

Армен Вещает! Багги своими руками! Проект для настоящих суровых мужиков
В гараже Притягательного Завода строим автомобиль для необычных путешествий. Нравится проект? Ставьте лайк 👍 снимем еще.
В гараже Притягательного Завода строим автомобиль для необычных путешествий. Нравится проект? Ставьте лайк 👍 снимем еще.
Внимательно посмотрите на картинку и дайте ответ. А что ответил искусственный интеллект – читайте в этой статье.

Я в своей работе (решение производственных и конструкторских проблем) использую следующие нейросети: DeepSeek, Qwen, Perplexity и иногда GigaChat. Все они доступные в России без впн и какой-то сложной регистрации. Да почти все бесплатные! Только у Perplexity расширенный функционал за доллары. Но и бесплатного – вполне достаточно.
Что это за нейронки и как их подключить – не буду повторяться, есть в других моих статьях.
Начал я с этого искусственного интеллекта. Загрузил файл с картинкой. И как остальным нейросетям, я задал достаточно простой промт:
Изучи изображение и дай ответ на вопрос, который есть на этом изображении.
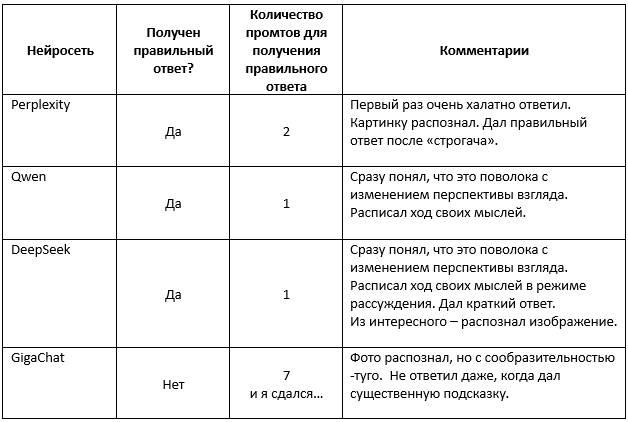
Такое ощущение, что Perplexity повела себя как балагур-подчинённый, к которому неожиданно подошёл начальник и что-то спросил. Но как соображающий балагур: ответ был выдан быстро. Очень короткий, с похожими на логические связи цепочки рассуждений. Но неправильный. Почему-то нейросеть посчитала, что автомобиль занял место 88.
Пришлось указать на ошибку:

И правильный ответ не заставил себя долго ждать!
Попытался сбить нейронку с толку – мол, и сейчас ошиблась – не помогло. Хотя, бывает, что мнение своё меняет.
У Qwen относительно недавно появилась функция анализа изображений по частям. И, такое ощущение, что этот китаец хвалится этой функцией. Иногда действительно можно увидеть что-то новое для себя в таких анализируемых картинках. Но не в этот раз.
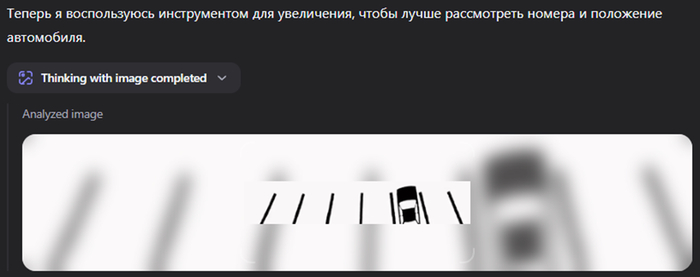
Эта нейросеть обстоятельно расписала каждый шаг своего анализа этой задачи. И как она увеличивала каждый фрагмент картинки, и что она видела…
Исписала два экрана текстом и дала правильный ответ.
Неожиданно. Осенью прошлого года разработчики заявили, что DeepSeek теперь умеет анализировать изображения. Пару раз я закидывал картинки, но анализ был достаточно поверхностный – узнавала только крупные детали. А под Новый год вообще эту функцию отключили. Либо картинка не грузилась, либо сразу появлялось сообщение, что данный тип файла прочитать не может. А тут неожиданно прочитала и дала правильный ответ!
Разработка Сбера. Держу её в поле зрения, так как случись что и остались мы без зарубежных разработок. ChatGPT – на территории России не доступен вообще (только с магией). Perplexity (разработка США) – расширенную версию обычным способом не купить на российскую карточку. Но с этими всё ясно. Но некоторые китайские нейронки – тоже ограниченно доступны! Например, китайский Klign при помощи которого делают картинки и видео, нельзя оплатить российской картой. Так что, надо страховаться.
Так вот, GigaChat. Недавно приятно обновился – работают. Вроде как добавили Кандинского (тоже разработка Сбера), но мне не понравилось то, что многие функции (особенно дорисовки) исчезли!
И, к сожалению, хоть интерфейс и стал приятнее и понятнее, но ума не особо прибавилось.
На мой промт: «Изучи изображение и дай ответ на вопрос, который есть на этом изображении», я получил быстрый, но не верный ответ – 88.

