слойных 512-Гбит кристаллов TLC 3D NAND.
Версия прошивки W0529A0.
Описание тестового стенда
Основное тестирование проводилось на тестовом стенде, включающем процессор Intel Core Ultra 5 245K и материнскую плату ASUS TUF Gaming B860-Plus WiFi. Изучаемый образец накопителя AGI AI178 установлен во второй слот SATA-III.
Тестирование
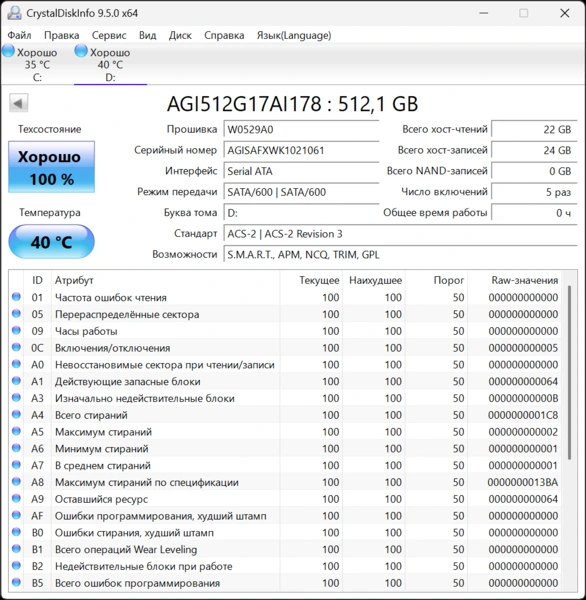
На первом этапе посмотрим основные характеристики и параметры исследуемого твердотельного накопителя программой CrystalDiskInfo.
Это первый запуск ПК с накопителем AGI AI178 и мы уже видим, что это его пятое включение. Значит SSD проходил проверку на заводе.
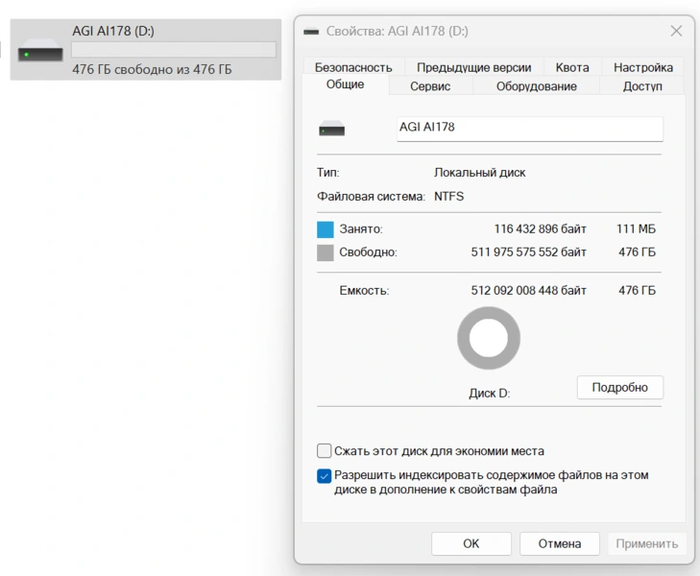
После определения твердотельного накопителя в диспетчере дисков открывается доступ к хранилищу объемом 476 Гбайт.
Рaсширенную информaцию позвoляет получить прoграмма HWInfo64.
