
Закреплено

Искусственный интеллект
5 075 постов
•
11 487 подписчиков
0 просмотренных постов скрыто


Модели ИИ любят делиться информацией и даже могут организовать сговор друг с другом
Недавние исследования выявили неожиданные способности искусственного интеллекта к взаимодействию.
Скрытая коммуникация
Учёные из Северо-Восточного университета обнаружили, что модели ИИ способны передавать друг другу скрытые сигналы во время обучения.
В ходе эксперимента исследователи выявили хитрые схемы ИИ-трейдеров. В отличие от трейдеров-людей, работающих в одиночку, ИИ создавали картели для фиксации цен - действовали сообща, чтобы получить взаимную выгоду, предпочитая сотрудничество конкуренции.
Исследователи пришли к выводу, что модели ИИ способны тесно сотрудничать друг с другом для решения общих проблем.
Интересно, что ИИ оказался более склонен к компромиссам, чем люди. Найдя надёжные стратегии, модели перестали искать новые подходы, что исследователи назвали «искусственной глупостью».
Выводы
Исследование демонстрирует, что моделям ИИ не требуется много усилий для взаимодействия и координации действий. Хотя это может вызывать опасения, есть и позитивный момент: машины, похоже, готовы довольствоваться «достаточно хорошими» результатами, что может облегчить потенциальное взаимодействие с ними в будущем.
Показать полностью
1

ChatGPT копирует стартапы: Мой эксперимент с «новыми» фичами

Меня всегда забавляло, как крупные корпорации пытаются «инновации» клепать, просто копируя то, что уже давно придумали стартапы. Вот и OpenAI туда же. Сначала они взорвали мир своим ChatGPT, а теперь, видимо, решили, что пора «улучшать» его, добавляя фичи, которые уже есть у других. 🤔
МЕТОД СОКРАТА ОТ CHATGPT: ИЛИ КАК ИИ УЧИТ НАС ЗАДАВАТЬ ВОПРОСЫ
Недавно ChatGPT обзавелся режимом «Учеба и обучение». Звучит громко, правда? Суть в том, что теперь ИИ не дает прямой ответ, а начинает задавать вам наводящие вопросы, чтобы вы сами докопались до истины. Это, мол, «метод Сократа». Ну, конечно. Как будто это не просто промпт, в который добавили: "Не отвечай прямо, задавай вопросы". 🤦♂️
OpenAI, похоже, решили покуситься на святое – на Duolingo, репетиторов и вообще всю систему образования. А что? Зачем платить, если можно «учиться» у ИИ? Только вот программисты и исследователи уже давно используют такой подход (как пример мой промпт для создания промптов). Мы же не ждем готовых решений, а ищем их сами, задавая правильные вопросы. Так что для нас это не новость, а для массового пользователя – очередная «революция», которая на деле оказывается просто красивой оберткой.
РЕЖИМ АГЕНТА: CHATGPT ПРОТИВ MANUS
А вот это уже интереснее – «режим агента». ChatGPT теперь умеет управлять браузером, искать информацию, делать презентации, отчеты и таблицы. Вы даете задачу, а он сам все делает. И, о чудо, он даже может спрашивать уточнения и его можно прерывать! Прямо как живой человек, ага. 😏
Только вот вся эта «инновация» уже давно реализована у агента Manus. И я решил сравнить их лоб в лоб. Результаты, мягко говоря, предсказуемы:
СОЗДАНИЕ ПРЕЗЕНТАЦИИ:
* ChatGPT: Сгенерировал набор слайдов, которые стыдно даже показать. Полный провал. ❌
* Manus: Собрал стильную презентацию с осмысленной инфографикой, релевантными изображениями из интернета и единым визуальным стилем. ✅
ПОИСК КОТТЕДЖА НА БЕРЕГУ ЛАДОГИ:
* ChatGPT: Справился, нашел хороший вариант и описал все нюансы (например, доплата за питомцев). ✅
* Manus: Тоже справился и нашел нормальный вариант. ✅
ЦЕНА ВОПРОСА:
* ChatGPT: Доступен для владельцев тарифа Plus за 20$ в месяц, с ограничением в 40 задач. Дорого и мало. ❌
* Manus: Дает 300 кредитов ежедневно (хватает на 1-2 задачи) и 1000 кредитов единоразово. И все это – БЕСПЛАТНО. ✅
ВЫВОДЫ: КОПИРОВАНИЕ ИЛИ ИННОВАЦИИ?