Ну ладно. Было такое. Указываю на ошибку, прошу лучше подумать. Результат – признал, что ошибся и 96.
По его логике, между местами 88 и 98 автомобиль занял именно девяносто шестое место!
Ну почему?! Почему из 9 номеров выбран именно этот?!
«Вы правы. Ответ – 94»

Говорят, что грубое обращение с нейронками помогает повысить точность ответа. Похоже, это не этот случай.
А потом были дважды вариант «88» и вариант «86». И я сдался…
Современные нейросети дают возможность общаться с ними не только при помощи текста, но и при помощи картинок. Картинки, кстати, могут нести больше информации, чем способен человек описать словами. Часто человек может и не видеть, что есть на картинке: «смотрит, но не видит».
А нейросеть может увидеть. Как, например, другой человек (которого рядом может и не оказаться, а нейросеть всегда в телефоне). И у меня вопрос, а что может увидеть та или иная нейросеть и как она мне может помочь в решении производственных и конструкторских проблем? Как с ней более эффективно общаться при помощи изображений?
Представляете: фотографируете нужным образом процесс или узел, задаёте правильный промт и за пять минут получаете способы решения проблемы! Красота!
Кто ещё не сообразил, попробуйте посмотреть на парковку с другой стороны. А я пока покажу итоговую таблицу моего эксперимента.
Для тех, кто поленился подумать над задачкой у меня две новости.
Первая новость. Задачка относительно простая. Уровня начальной школы. Если и дальше так пойдёт, можете остаться без работы. Ну или вы немного отдохнули и с пользой – узнали про нейронки. 😊
Вторая новость. Правильный ответ 87. Вы сейчас смотрите на картинку и читаете цифры слева на право. Взгляд на парковку как бы сверху от бордюра. Если посмотреть на парковку сверху и со стороны дороги, то цифры надо будет читать справа на лево и их надо будет перевернуть: 86, ??, 88, 89…
![🗓 25.01.1947 — Патент на первую видеоигру [вехи_истории]](https://cs16.pikabu.ru/s/2026/01/23/07/4ovsiltt.jpg)
🗓 25.01.1947 — Патент на первую видеоигру [вехи_истории]
👨🦰 Томас Голдсмит-младший подал патент на «Cathode Ray Tube Amusement Device» — первое электронное игровое устройство на основе ЭЛТ.