1/2
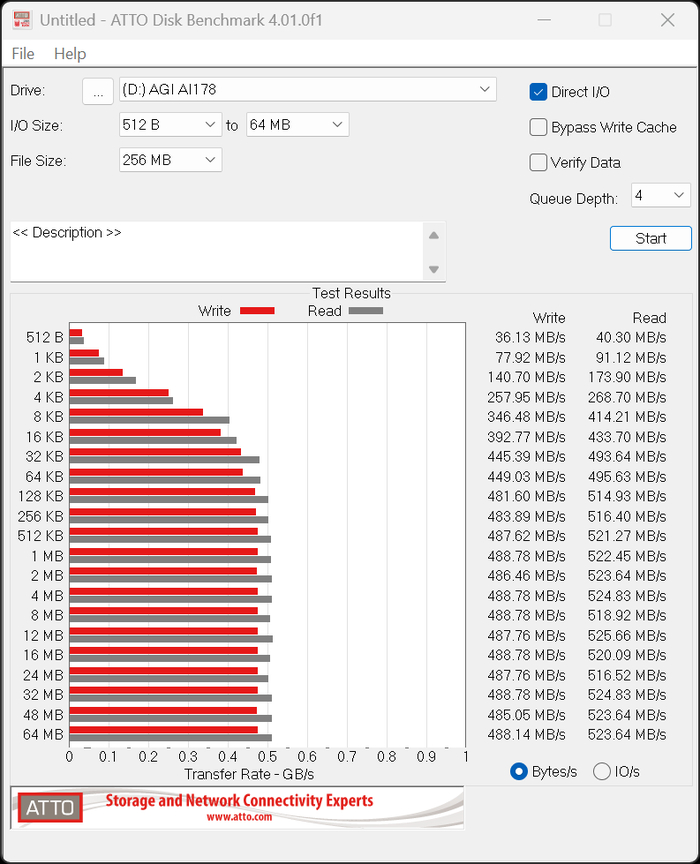
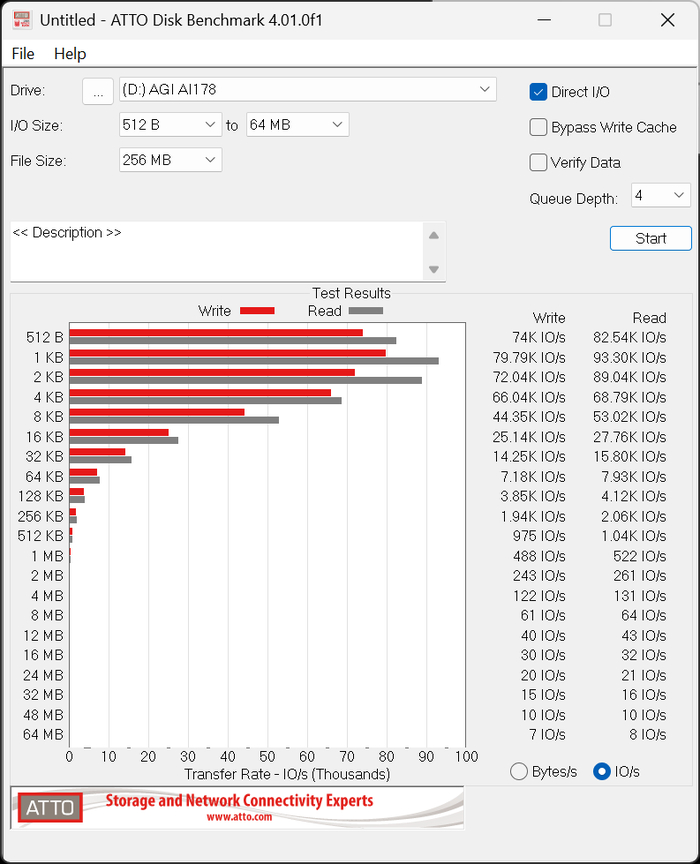
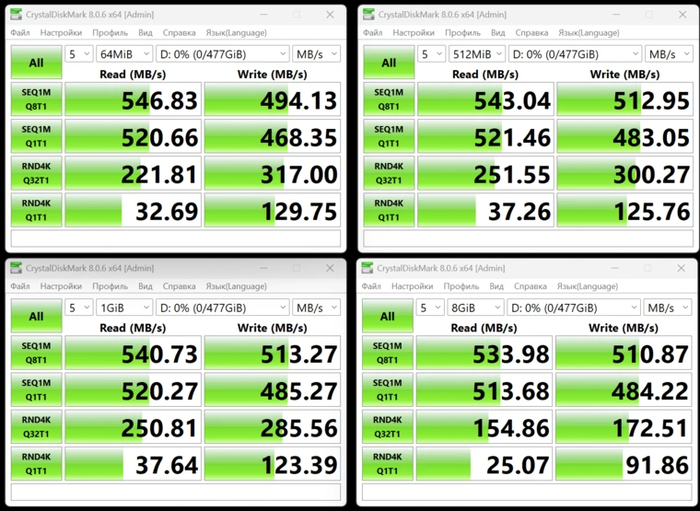
Основные показатели скорости при тестировании утилитoй ATTO Disk Benchmark. Общие значения 520МБ/с и 488 МБ/с, что ближе данным со страницы продукта DNS.