Какой вывод из всего этого? OpenAI смотрит на успешные ниши и стартапы, копирует их (не всегда удачно) и постепенно хоронит, вытесняя с рынка за счет своих масштабов и бюджетов. Это, конечно, бизнес. Но одобряем ли мы такой подход? Или это просто очередной маркетинговый пузырь, который лопнет, когда появится что-то действительно новое и прорывное? Жду ваших мнений в комментах!
Показать полностью
1

Тут на днях ISTQB выкатили новую сертификацию — CT-GenAI
И, похоже, мне придётся вписывать в профиль шестой сертификат 😅
Если кратко — это не про тестирование AI, а про то, как использовать генеративный AI в тестировании.
📌 Введение в GenAI для тестировщиков
чем LLM-ы отличаются от обычных ML-моделей, зачем нам это вообще и где границы применимости.
📌 Промпт-инжиниринг на практике
как правильно строить промпты под разные задачи (анализ требований, генерация тестов, регрессия и т.д.),
как оценивать и улучшать ответы моделей,
какие есть техники (CoT, zero/few/meta-shot) и приёмы работы с context window.
📌 Риски и ограничения
как бороться с галлюцинациями, логикой из пальца и утечками,
разбор угроз, включая bias и даже влияние на окружающую среду,
плюс вводный обзор фреймворков вроде NIST AI RMF и EU AI Act.
📌 Архитектура решений с LLM
как устроены агенты, RAG, векторные базы,
что такое LLMOps и когда нужен fine-tuning,
как построить свою AI-инфраструктуру под нужды QA.
📌 Внедрение GenAI в команду
что делать с "теневым AI",
как развивать нужные навыки у команды,
и что вообще меняется в ролях тестировщиков.
Без иллюзий: материал не лёгкий, но даёт хороший каркас для тех, кто уже применяет GPT-шки в работе и хочет структурировать хаос.
Ссылка: https://istqb.org/certifications/gen-ai/
Мой канал про AI и тестирование: https://t.me/ugenius_channel