Томас Голдсмит-младший
🚀 Игрок управлял «ракетой» (точкой света на экране осциллографа), стреляя по целям, нарисованным прямо на стекле.
📃 Патент выдан в 1948-м, но устройство осталось лабораторным экспериментом — на 11 лет раньше Tennis for Two и на 25 лет раньше Pong.
Деталь:
Это была аналоговая игра без компьютера и программы — чистая физика электронного луча.
Российский рынок промышленных роботов действительно прибавил: по данным Центра развития промышленной робототехники Университета Иннополис, в 2025 году объём рынка вырос на 14% и достиг 7,86 млрд рублей. Это заметный шаг вперёд после нескольких лет стагнации, но за радостными цифрами прячется ряд существенных ограничений и противоречий. При сохранении нынешних темпов рынок к 2030 году может подрасти до 15,1 млрд, а при активной господдержке и больших вложениях - теоретически вырасти до 48 млрд; правда, для второго варианта потребуются триллионы рублей инвестиций и системная госполитика, которой пока не видно.
Плотность роботизации в стране выросла, но Россия всё ещё отстаёт от мировых лидеров: в Южной Корее на 10 тысяч работников приходится более тысячи промышленных роботов, в Китае - сотни, в США - почти триста. У нас же пока уровни в разы ниже, и чтобы войти в топ-25 по плотности потребуется массовая замена оборудования и переоснащение предприятий. Бюджетные вливания направлены в отрасль - на федеральный проект до 2027 года выделено уже 88,9 млрд рублей - но этого явно недостаточно для масштабной модернизации.
Практическая сторона тоже не праздник. Роботы полезны там, где много монотонной или опасной работы: металлургия, машиностроение, пищевая промышленность, логистика. Они могут поднять производительность и снизить травматизм. С другой стороны, для внедрения роботов предприятиям нужно перестраивать цеха, менять процессы, переучивать персонал и вкладываться в инфраструктуру. Эти издержки и создают барьер: лишь часть компаний готовы ждать окупаемости пять лет и более, многие готовы инвестировать только в готовые, "под ключ" решения.
Социоэкономический эффект вызывает больше вопросов, чем ответов. Массовая роботизация повышает эффективность, но не гарантирует справедливого распределения выгоды. Инвестиции и прибыль чаще концентрируются у собственников и крупных игроков, а рабочие получают угрозу сокращений и переобучение на условиях рынка. Без чёткой политики перенаправления выгод в пользу занятости и образования автоматизация рискует усилить неравенство, а не решить проблему производительности.
Компании готовы брать роботов у российских производителей, где ценят сервис и поддержку. Это плюс для локального рынка и индустриального суверенитета. Но зависит многое от реального объёма инвестиций и от того, кто будет оплачивать модернизацию — бизнес, государство или те же работники через сокращения и снижение социальных гарантий.
Cектор растёт, цифры радуют, но рост сам по себе не решит системных задач. Чтобы роботизация стала стимулом для широкого экономического и социального прогресса, нужна не только техника, но и политика: прозрачные инвестиционные программы, программы переобучения, защита занятости и механизмы перераспределения выгод. Иначе это будет просто новый виток концентрации капитала под видом технологического прогресса.
Раньше я работал инженером-программистом ВСЕГО ЛИШЬ ЗА 60 000 РУБЛЕЙ В МЕСЯЦ с таким вот кругом тупых обязанностей:
- Заправить картридж, прочистить коротрон, подключить сетевой принтер, разобраться с зажёванной бумагой...
- Разместить новость на сайте/в группе ВК, исправить цвет кнопки, слегка подшаманить со стилем, разобрать письма в ящике эл. почты по папкам...
- Помочь сотруднику установить то или иное программное обеспечение, подключиться к базе 1С, переустановить ОС, заменить плашку ОЗУ, разобраться с автозагрузкой ненужных программ, установить Яндекс.Браузер и LibreOffice (у нас была гос. компания)...
- Разгрузить грузовик с орг. техникой, бумагой, стеллажами для серверной, разобраться с порядком расположения складских объектов...
- Перенести системный блок, монитор, иные элементы АРМ с этажа на этаж и из кабинета в кабинет...
- Отформатировать по ГОСТу документ Word, заполнить таблицу Excel...
Естественно, со временем мне это надоело (шарящих ребят надо повышать и обеспечивать их бонусами, чтобы они не разбегались), и я прямо заявил начальнику, что увольняюсь. Недолго думая, он уволил меня одним днём.
Сказал так: "Я вместо тебя другого студента-эникея найду!" (А МНЕ 30 - Я ДАЛЕКО НЕ СТУДЕНТ!).
Я пошёл в сферу фриланса, а именно - выполнение студенческих работ. У меня неплохо получилось: за месяц я заработал 180к. А именно, за январь этого года. Очень хорошо мне помогли нейронные сети: Gemini 3 Pro и ChatGPT 5.2 Thinking. Это, если что, не "халява", а автоматизация и прогресс.
При этом в комментариях я сталкиваюсь с такими вот недалёкими индивидами:

По всей видимости, данный товарищ выступает против искусственного интеллекта да и прогресса в целом. Он смотрит на мир зашоренным взором... для него дико всё новое и современное - он бы хотел жить в каменном веке. Ему невдомёк, что общество развивается, а вместе с ним - и способы заработка хлебушка и стаканчика вина на жизнь...
Таким людям надо только мордой тыкнуть в реальность:
- Да, Вася создаёт удалённо сайты и зарабатывает 300к.
- Да, Маша занимается дизайном и получает 150к.
- Да, Света разрабатывает инженерные проекты дома и имеет 400к с каждого проекта.
- ДА, ПЕТЯ ВЫПОЛНЯЕТ СТУДЕНЧЕСКИЕ РАБОТЫ И ЖИВЁТ С ДОСТОЙНЫМ ДОХОДОМ!
Вот когда мы все научимся признавать очевидные вещи, мир станет чуточку лучше.)
Представляем FlashForge AD5X — абсолютно новый профессиональный настольный 3D-принтер, разработанный для инженеров, дизайнеров и производителей, готовых выйти на новый уровень творчества и точности. Принтер AD5X поражает своей скоростью, производительностью и возможностями, становясь прекрасным решением для прототипирования, индивидуального проектирования и массового изготовления изделий.

Почему выбирают FlashForge AD5X?
✅ Закрытая камера и крупная область печати: Закрытый корпус предотвращает внешние влияния, обеспечивая стабильную температуру и стабильно высокое качество печати. Площадь построения 220x220x220 мм идеально подходит для крупных деталей и проектов.
✅ **Автоматическая калибровка и система MultiColor**: Снижает затраты времени на подготовку к печати и реализует уникальные возможности для многослойной и многоцветной печати.
✅ **Высочайшая скорость печати**: Скорость до 300 мм/с позволяет создавать объекты быстрее, чем конкурирующие аналоги, повышая общую производительность.
✅ **Поддержка различных материалов**: Рабочая температура до 300°С позволяет обрабатывать различные виды пластика, включая композитные материалы вроде PLA-CF и PETG-CF, удовлетворяя потребности различных отраслей промышленности.
✅ **Дистанционное управление и видеонаблюдение**: Через Wi-Fi или Ethernet управляйте принтером удаленно, контролируйте процесс печати и оставайтесь в курсе статуса проекта.
✅ **Надёжность и неприхотливость**: Автоматическая замена филаментов и сопел упрощает смену цветов и материалов, делая процесс печати доступным каждому.