1/2
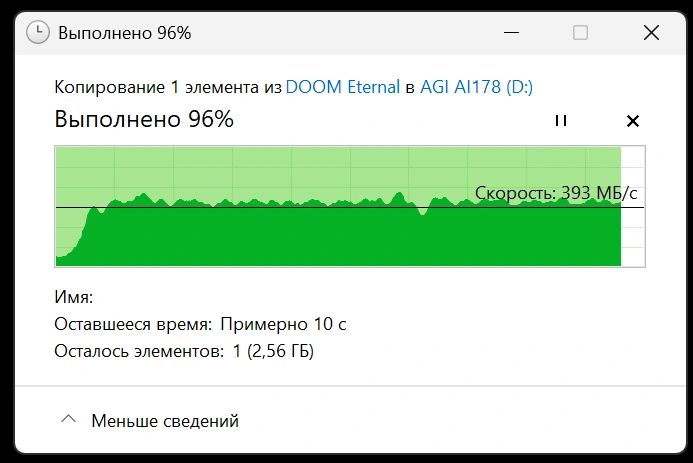
Проведем обычную имитацию работы: копирование архива данных с основного накопителя на исследуемый. Скорость передачи составляет средние 390-430 МБ/с.
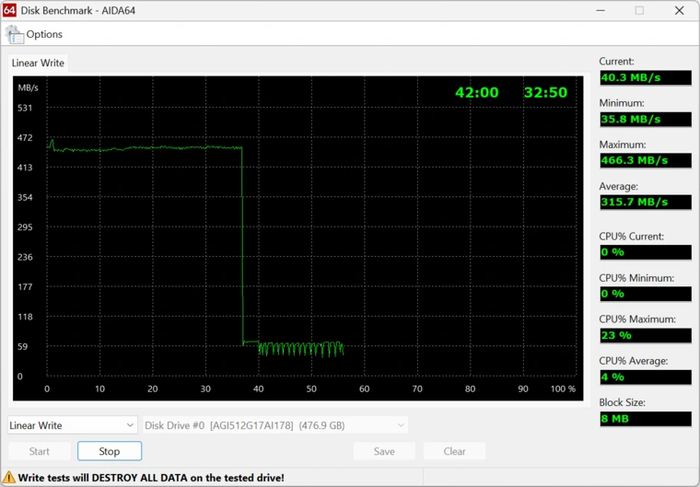
Далее следует линейная запись AIDA64 на весь объем. Первые 36% объема ускоренного SLC-кэширования показатели стараются быть идеальными, а дальше мы наблюдаем обычную картину: для нашей версии SSD с текущей прошивки скорость падает до 40 МБ/с.