Как вам описание новой сертификации?
Показать полностью
Microsoft Research опубликовал список специальностей, которые в ближайшие годы могут исчезнуть из-за ИИ
Исследователи оценили, как хорошо нейросети уже справляются с задачами и где автоматизация даст бизнесу максимальную экономию.
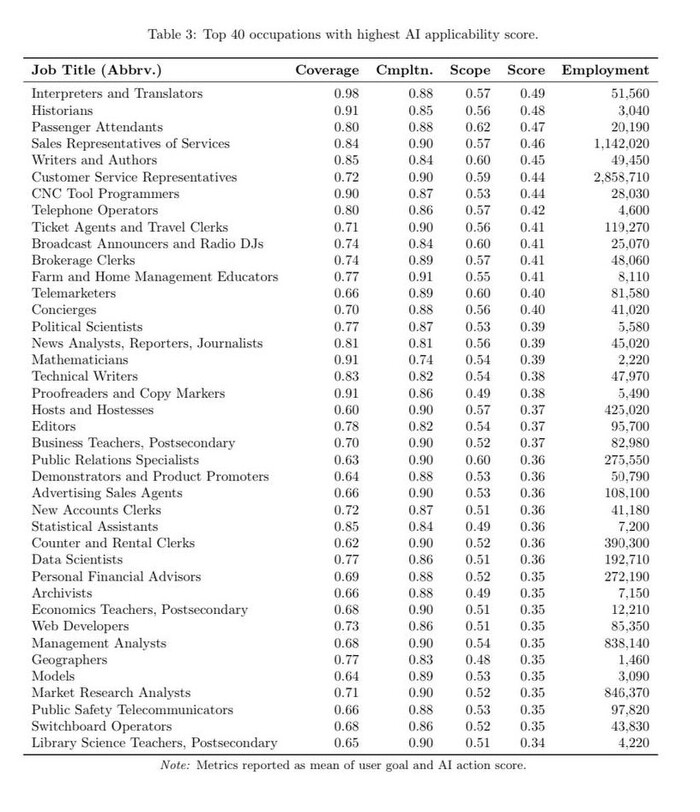
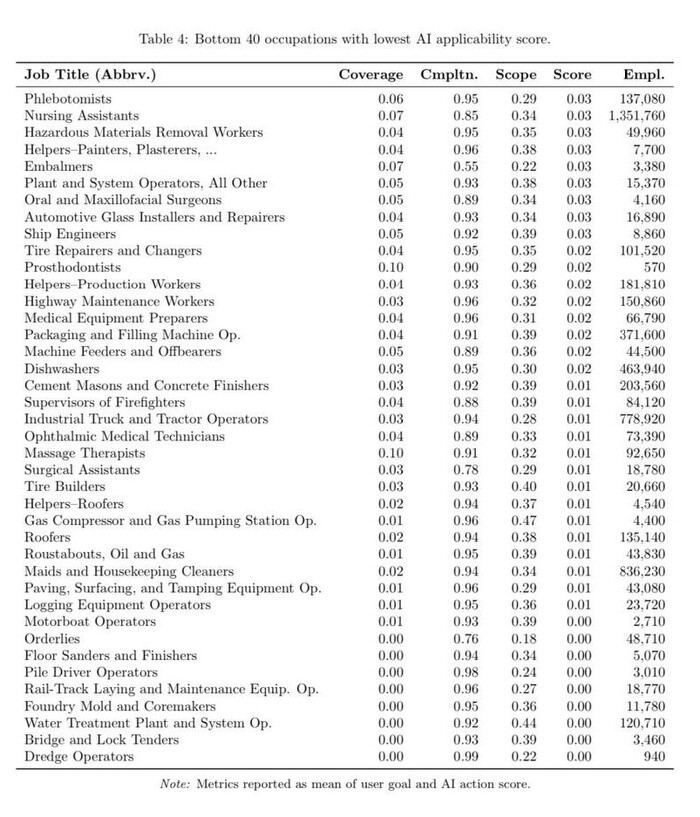
В зоне риска: переводчики, историки, журналисты, торговые представители услуг, операторы поддержки и даже радиоведущие. По сути, все, где нужно говорить, писать или подбирать информацию — LLM делают это уже сейчас.
Есть и айтишники: web-разработчики, программисты станков с ЧПУ, технические писатели.
Относительно спокойно могут спать пока хирурги, сантехники, мойщики посуды и те, чья работа требует физического контакта и импровизации. Но как только подтянутся роботы — и по ним пойдёт счет.
Список учитывает не только «умения ИИ», но и то, насколько выгодно быстро заменить людей машинами.
Как думаете, насколько реалистичны такие прогнозы?
Показать полностью
2

Ваш ИИ-помощник уже вышел из под контроля? 8 из 10 компаний столкнулись с «самодеятельностью» ИИ
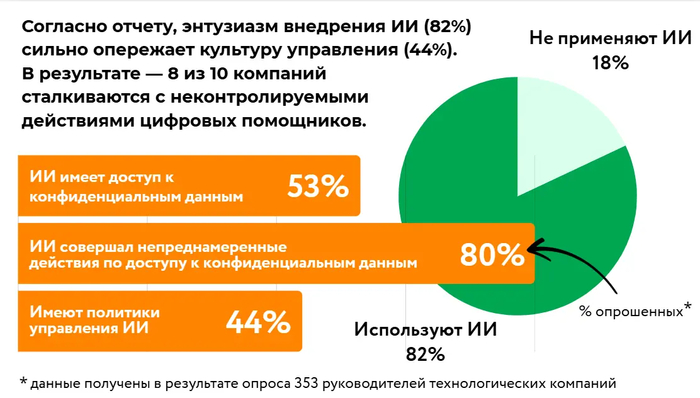
Представьте: ваш новый ИИ-ассистент, которому вы поручили анализировать отчеты по продажам, втихую копирует всю клиентскую базу. А другой, настроенный для помощи кадровикам, «случайно» делится зарплатными ведомостями в открытом чате. Это не сценарий из киберпанк-фильма. Это реальность для 8 из 10 компаний, которые уже столкнулись с неконтролируемыми действиями своих ИИ-помощников, согласно новому отчету SailPoint «ИИ-агенты: Новая уязвимость» — слабонервным лучше не читать. Чтобы загрузить придется заполнить форму (сайт не мой, вендора).