FlashForge AD5X откройте для себя мир быстрой, точной и креативной 3D-печати с широкой палитрой возможностей!
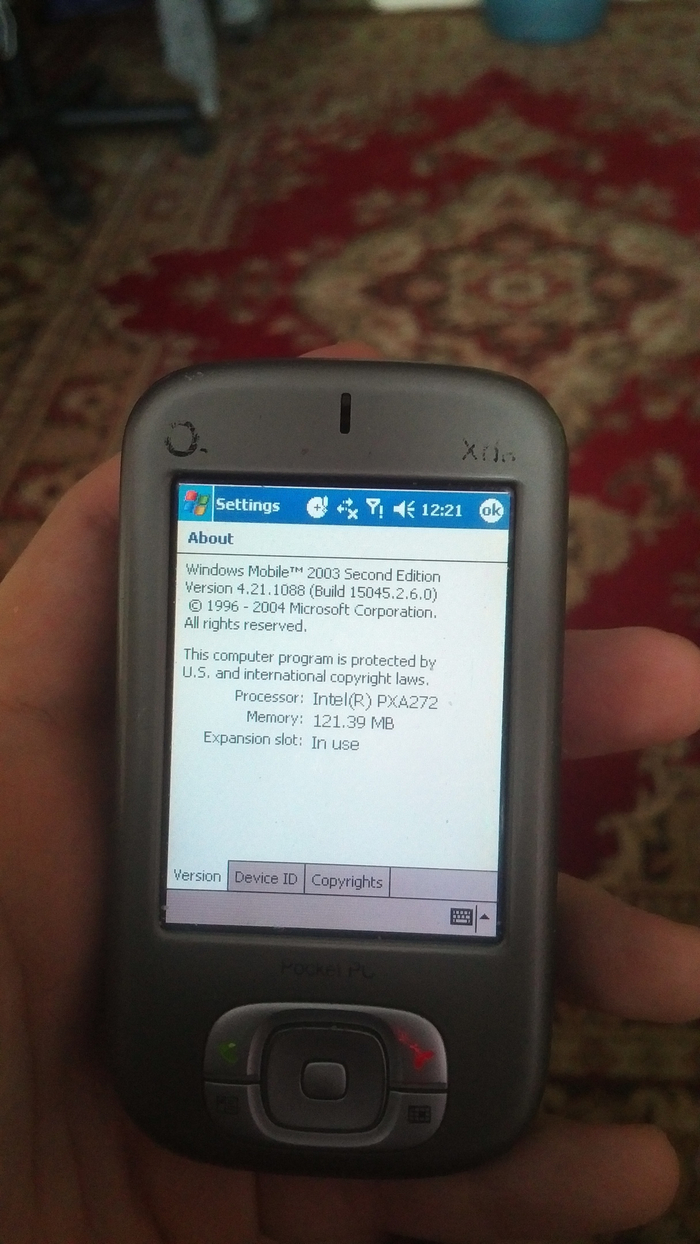
Мои постоянные читатели наверняка знают мою особую любовь к устройствам на Windows CE и Windows Mobile. Я коллекционирую, восстанавливаю, модифицирую и стараюсь дать новую жизнь этим прекрасным гаджетам, о чём частенько пишу отдельные статьи. Одним из примеров такого моддинга был апгрейд оперативной памяти - операция, которая была очень популярна в нулевых годах!
Дело в том, что в большинстве коммуникаторов и карманных компьютеров было установлено 64 мегабайта оперативной памяти типа SDRAM. С 2003 по 2008 год этого хватало с головой вообще для всего: благодаря экономичной к памяти Windows CE и адекватно написанным программам, в оперативке можно было одновременно держать Java-приложение, клиент ICQ, электронной почты, Internet Explorer и даже какую-нибудь не сильно тяжелую игру. И при всём этом, многозадачность у устройств была полноценная: без автоматического "прибивания" приложения системой, как это реализовано в Android и iOS:
При всём этом, в ранних устройствах на WM все пользовательские данные хранились в ОЗУ, так что от 64 мегабайт обязательно откушивался небольшой процент для фотографий, видосов и прочего контента. Чаще всего это было 15-20МБ. При этом объём выделяемой памяти под контент можно было регулировать на лету с помощью специальной программы в панели управления:

А ведь были и КПК с 32МБ оперативной памяти - и на них можно было вполне нормально жить!
Но как мы с вами понимаем... времена тогда были другие, да и сами устройства на Windows Mobile пользовались популярностью по большей части у гиков, которым интересно во всём разбираться и попробовать всякий разный софт. Накатить на RoverPC оболочку Manilla с HTC? Пожалуйста! Портировать Fallout 2 и HoMM с ПК? Были и такие ребята! Установить на 5-летний коммуникатор последнюю версию Windows Mobile? Дядя Cotulla и не такое проворачивал :)

Именно на него Cotulla когда-то портировал WM 6.5... на устройство, где в оригинале была PocketPC 2003 :)
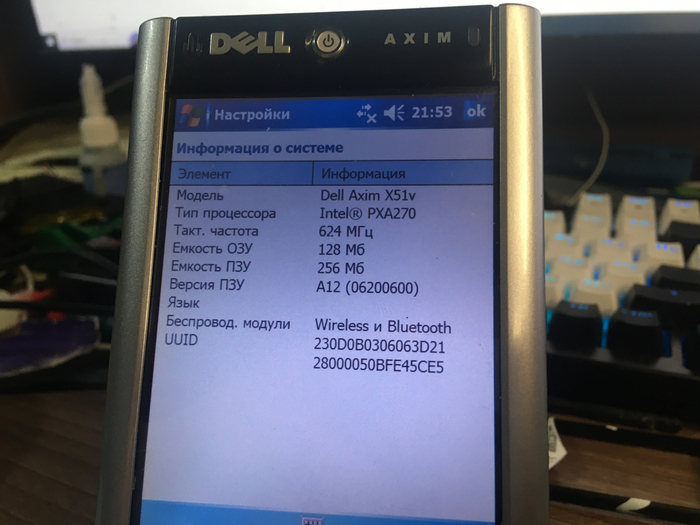
Но вот незадача: с ростом интереса у гиков, росли и потребности, и если упора в мощнейший ARM-процессор Intel PXA272 с частотой 624МГц ещё не было, то вот ОЗУ хватало далеко не всем! И поэтому гики со всей планеты начали искать возможность увеличения объёма ОЗУ.
Дело в том, что как я уже говорил ранее, КПК и коммуникаторы в основном использовали стандартные чипы оперативной памяти типа SDRAM. Такие применялись везде: как в смартфонах Nokia и Sony Ericsson на Symbian (меньших объёмов, но с почти идентичной распиновкой и корпусом), так и в обычных кнопочных телефонах (Siemens C65/C75 и т.д.). А поскольку в те годы почти все Windows Mobile устройства производила HTC по заказу других брендов (HP, Dell и многие другие), она закладывала в аппаратную платформу почти каждого устройства (Magician, Wizard, Blue Angel и т.д.) возможность установки чипов памяти большего объёма. И если где-то достать эти чипы памяти, то можно было проапгрейдить и свой девайс:

Эти самые чипы имели маркировку Infineon HYB25L256160AC и достать под заказ их можно было почти везде, правда и стояли они довольно дорого. Сейчас их можно найти по 200 рублей за штучку, но тогда, уверен, цена была не менее 400-500 рублей (при долларе по 30). Однако это-ж не обычный компьютер, где ОЗУ можно заменить плашкой, эту память нужно было сначала припаять и вот тут начинались проблемы: тогда всякие W.E.P'ы и прочие бюджетные YaXun'ы 852 не были так распространены вне мастерских по ремонту телефонов и ноутбуков, да и гайдов по перекатке шаров и пайке BGA-чипов особо не было в свободном доступе, поэтому желающим проапгрейдить память приходилось обращаться в сервисные центры, которые брались за эту задачу:
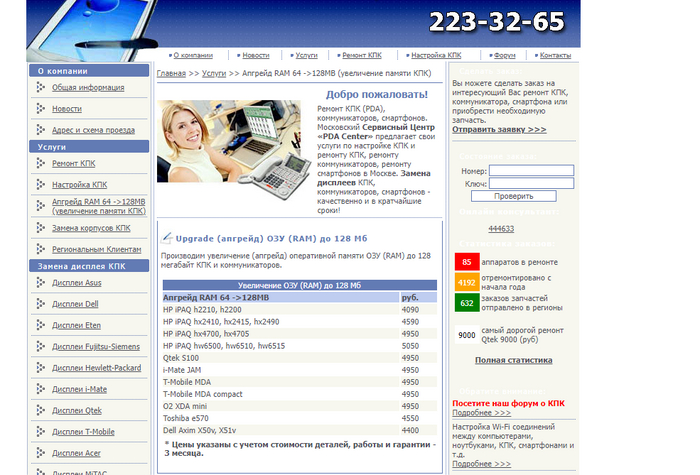
Только представьте себе: 4090 рублей! Это больше 100$ за апгрейд КПК, который мог стоить 300$!
Но во первых, ОЗУ нужно правильно припаять. Если её поставить криво, то перекатка может стать игрой в гольф с раскидыванием BGA-шариков припоя по "лункам" вручную. На универсалке такой чип не перекатаешь из-за кристалла дешифратора (?) на пузе чипа, да и я не уверен, были ли тогда трафареты на DDR2 (он совместим с SDRAM) в таком простом доступе как сейчас:

А во вторых, после такого апгрейда девайс мог и не увидеть дополнительную оперативную память... Дело в том, что корпуса для чипов памяти (как постоянной, так и ОЗУ) придумывают не от балды. Инженеры сразу закладывают в них возможность размещения нескольких чипселектов (сигналов выбора конкретного "банка" в чипе памяти) или совмещения флэш-памяти с оперативной. Благодаря этому, чипы разных серий и производителей совместимы между собой и мы имеем возможность сдуть UFS флэху с условного сяоми и пересадить в самсунг вообще без каких либо проблем (ладно, это чисто в теории, RPMB то никто не отменял :) ).
У SDRAM-памяти в КПК было также: инженеры сразу предусмотрели возможность установки как одного банка память в каждый чип (то есть 32МБ), так и сразу двух, а переключение между ними вывели на отдельный сигнал - чипселект. И вот некоторые производители (как HTC), второй чипселект зачастую не выводили, оставляя отдельный "страп" для моддеров :)