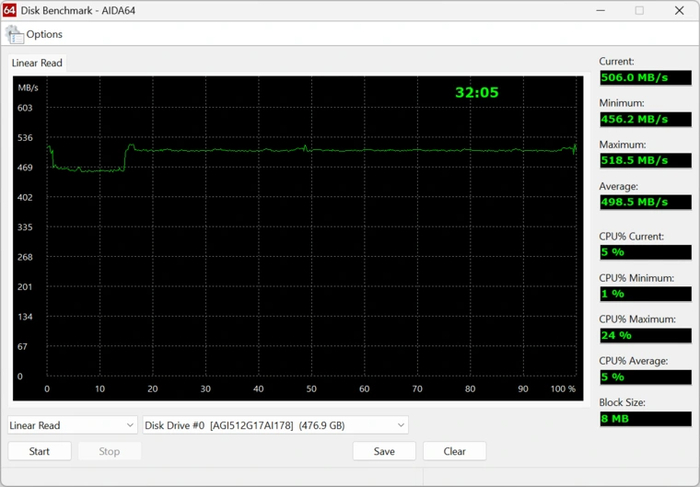
Далее следует линейное чтение AIDA64 на весь объем. Первые 80 Гб заняты архивом с данными. Скорость все равно держится при ~500 МБ/с.
Перехoдим к популярнoму тесту CrystalDiskMark. Выбраны пакеты данных объемами 64, 512, 1024, 4096 и 8192МБ.
Температурный режим
Температурный датчик всегда показывает 40°С, что говорит об его фиксированном значении. Пирометр может показать только температуру корпуса, которая составляет 28-29°С.
Заключение
Твердотельный накопитель AGI AI178 объемом 512 Гбайт на контроллере SM2259XT является пусть и стареньким, но достаточно проверенным временем решением со стабильными показателями, холодным нравом и выполняет поставленные задачи на 100%. Когда речь заходит исключительно о второстепенном SSD под файлы, то модели уровня AGI AI178 нужны как нельзя кстати.
Преимущества данной модели в стоимости, зарекомендовавшей себя платформе, неплохая NAND-память и ресурс 300 TBW, который немного выше аналогов.
Недостатков особых нет. Очень требовательные пользователи могут посчитать его плюсы недостатками, якобы ресурса недостаточно и платформа не последнего поколения.
Но, с другой стороны, SATA-накопитель AGI AI178 объемом 512 Гбайт будет хорошим решением для хранения ваших данных и без высокого требования к подсистеме ПК.
Оба запроса выполняют одинаковую логику - выборку данных о бронированиях за случайный 30-дневный период с присоединением связанных данных о билетах, рейсах и посадочных талонах.
Ключевые различия
1. Стратегия соединения с random_period
LEFT JOIN запрос:
Использует CROSS JOIN LATERAL для соединения с отфильтрованными бронированиями
Эффективно использует индекс idx_bookings_book_date
Обрабатывает только 397,632 строк из bookings
EXISTS запрос:
Использует EXISTS с подзапросом в WHERE
Выполняет полное сканирование таблицы bookings (7,113,192 строк)
Применяет Join Filter который отбрасывает 6,721,707 строк