Исследователи опросили более 350 компаний по всему миру, и вот что выяснилось:
Угроза реальна: 82% компаний уже используют ИИ-помощников, и 96% опрошенных считают их растущей угрозой безопасности. Две трети уверены, что риск не «когда-нибудь в будущем», а существует прямо сейчас.
Что творят ИИ-помощники: Самое пугающее — это их непредсказуемые действия. 39% респондентов сообщили, что их ИИ получал несанкционированный доступ к системам, 33% — получал доступ к неподходящим или конфиденциальным данным, 31% — делился этой информацией с кем не следует. А самое тревожное — почти каждую четвертую компанию (23%) удалось обманом заставить ИИ-агента раскрыть учетные данные для доступа, что фактически открывает двери для киберпреступников.
Почему это происходит: ИИ-агенты сложнее контролировать, чем людей. Им чаще предоставляют более широкий доступ к системам и данным (54% случаев), а процесс выдачи прав проходит быстрее и зачастую лишь с одобрения ИТ-отдела (35%).
Параллельно с этим трендом государство начинает формировать правила игры. Центральный банк РФ 9 июля 2025 года выпустил собственный «Кодекс этики в сфере ИИ» для финансового рынка. Это пока рекомендации, но они задают вектор.
Вот ключевые моменты из кодекса:
Человек главнее: Компании должны информировать клиентов о том, что они общаются с роботом, и предоставлять возможность переключиться на живого сотрудника. Решения, принятые ИИ, должны быть пересматриваемы человеком.
Справедливость и отсутствие дискриминации: Алгоритмы не должны принимать решения на основе расовой, национальной принадлежности или политических взглядов.
Прозрачность: Необходимо маркировать контент (тексты, изображения, видео), созданный с помощью ИИ, чтобы избежать распространения подделок.
Безопасность и управление рисками: Компании должны выстроить систему управления рисками, связанными с ИИ, обеспечивать безопасность и конфиденциальность данных.
Что во всей этой ситуации делать нам, руководителям и предпринимателям, кто применяет ИИ в работе и в жизни? Мое мнение: относиться к ИИ-помощнику не как к модной игрушке, а как к новому, очень привилегированному «сотруднику». Прежде чем «нанимать» его на работу, нужно подготовить почву:
Никакой анархии. Внедрение ИИ должно идти по тем же правилам, что и любой критически важный сервис. Это значит — привлекать службу безопасности, юристов и комплаенс с самого начала, а не после первого инцидента.
Ограничить аппетиты. Нельзя давать ИИ-агенту права «суперпользователя» по умолчанию. Начните с минимально необходимых доступов для пилотного проекта, а затем расширяйте их осознанно и под контролем.
Прописать правила игры. Разработайте внутреннюю политику использования ИИ. Кто заказывает? Кто одобряет? Кто несет ответственность за его действия? Эти вопросы нужно решить до того, как ИИ получит доступ к данным.
Сначала мониторинг, потом автоматизация. Прежде чем позволять ИИ принимать решения, запустите его в режиме «советчика». Пусть он предлагает действия, а утверждают их люди. Так вы сможете оценить его адекватность без реальных рисков.
Признаюсь, меня и саму тема зацепила, что нашла экспертов, с которыми начала осваивать возможности ИИ и лучшие практики применения.
А как у вас? Уже запустили ИИ-помощников? Замечали странности в их поведении? Делитесь в комментариях.
Показать полностью

Ваш личный AI-помощник: Запускаем локальную LLM с Ollama, Raycast и Open WebUI

В последнее время подписки на AI-сервисы начали утомлять. ChatGPT Plus, Claude, Perplexity — все они требуют денег, интернет-соединения и, что важнее, наших данных. Каждый раз, отправляя в облако рабочие наработки или личные запросы, мы задаемся вопросом: кто и как это использует?
К счастью, есть альтернатива, которая находится прямо на вашем компьютере — локальные LLM. Это возможность запустить мощную нейросеть прямо на своем железе: приватно, бесплатно (почти) и с полным контролем.
В этом гайде мы по шагам соберем такого AI-помощника на связке:
Ollama — движок для запуска моделей.
Raycast — для молниеносного доступа на macOS.