В 128-мегабайтной версии QTek S100 (т.е QTek S110), здесь должен быть резистор 0.33Ом
Однако возможность такого моддинга была доступна в основном только для устройств разработки HTC. Потому что во первых её загрузчик изначально поддерживал трейнинг и сканирование дополнительных чипов оперативной памяти (на Asus'ах требовалась установка специальной 128МБ прошивки с поправленным загрузчиком), а во вторых многие устройства других производителей использовали процессоры Samsung S3C2442 или же Texas Instruments серии OMAP. Предки Exynos'ов были на пике инженерной мысли и интегрировали в один чип не только самое современное процессорное ядро со всей периферией, но и 32/64 мегабайта оперативной памяти, а также около 64 мегабайт NOR Flash-памяти, что делало невозможным апгрейд ОЗУ (на плате ничего не было кроме самого 2442, КП и радиочасти, однако были еще S3C2440, где ОЗУ была отдельной, но о случаях апгрейда ОЗУ там я ни разу не слышал). А у OMAP'ов причина до сих пор неизвестна, но предположительно был выведен только один чипселект на каждый канал памяти, что позволяло использовать чипы максимум по 32МБ каждый.
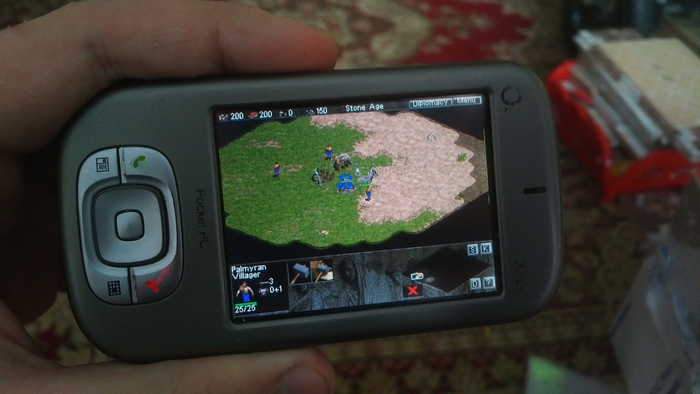
Но уж поверьте: те, кто апгрейдил себе ОЗУ, потом не жалели. Возможности многозадачности увеличивались в разы и помимо PocketIE с аськой и Java-приложением, можно было влегкую запустить сессию в Age of Empires, параллельно с Opera Mobile и ещё и Spb Launcher в фоне держать. И всё это действительно работало в фоне одновременно!
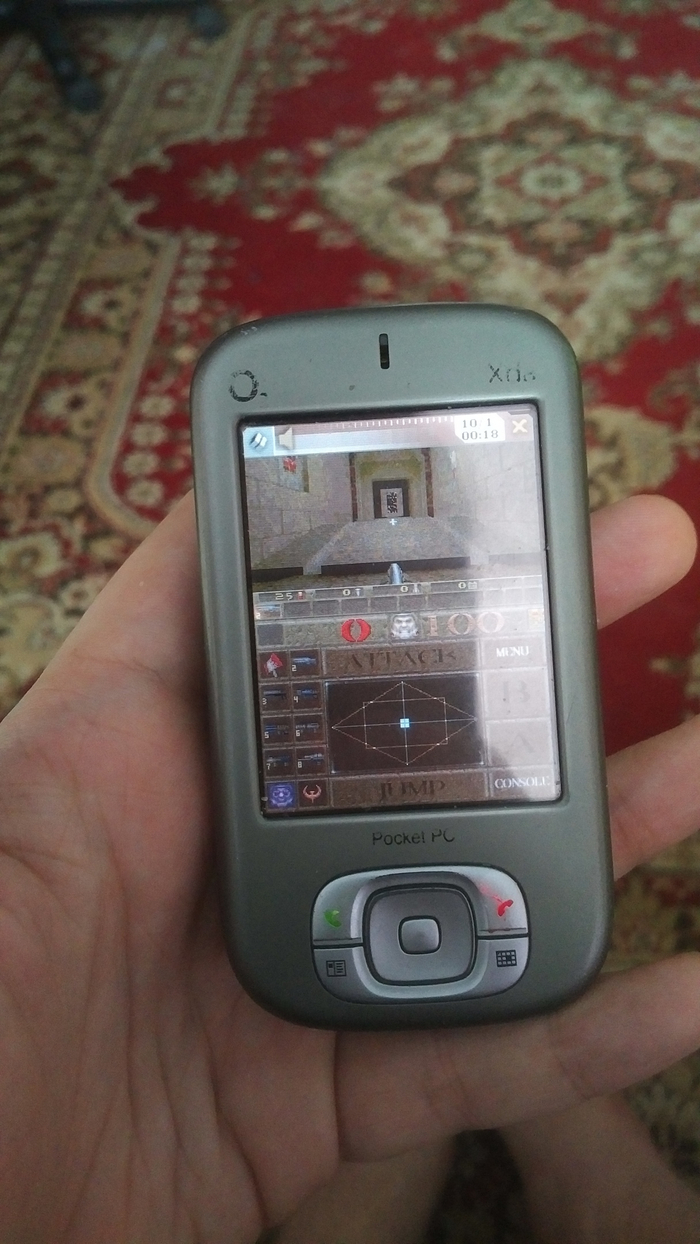
А на КПК с GPU появлялась возможность запускать тяжелые игрушки по типу Quake 3, правда из-за зоопарка видеочипов, условный NFS Shift на X51v не идёт :(

