

Технолоджия

Показать полностью
1

В этой статье: детальный технический обзор Gemini 3 Flash от Google: архитектура модели, результаты всех ключевых бенчмарков, сравнение с GPT-4, Claude и другими моделями, реальные кейсы использования и оценка эффективности.
История развития семейства Gemini началась в декабре 2023 года, когда Google представила первое поколение моделей, заявив о намерении составить конкуренцию GPT-4 и другим флагманским нейросетям. Линейка сразу включала несколько версий: Ultra для максимально сложных задач, Pro для универсального применения и Nano для работы на устройствах. Gemini 1.5 принесла значительное увеличение контекстного окна и улучшенную мультимодальность, а серия 2.0 и 2.5 сфокусировалась на балансе между производительностью и стоимостью использования.
Однако до декабря 2025 года разработчики и компании сталкивались с классической дилеммой: либо выбирать мощные модели типа Pro с высоким качеством reasoning, но медленной скоростью и высокой ценой, либо довольствоваться быстрыми, но менее интеллектуальными облегчёнными версиями. Gemini 2.5 Flash, предшественник новой модели, работала быстрее Pro-версии, но заметно уступала в сложных задачах, особенно в программировании и глубоком анализе. Для production-систем, где критична и скорость ответа, и качество результата, приходилось идти на компромиссы.
16 декабря 2025 года Google анонсировала Gemini 3 Flash с революционным позиционированием: "frontier intelligence built for speed" — фронтир-интеллект, оптимизированный под скорость. Впервые в индустрии компания заявила, что им удалось создать модель, которая не просто быстрее предшественников, но и превосходит более тяжёлые версии по большинству бенчмарков. Gemini 3 Flash побеждает Gemini 2.5 Pro в 18 из 20 ключевых тестов, работает в три раза быстрее и при этом потребляет на 30% меньше токенов на типичных задачах.
Это стало возможным благодаря фундаментальным архитектурным изменениям: модель унаследовала reasoning-движок от Gemini 3 Pro, но получила серьёзные оптимизации на уровне инференса, механизм динамической адаптации глубины обработки и улучшенную эффективность работы с токенами. Результат — система, которая на простых запросах отвечает мгновенно, а на сложных автоматически задействует расширенные вычислительные ресурсы, сохраняя при этом экономичность.
В России доступ к новой мощной нейросети от Google ограничен, но уже сейчас есть возможность попробовать основные возможности Gemini 3 через сервис Study AI.
Почему Study AI?
1) Не нужен VPN
2) Есть бесплатный пробный тариф
3) Можно платить любыми российскими картами
4) Быстрая генерация
5) 40+ лучших нейронок в одном окне
Кому нужна Gemini 3 Flash? Модель проектировалась для максимально широкой аудитории: разработчики получили инструмент для агентного кодирования и автоматизации CI/CD, способный обрабатывать код быстрее, чем человек успевает его прочитать. Компании могут внедрять Flash в customer support, аналитику и контент-генерацию без опасений за качество ответов или задержки в обработке. Контент-мейкеры и маркетологи получают возможность генерировать тексты, анализировать изображения и работать с видео в реальном времени без переключения между разными инструментами. Исследователи и аналитики могут использовать модель для обработки больших объёмов данных с PhD-уровнем понимания контекста.
Google сразу сделала Gemini 3 Flash базовой моделью для своих продуктов: она заменила предыдущие версии в приложении Gemini, стала движком для AI Mode в поиске Google по всему миру и получила приоритетную интеграцию в Vertex AI и Google Cloud. Это означает, что миллионы пользователей уже взаимодействуют с новой моделью, даже не подозревая о смене технологии — настолько органичным оказался переход.
Появление Gemini 3 Flash сигнализирует о новом этапе развития индустрии: эра компромиссов между интеллектом и скоростью подходит к концу, и теперь пользователи могут рассчитывать на системы, которые одновременно умны, быстры и доступны по цене.