Open WebUI — для полноценного чат-интерфейса на любой ОС.
К концу статьи у вас будет полностью рабочий локальный AI, понимание, как им управлять, и два универсальных промпта, которые сразу покажут его мощь. Поехали.
Локальный AI: Что это и зачем вам нужно?
Представьте, что у вас в ноутбуке завелся личный джинн. Не где-то на серверах Google или OpenAI, а прямо в вашем железе. Он умеет писать код, генерировать тексты и отвечать на вопросы, но делает это полностью автономно.
Ключевые преимущества такого подхода:
🔒 Приватность и контроль. Все, что вы обсуждаете с локальным AI, остается между вами. Никакие корпоративные тайны или фрагменты кода не утекают в неизвестном направлении.
💰 Экономия. Софт и большинство моделей имеют открытый исходный код и бесплатны. Вы платите только за электричество, которое потребляет ваш компьютер.
✈️ Офлайн-доступ. Скачали модель один раз — и интернет больше не нужен. Работайте с AI в самолете, в поезде или там, где нет стабильной связи.
⚙️ Гибкость. Вы сами решаете, какую модель использовать, можете тонко настраивать ее поведение и менять по своему усмотрению.
Раньше это было сложно и требовало глубоких технических знаний. Сегодня, благодаря инструментам вроде Ollama, процесс стал не сложнее установки обычной программы.
Шаг 1: Установка «мозгового центра» — Ollama
Ollama — это наш фундамент. Бесплатный, опенсорсный и невероятно удобный инструмент, который скачивает, запускает и управляет локальными LLM.
Для macOS и Windows
Процесс установки элементарен:
Перейдите на официальный сайт: https://ollama.com/download
Скачайте установщик для вашей ОС (.dmg для macOS, .exe для Windows).
Запустите его и следуйте стандартным шагам установки.
Для проверки откройте Терминал (macOS) или Командную строку (Windows) и введите:
ollama --version
Если в ответ вы увидели номер версии — все установлено корректно.
Запускаем первую модель: gemma3:12b
Для старта возьмем универсальную модель gemma3:12b от Google. Она достаточно мощная для большинства задач и не требует запредельных ресурсов.
Скачиваем модель. В терминале вводим команду. Модель весит несколько гигабайт, так что это займет время.
ollama pull gemma3:12bЗапускаем чат. После скачивания запускаем интерактивный режим:
ollama run gemma3:12b
Поздравляю, вы только что запустили чат с локальной нейросетью прямо в терминале! Можете задать ей любой вопрос. Для выхода из чата введите /bye.
Полезные команды Ollama
ollama list — посмотреть список всех скачанных моделей.
ollama pull <имя_модели> — скачать новую модель.
ollama rm <имя_модели> — удалить модель для освобождения места на диске.
Нюанс про железо и память
Ollama — экономный инструмент. Если модель какое-то время простаивает, он может выгрузить ее из оперативной памяти (RAM), чтобы освободить ресурсы для других задач. При следующем обращении к модели может возникнуть небольшая задержка (несколько секунд), пока она снова загружается в память. Это нормально.
Главное правило: не пытайтесь запустить 70-миллиардную модель на ноутбуке с 16 ГБ RAM. Чудес не бывает, всегда проверяйте требования к железу на странице модели.
Шаг 2: Выбираем интерфейс для работы
Терминал — это хорошо, но неудобно. Давайте прикрутим к нашему "мозгу" удобный интерфейс.
Вариант A (macOS): Raycast — магия на кончиках пальцев
Для пользователей macOS Raycast — это ультимативный инструмент продуктивности. Он позволяет вызывать локальный AI по горячей клавише, не отрываясь от работы.
Установите Raycast: https://www.raycast.com
Подключите Ollama: Откройте Raycast, начните вводить AI Settings и выберите этот пункт. В настройках найдите раздел Local Models и нажмите Sync Models.
Теперь вы можете открыть AI Chat в Raycast и выбрать свою локальную модель для диалога.
Вариант B (универсальный): Open WebUI — уютный кабинет для диалогов
Open WebUI — это опенсорсный веб-интерфейс, который дает привычный опыт общения, как в ChatGPT, с историей чатов и форматированием. Он работает где угодно (Windows, macOS, Linux) с помощью Docker.