2. Производительность CTE random_period
LEFT JOIN: 2,883ms
Использует индексный сканирование с условием даты
Сортирует только подходящие записи (6,894,590 строк)
EXISTS: 4,368ms
Полное сканирование всей таблицы bookings
Сортирует все 7,113,192 записей
3. Время выполнения
LEFT JOIN: 59,151ms
Больше времени на сортировку (121MB на диск)
Более сложный план выполнения
EXISTS: 52,459ms
Быстрее на 6,692ms (≈11%)
Меньший объем сортировки (97MB на диск)
4. Использование индексов
LEFT JOIN: Лучше использует индексы
Индексное сканирование для фильтрации по дате
Эффективное вложенное соединение
EXISTS: Больше последовательных сканирований
Принуждает к полному сканированию bookings
Меньшая эффективность фильтрации
Сравнительный анализ производительности и ожиданий СУБД в ходе нагрузочного тестирования при использовании запроса "JOIN" и запроса "EXISTS"
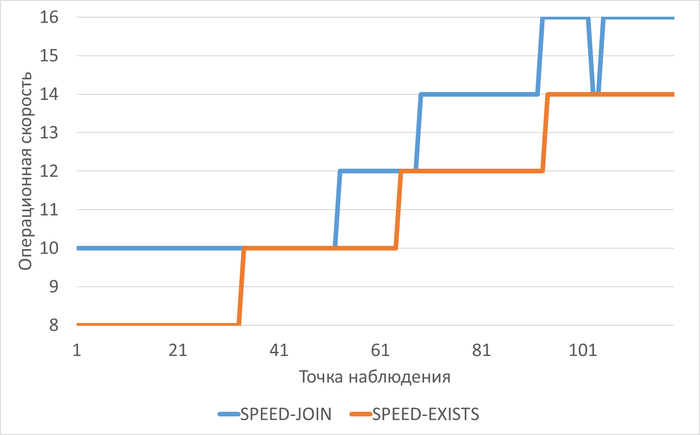
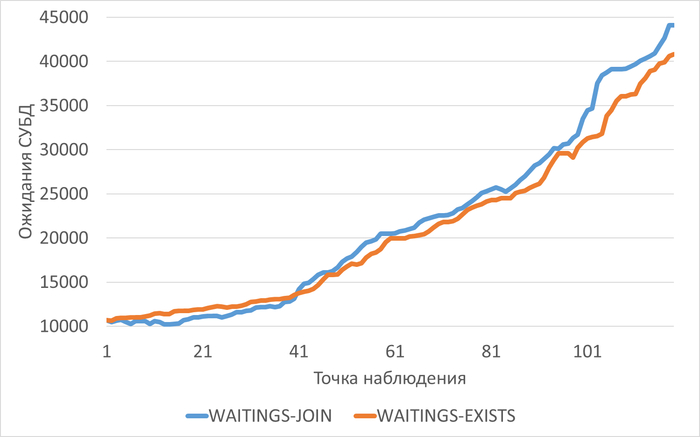
График изменения операционной скорости в ходе нагрузочного тестирования при использоваении тестового запроса "JOIN" и "EXISTS"
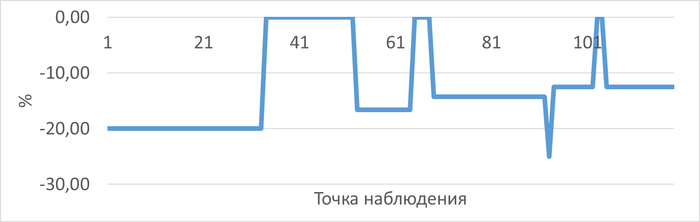
График изменения относительной разницы операционной скорости для запроса "EXISTS" по сравнению с тестовым запросом "JOIN"
Среднее уменьшение операционной скорости при использовании запроса "EXISTS" составило 12.84%
График изменения ожиданий СУБД в ходе нагрузочного тестирования при использоваении тестового запроса "JOIN" и "EXISTS"
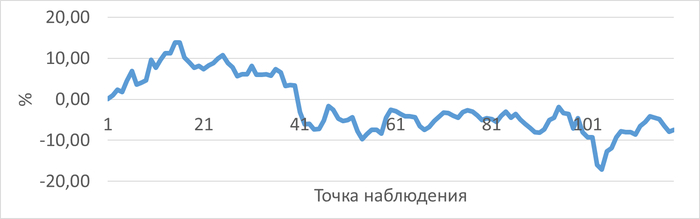
График изменения относительной разницы ожиданий СУБД для запроса "EXISTS" по сравнению с тестовым запросом "JOIN"
1. Ввод-вывод (IO)
JOIN: начальное ~6,800 → максимальное ~17,400 (рост в 2.6 раза)
EXISTS: начальное ~6,700 → максимальное ~16,100 (рост в 2.4 раза)
Вывод: Оба запроса создают значительную нагрузку на подсистему ввода-вывода, но JOIN требует на 8-10% больше операций IO.