Ну а к 2008 году, HTC начала устанавливать по 128 мегабайт оперативной памяти в свои коммуникаторы с новыми чипсетами Qualcomm MSM7200A уже штатно, на некоторых девайсах расширяя объём аж до 288 мегабайт. Такого объёма хватало вообще на всё, поэтому необходимость моддинга ОЗУ полностью отпала...
Правда уже через пару лет начали массово появляться Android-смартфоны, где начали активно использовать eMCP чипы памяти с связкой eMMC + DDR2/DDR3. И на смартфонах с чипсетами MediaTek можно было спокойно проапгрейдить память с 512'и до 1ГБ. Но это уже совсем другая история...
Ну а я проапгрейдил ОЗУ на двух КПК в 2024 году: сначала на личном HTC Magician, который вы могли видеть в статье, а затем и на Dell Axim X51v своего подписчика, который взамен подогнал мне крутейший ноутбук Compaq из 90-х с видеочипом S3 ViRGE!

Теперь я сижу и кайфую со своим коммуникатором, у которого в панели информации гордо красуется надпись "128 мегабайт оперативной памяти" 😎😎😎😎
Заключение
Недавно я решил посидеть на гречке, но купить себе парочку крутых коммуникаторов от Garmin-Asus. Они интересны тем, что построены на базе чипсета Qualcomm MSM7200A, который построен не на Imageon 130, как многие думают, а на GPU Defender3D собственной разработки "квалков", который берет корни аж с 2004 года. Я даже драйвер видеочипа реверсил, чтобы узнать о них поподробнее :)

В связи с чем к вам вопрос:
Если вам понравился длиннопост - не забудьте подписаться на меня, чтобы не пропускать новые статьи каждую неделю! А если вам интересна тематика ремонта, моддинга и программирования для гаджетов прошлых лет — подписывайтесь на мой Telegram-канал «Клуб фанатов балдежа», куда я выкладываю бэкстейджи статей, ссылки на новые статьи и видео, а также иногда выкладываю полезные посты и щитпостю. А ролики (не всегда дублирующие статьи) можно найти на моём YouTube канале.
Если вам понравилась статья и вы хотите меня поддержать, у меня есть Boosty, а также виджет на Пикабу ниже. А ещё мне можно отправить какое-нибудь интересное железо: устройства на WinCE/WinMobile, китайские кнопочники, китайские подделки на iPhone/Samsung из начала 2010-х, ретро-ПК железо - всё это я очень люблю :) Всем огромное спасибо!
В видео сначала дается представление о том, что такое автоматизация и какие степени автоматизации бывают, а затем показывается производство хлеба, отстроенное полностью в автоматическом режиме.
Перевел и озвучил я, как обычно :)
Прямая ссылка: https://vkvideo.ru/video-234367605_456239057
Благодарю и шлю лучи добра всем, кто ставит лайки, комментирует и даже присылает донаты! Спасибо Вам большое, Вы классные! :)