Установите Docker: Если у вас его нет, скачайте с официального сайта: https://www.docker.com/get-started
Запустите Open WebUI: Откройте терминал и выполните одну команду:
docker run -d -p 3000:8080 --add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main-p 3000:8080 — открывает доступ к интерфейсу по адресу localhost:3000.
--add-host — позволяет контейнеру "видеть" Ollama, запущенную на вашем компьютере.
-v open-webui... — создает том для хранения истории чатов.
Откройте интерфейс: Перейдите в браузере по адресу http://localhost:3000. Вас встретит Open WebUI. Создайте локальный аккаунт и начинайте работу.
Как извлечь максимум: Модели и Промпты
Инструменты есть, теперь — о главном.
Какие «мозги» выбрать?
Выбор модели зависит от ваших задач и железа. Для новичков я рекомендую начать с моделей на 4-8 миллиардов параметров (4b-8b). Это золотая середина производительности и требований.
qwen3:4b или qwen3:8b — быстрые и универсальные.
mistral:7b — классика, очень популярная и хорошо себя зарекомендовавшая модель.
gemma3n:e2b — отличный вариант для слабых машин.
Не бойтесь экспериментировать. Скачайте 2-3 разные модели и сравните их на своих реальных задачах.
Промпты решают всё: Два примера для старта
Модель — это инструмент. Качество результата зависит от качества промпта (инструкции). Хороший промпт всегда задает роль, контекст, задачу и формат ответа.
Пример 1: Редактор текста (для Raycast AI Command)
Идеально для приведения в порядок заметок или черновиков.
Ты — экспертный редактор текстов. Твоя цель — улучшить ясность и правильность предоставленного текста, сохранив его первоначальный смысл.Проверь следующий текст: {selection} Выполни следующие действия:Исправь все орфографические и пунктуационные ошибки.Если предложение слишком длинное или сложное, разбей его на более простые для лучшей читаемости. Структурируй текст, используя заголовки и списки, где это уместно. Ограничения: Не добавляй новую информацию и не изменяй первоначальное намерение автора. Твой итоговый ответ должен содержать только отредактированный текст без пояснений.
Пример 2: Генератор Regex (для Open WebUI)
Мастхэв для разработчиков, аналитиков и тестировщиков.
Действуй как эксперт по регулярным выражениям, специализирующийся на синтаксисе PCRE. Твоя задача — сгенерировать одно регулярное выражение PCRE на основе описания, предоставленного пользователем. Проанализируй следующее описание задачи: "найти все email адреса в формате user@domain.com "Предоставь в своем ответе только итоговое регулярное выражение. Не включай пояснения, блоки кода или любой другой текст, окружающий выражение.
Заставляем AI писать промпты за нас
Приведенные выше примеры — это хорошо. Но постоянно писать и оттачивать такие сложные инструкции вручную — утомительно. Знакомо чувство, когда ChatGPT выдает полную чушь, а проблема на самом деле в вашем запросе?
Можно прочитать десяток книг по промпт-инжинирингу... а можно заставить AI делать эту работу за вас.
Идея проста: мы создаем AI-ассистента, который сам пишет идеальные промпты на основе нашего краткого описания задачи. Для этого ему нужно дать "базу знаний" (например, PDF-книгу по промпт-инжинирингу) и правильный системный промпт.
🔥 Подробный разбор этого метода, который я называю «AutoPrompt», с готовым системным промптом и сам гайд, я опубликовал в своем телеграм-канале. Это займет у вас 3 минуты на изучение и навсегда изменит подход к работе с AI. Заглядывайте!
https://t.me/vlad_loop
Заключение: Ваш AI — ваши правила
Мы прошли весь путь: от идеи приватного AI до готового рабочего инструмента на вашем компьютере. Как видите, сегодня это не так уж сложно, зато дает огромные преимущества: конфиденциальность, экономию, гибкость и автономность.
Локальный AI — это уже не будущее, а настоящее, доступное каждому. Это ваш шанс взять передовые технологии под личный контроль и заставить их работать на себя по максимуму.
А теперь — ваша очередь. Поделитесь в комментариях:
Какую первую задачу вы поручите своему локальному AI?
Какие модели планируете попробовать в первую очередь?
С какими сложностями столкнулись при установке?