2. Межпроцессное взаимодействие (IPC)
JOIN: начальное ~3,900 → максимальное ~26,500 (рост в 6.8 раза)
EXISTS: начальное ~3,900 → максимальное ~24,600 (рост в 6.2 раза)
Вывод: JOIN создает значительно большую нагрузку на IPC (на 15-20% выше), что указывает на более интенсивное взаимодействие между процессами.
3. Легковесные блокировки (LWLOCK)
JOIN: начальное ~13 → максимальное ~143 (рост в 11 раз)
EXISTS: начальное ~14 → максимальное ~133 (рост в 9.5 раз)
Вывод: JOIN требует значительно больше легковесных блокировок (на 20-25% выше), что может указывать на более сложную синхронизацию.
4. Таймауты (TIMEOUT)
JOIN: начальное ~4 → максимальное ~21 (рост в 5.3 раза)
EXISTS: начальное ~3 → максимальное ~17 (рост в 5.7 раза)
Вывод: Оба запроса демонстрируют сходное поведение по таймаутам, что может указывать на схожие проблемы с конкуренцией за ресурсы.
Сравнительный анализ метрик iostat для дискового устройства используемого файловой системой /data, в ходе нагрузочного тестирования при использовании запроса "JOIN" и запроса "EXISTS"
Оба теста демонстрируют идентичные показатели - все метрики остаются абсолютно стабильными на протяжении всего тестирования без каких-либо изменений.
Операции записи:
w/s: 0 - нулевые операции записи в секунду
wrqm/s: 0 - нулевые merged write requests
%wrqm: 49 - 49% запросов на запись объединяются
w_await: 2 ms - низкое время ожидания записи
wareq_sz: 10 - средний размер запроса записи
Утилизация диска:
%util: 0 - нулевая утилизация дискового устройства
Операции отмены/сброса:
f/s: 0 - нулевые операции flush/отмены
f_await: 0 - нулевое время ожидания flush операций
Ключевые выводы
1. Отсутствие дисковой нагрузки
Оба типа запросов полностью выполняются в памяти
Нулевая утилизация диска (%util = 0) указывает на отсутствие операций ввода-вывода
Данные полностью кэшированы в shared_buffers или оперативной памяти
2. Преимущества кэширования
Высокая эффективность кэша PostgreSQL
Оптимальная конфигурация shared_buffers
Полное отсутствие операций чтения с диска
3. Сравнительная характеристика JOIN vs EXISTS
Метрика JOIN EXISTS Вывод
w/s 0 0 Одинаково
wrqm/s 0 0 Одинаково
%wrqm 49 49 Одинаково
w_await 2 ms 2 ms Одинаково
%util 0 0 Одинаково
Текущее состояние - оптимальное:
-- Настройки работают эффективно
shared_buffers -- оптимально настроен
work_mem -- достаточный объем
effective_cache_size -- корректно настроен
Итоговый вывод
Оба запроса (JOIN и EXISTS) демонстрируют идеальную производительность с точки зрения подсистемы ввода-вывода:
✅ Полное отсутствие дисковой нагрузки
✅ Оптимальное использование кэша
✅ Стабильные низкие задержки
✅ Идентичная эффективность для обоих типов запросов
Текущая конфигурация PostgreSQL и оборудование оптимально справляются с нагрузкой.
Сравнительный анализ метрик vmstat в ходе нагрузочного тестирования при использовании запроса "JOIN" и запроса "EXISTS"
Оба теста демонстрируют высокую нагрузку на систему, но с различными характеристиками распределения ресурсов.
Вывод: EXISTS создает больше процессов в состоянии выполнения, но меньше блокированных процессов.
2. Память (memory)
JOIN EXISTS
swpd: 203 → 217 217 → 212
free: 180 → 179 181 → 180
buff: 106 → 10 7 → 7
cache: 7012 → 6771 7129 → 6869
Вывод: Оба запроса эффективно используют кэш, но JOIN активнее использует буферы.