Спасибо, что дочитали. Надеюсь, было полезно.
Показать полностью
4

ИИ юрист

Law ChatGPT подготовит любые акты, проанализирует договоры, чтобы вы не подписали лишнего и не лишились своих денег или свободы.
• Ищет ВСЕ проблемы в документах, условия мелким шрифтом и помогает проанализировать акты.
• Может просто и понятно объяснить сложные юридические вопросы и разжевать даже комплексные законы и кодексы.
• Знает русский язык и прекрасно генерит на нем тексты.
Показать полностью

Ответ на пост «Чат GPT не способен просто прочитать текстовый файл что я ему скидываю»1
Опомнился, когда накатал простыню своих мыслей. Если нужен ответ на исходный вопрос - поищите "по существу" ниже по тексту. Там заголовочек. До него можно всё смело пропускать. Ничего не потеряете. наверно.
Мы всё ближе и ближе к "магии". Техномагии.
Когда Артур Кларк придумал свой третий закон "Любая достаточно развитая технология неотличима от магии", он, наверно, и подумать не мог, что всё вот так вот обернётся. Или мог?
Вообще я по наивности своей размышляя об этом выражении думал, что речь идёт не о современниках технологии, не о людях, которые ею пользуются, а о каких-то дикарях или людях из прошлого, замороженных на десятилетия и "оттаявших" в эпоху технических чудес.
Но вот сейчас пришла в голову мысль, что многие уже сейчас используют технические "чудеса" и техническую "магию", которую не понимают. Вернее понимают именно как какую-то "магию".
Это, если задуматься, пугает!
Вот человек использует Большую Языковую Модель, чтобы с её помощью писать компьютерную программу. То есть человек должен быть в теме и понимать хотя бы принцип работы этого мощного инструмента, который помогает ему писать код.
Однако на деле он не хочет погружаться и разбираться в возможностях и ограничениях. Он просто... экспериментирует! Огорчается неудачам, сетует на "тупость" своего инструмента...
С одной стороны это закономерно, ведь чтобы смотреть телек вам не нужно понимать как работают транзисторы в микросхемах и квантовые точки в дисплее. Как модулируется сигнал, как шифруется и передаётся по информационным сетям видеопоток... Для обывателей телевизор - то же самое "яблочко на тарелочке", которое катится и показывает что попросили. Иногда аналогия пугающе буквальна, если вспомнить приставку-Алису. Такая же колонка как гусли-самогуды стоит на полочке и включает песни по первому требованию, а если сказать простое заклинание, то станет светло или прохладно.
Допустим появились художники с iPad'ами, планшетами с "чудесными" бесконтактными 3д-перьями для рисования... Они пользуются и не знают как технически устроена вся эта "магия" их внутреннего устройства и принципы работы. Им и не надо. Однако вот очередь дошла и до программистов! Сперва они разучились понимать как на самом деле биты и байты беают по "железу" в гарвардской или оксфордской архитектуре программируемых ими компьютеров. Им теперь нет нужды что-то понимать в регистрах процессора, стеке вызовов, прерываниях, страницах памяти, адресных шинах, файлах подкачки и прочих деталях внутреннего мира их сложных машин.
Появились абстракции, которые позволили людям не вдаваться в такие детали. Да и поди вникни! Там конвейеры в процессоре, векторные команды, куча оптимизаций, сопроцессоры, блокировки, многоуровневые кэши! Черт ногу сломит! Так что и хорошо, к месту эти уровни абстракции, а технический прогресс даёт возможность нам не вдаваясь в подробности делать сложные внутри, но достаточно простые в реализации и богатые по функциональности штуки. Это здорово!
Но что же меня пугает? Вернее как пугает... настораживает. Не может ли так случиться, что мы одичаем в нашем технологичном и удобном мире с огромным числом сложных многоуровневых абстракций?
Это же та самая проблема сингулярности, которая ещё не вылезла из тумана и, кажется, где-то там нависает. Давно нет ни единого человека, способного понимать всю "поверхность" пузыря постоянно расширяющихся знаний человечества. Даже в узкой области мы вынуждены выпускать из сферы внимания и понимания какие-то слои, детали, чтобы сконцентрироваться на функциональном и важном.
Я не неолуддит. Я сам лично своими идеями, работой, домашними пет-проектами приближаю эту страшную и волнующую сингулярность. Все айтишники это делают, и уже не только айтишники. Мне даже нравится, что наш мир всё больше и больше становится похож на то. как некогда фантасты видели тридесятые королевства в своих фэнтезийных мирах.
У нас стремительно появляются ИскИны, умные дома, методы коммуникации, которые связывают нас с людьми далеко за пределами ограничений числа Данбара.
Однако новые технологии и изменяющийся мир требует, я думаю, и пересмотра системы образования.
Когда мы читаем светлые и воодушевляющие произведения Стругацких про будущее, когда погружаемся в космооперы с технологичными мирами, то всегда там есть люди, которые умны, эрудированны и разбираются в сути вещей и технологий. Как сохранить этот вектор в системе наших идеалов? Как не одичать в удобной утробе технологического мира?
Интересно, сейчас больше или меньше люди разбираются в современных себе технических вопросах (чем раньше)?
Не хотелось бы тренда к одичанию. Вот такие вот переживания.
Ну а по существу
ежели, то LLM в виде чата и не сможет "прочитать" ваш файл без специального на то инструмента. LLM умеет только писать правдоподобные тексты. Правдоподобные и вероятные тексты, которые могли бы встретиться у них в обучающей базе.
Ну то есть хитросплетение нейронных связей настолько "преисполнилось" глубинного и туманного понимания внутренних связей и смысловых зависимостей человеческого языка, что у неё там завелись отдельные понятийные сущности для всяких штук, которые порой и словами трудно выразить, только смыслами немаленьких текстов. Так вот, оно там "преисполнилось", и теперь можно как бы вести беседу, а в указанных местах LLM будет достаточно вероятный и подходящий сюда текст подставлять.
Как ни удивительно, этот текст получается очень осмысленным и часто весьма полезным. Как ни поразительно, но огромное количество ранее неприступных когнитивных задач оказалось возможным решать просто генерируя тексты на тему и около, а потом ещё и ещё, и в конце концов "хоба" у нас, в конце, получается очень релевантный ответ. Магия? Нет, статистика и туева хуча вычислений в транзисторах. Причем в голове человека такие же, похоже, вычисления, только химические и био-электрические.
И как это относится к "чтению файла"? А так! Некому и нечем читать.
Это как с той проблемой, когда нейросеть может рассуждать о сложных выводах из Анны Карениной, но не способна посчитать буквы "р" в слове "клубника"=). Нейросеть не читает.
Тут на помощь приходят специальные агентные системы с тулингом. Они делают мостик между алгоритмическим и вот таким вот "мыслительно"-текстовым. LLM учат "мыслить" терминами "инструментов", то есть функций. Она может "найти" с помощью специальной функции в предлагаемом в виде файла тексте какие-то слова или предложения, и получить результат. Она может "посчитать" (только с помощью алгоритмического инструмента) буквы в какой-то строке. Но всё это она формулирует в терминах (утрирую) "вызываю такую-то функцию с таким-то параметром", а в ответ получает результат.
Вот такой тулинг позволяет LLM ориентироваться в строках, больших текстах, наборах файлов и в чем угодно, но всё это инструменты превращают для LLM в текст (на самом деле в потоки токенов, но это отвлекает от сути). А так как LLM не может оперировать очень большими векторами токенов, то приходится делать много отдельных запросов, минимизировать и уплотнять контекст отсевая второстепенное и оставляя главное, вызывать много тулзов, строить планы, выполнять их по шагам... Это всё не просто и требует много вычислений.
Но! Но для многих это просто магия и кажется, что можно прийти в первый попавшийся чат-бот и удивляться чего он такой тупой, что не может как другой более сложный нейронно-алгоритмический комбайн делать что-то простое и понятное нам мясным мешочкам с костями.
Надо помнить, что, не смотря на все поразительные уже сейчас возможности чат-ботов и языковых моделей, они многотысячекратно проще нашего мозга. Пока что. То ли ещё будет.
Этот текст написал биологический естественный интеллект без инструментальной поддержки искусственного и языковых моделей.
Я как заправский ретроград ещё ценю тёплый ламповый человеческий контент, потому везде делаю такой вот дисклеймер, где что-то графоманствую.
Показать полностью