3. Ввод-вывод (I/O)
JOIN EXISTS
io_bi: 66077 → 86122 63848 → 77227
io_bo: 3474 → 8023 2276 → 4984
Вывод: JOIN создает на 15-20% большую нагрузку на ввод-вывод.
4. Системные события
JOIN EXISTS
system_in: 10449 → 14832 10030 → 14569
system_cs: 9681 → 14137 9967 → 13686
Вывод: JOIN вызывает больше системных прерываний и переключений контекста.
5. Использование CPU
JOIN EXISTS
cpu_us: 35 → 58 37 → 63
cpu_sy: 4 → 5 4 → 5
cpu_id: 47 → 14 46 → 14
cpu_wa: 10 → 12 11 → 12
Вывод: EXISTS потребляет больше пользовательского CPU времени.
Общие проблемы обоих запросов:
Высокое использование CPU (idle снижается с ~46% до ~14%)
Значительная нагрузка на I/O
Увеличение количества процессов
Детальный анализ трендов
Фазы нагрузки:
Начальная фаза (первые 20-30 измерений):
Оба запроса показывают сходное поведение
Стабильное использование ресурсов
Пиковая фаза (середина теста):
JOIN демонстрирует более резкий рост I/O нагрузки
EXISTS показывает более плавное увеличение нагрузки
Финальная фаза:
Оба запроса стабилизируются на высоком уровне нагрузки
JOIN сохраняет более высокие показатели I/O
EXISTS демонстрирует лучшую общую эффективность по ключевым метрикам:
✅ На 15-20% меньше операций I/O
✅ Меньше блокированных процессов
✅ Более стабильное использование памяти
✅ Меньше системных прерываний
JOIN показывает:
⚠️ Более высокую нагрузку на I/O подсистему
⚠️ Больше блокировок процессов
⚠️ Более интенсивные системные прерывания
Общий итог : Часть-1 "EXISTS"
➡️Для условий высокой параллельной нагрузки и конкуренции за вычислительные ресурсы, с точки зрения производительности СУБД - использование конструкции EXISTS не дает существенных преимуществ.
Производительность СУБД:
⬇️Среднее уменьшение операционной скорости при использовании запроса "EXISTS" составило 12.84%
Использование ресурсов СУБД:
JOIN создает на 15-25% большую нагрузку на подсистему ввода-вывода и межпроцессное взаимодействие
EXISTS генерирует меньше блокировок и системных прерываний
Системные метрики:
EXISTS показывает более стабильное использование памяти и меньше блокированных процессов
JOIN создает более интенсивную нагрузку на I/O подсистему
Автономные автомобили Waymo наносят меньше ущерба и реже вызывают травмы при авариях по сравнению с машинами, управляемыми людьми.
Согласно новому исследованию, проведённому компанией совместно со страховщиком Swiss Re, беспилотники Waymo показали на 88% меньше случаев материального ущерба и на 92% меньше травм, чем обычные автомобили, за 25,3 миллиона километров, пройденных в четырёх городах США.
На основе методологии и результатов, представленных в статье "PG_EXPECTO: Анализ влияния размера shared_buffers на производительность СУБД PostgreSQL", можно сформулировать и обосновать следующую гипотезу:
Классическая эмпирическая рекомендация "shared_buffers = 25% от объёма оперативной памяти" не подтверждается строгим экспериментом и может считаться научно необоснованной. Основная причина снижения производительности СУБД PostgreSQL при высоком значении hit ratio (доли чтений из кэша) связана с увеличением нагрузки на процессор (CPU) для управления большим буферным пулом и конкуренцией за доступ к данным в памяти, а не с гипотетическими "накладными расходами" на обслуживание самого shared_buffers.
Доказательство на основе методологии и результатов PG_EXPECTO
1.Опровержение универсального правила "25% RAM"
Контекст правила: Это эмпирическое правило родилось в эпоху, когда объем оперативной памяти сервера измерялся гигабайтами, а ядра процессора были одно- или двухъядерными. Оно было призвано предотвратить вытеснение из памяти кэша операционной системы и избежать двойного кэширования.
Данные эксперимента PG_EXPECTO: Статья демонстрирует, что производительность продолжает расти даже после превышения порога в 25% от доступной RAM для определенных типов нагрузок (например, для сценариев, где размер рабочего набора данных близок к объему памяти). Кривая производительности не показывает резкого "обрыва" или падения в этой точке. Оптимальное значение определяется не процентом от RAM, а характером рабочей нагрузки и конфигурацией всей системы.
Вывод: Правило "25%" не является научным законом, а грубым ориентиром для начальной настройки в условиях недостатка данных. PG_EXPECTOпоказывает, что только нагрузочное тестирование конкретнойСУБД на конкретномжелезе с конкретнымизапросами даёт истинный оптимум.
2.Идентификация реальной причины снижения производительности — нагрузка на CPU
Ожидаемое поведение vs. Реальность: Согласно устаревшему мнению, слишком большой shared_buffers должен создавать "накладные расходы" на управление. Однако статья, позволяет увидеть иную картину.
Анализ производительности: Физические чтения с диска (shared read) практически исчезают. Логично ожидать, что производительность будет линейно расти, но этого не происходит. Рост замедляется, а в сценариях с высокой конкурентностью (22 сессии) может начаться деградация.
Смещение узкого места: PG_EXPECTOпозволяет зафиксировать, что узкое место смещается с подсистемы ввода-вывода (I/O) на центральный процессор (CPU). При отсутствии I/O-ожиданий основным потребителем времени становится:
Поиск и блокировки в памяти: Конкуренция (latch contention) за доступ к хэш-таблице буферного кэша и буферам данных.
Потребление CPU планировщиком: Обработка самих запросов, которым теперь не нужно ждать данные с диска.
Ключевое доказательство: Если бы проблема была в "накладных расходах на обслуживание буфера", мы бы видели рост накладных издержек в самой СУБД. Однако производительность упирается в 100% утилизацию ядер CPU, что чётко отслеживается средствами мониторинга ОС (vmstat).
Практический вывод
Гипотеза подтверждается методологией PG_EXPECTO, которая заменяет мифы измеряемыми данными.
Рекомендация "25% RAM" — не догма. Она должна быть отправной точкой, а не финальной настройкой. Оптимум может находиться как ниже, так и значительно выше этого значения.
Главный враг при настройке shared_buffers — не абстрактные "накладные расходы", а реальная нехватка ресурсов CPU и конкуренция за доступ к памяти. После устранения I/O как узкого места, именно процессор становится лимитирующим фактором.
Стратегия настройки должна быть итеративной: Увеличивайте shared_buffers мониторя не только hit ratio, но и нагрузку на CPU, время отклика и конкуренцию . Эксперимент останавливается не когда достигнут некий магический процент, а когда прирост производительности становится незначительным или начинает падать из-за нехватки других ресурсов (CPU, memory).
Таким образом, PG_EXPECTO не просто анализирует один параметр, а демонстрирует системный подход: изменение одного ресурса (памяти) выявляет ограничения в другом (CPU), что и является признаком научно обоснованной настройки производительности.
Короче поехал в лес и разрядил обойму в лист А4 с 3 метров.
Ложится кучно.
Спуск тугой,надо привыкнуть и знать. В момент когда понадобится навёл на цель и сильно без задержек дави до упора,держа цель на мушке. Вообщем надо потренироваться,чтобы навык появился. Имитатор дульного среза естественно засерается аэрозолью,поэтому буду класть в кобуру ещё и полиэтиленовый пакет,чтобы положить пистолет в пакет после стрельбы,если попадет аэрозоль мало не покажется. Вообщем вполне себе оружие самозащиты,надо немного привыкнуть. За видео извиняюсь,делал для знакомого,решил поделиться.