Gemini 3 Flash построена на фундаменте Gemini 3 Pro — флагманской модели Google, которая демонстрирует state-of-the-art результаты в сложнейших задачах reasoning и мультимодального понимания. Однако вместо простого уменьшения параметров или урезания возможностей, как это обычно делается в "облегчённых" версиях, инженеры Google применили комплекс архитектурных оптимизаций, которые сохраняют интеллект при радикальном ускорении работы.
Базовая архитектура наследует ключевые компоненты Pro-версии: трансформерный механизм внимания с расширенным контекстным окном, мультимодальные энкодеры для обработки текста, изображений, аудио и видео в едином пространстве представлений, а также reasoning-движок, способный разбивать сложные задачи на подзадачи и проверять логическую целостность ответов. Это объясняет, почему Flash показывает результаты, сопоставимые с Pro на самых сложных бенчмарках вроде GPQA Diamond (90,4%) и MMMU Pro (81,2%).
Оптимизации для скорости затрагивают несколько уровней. Во-первых, модель использует дистилляцию знаний от Gemini 3 Pro: вместо полного копирования архитектуры создаётся более эффективная структура, которая воспроизводит поведение учителя при меньших вычислительных затратах. Во-вторых, применяется квантизация и pruning — техники, позволяющие уменьшить размер модели и ускорить инференс без критической потери точности. В-третьих, Google оптимизировала схему распределения вычислений: модель динамически выбирает, какие слои активировать для конкретного запроса, избегая избыточных расчётов на простых задачах.
Механизм динамического thinking — одна из ключевых инноваций Gemini 3 Flash. Модель автоматически определяет сложность входящего запроса и адаптирует глубину обработки: для простых вопросов вроде фактических справок или базовой генерации текста используется быстрый путь с минимальным числом итераций, что даёт sub-second латентность. Для сложных задач — математических доказательств, архитектурных решений в коде, многоступенчатого анализа данных — активируется расширенный режим, где модель "думает дольше", проверяет альтернативные гипотезы и строит цепочки рассуждений. Это позволяет экономить в среднем 30% токенов на типичных задачах по сравнению с Gemini 2.5 Pro, которая использует фиксированную глубину обработки независимо от сложности запроса.
Нативная мультимодальность заложена в саму архитектуру, а не добавлена как отдельный модуль. Текст, изображения, аудио и видео обрабатываются едиными энкодерами и проецируются в общее пространство эмбеддингов, что позволяет модели понимать связи между модальностями без явного преобразования. Например, при анализе скриншота интерфейса с вопросом "как улучшить UX этой страницы", модель одновременно обрабатывает визуальную структуру, текстовые элементы, пространственные отношения и семантику запроса, формируя единое представление задачи. Это принципиально отличается от pipeline-подходов, где сначала изображение превращается в текстовое описание, а затем обрабатывается языковой моделью — такие системы теряют детали и вносят ошибки на этапе преобразования.
Работа с видео в реальном времени стала возможной благодаря streaming-архитектуре: модель обрабатывает видеопоток frame-by-frame, сохраняя контекст предыдущих кадров и отслеживая изменения объектов во времени. Google демонстрировала примеры, где Gemini 3 Flash следит за игровым процессом в bubble shooter, предсказывает траектории шаров и даёт стратегические рекомендации в режиме реального времени — это требует обработки десятков кадров в секунду с сохранением пространственной и временной когерентности.
Размер контекстного окна у Gemini 3 Flash сопоставим с Pro-версией и позволяет обрабатывать документы длиной в десятки тысяч токенов. Модель эффективно работает с длинным контекстом благодаря механизмам sparse attention и hierarchical processing: вместо того чтобы каждый токен взаимодействовал со всеми остальными (что даёт квадратичную сложность), модель группирует информацию по уровням абстракции и фокусирует внимание на релевантных фрагментах. Это критично для задач вроде анализа кодовых баз, обработки научных статей или суммаризации длинных транскриптов.
В результате Gemini 3 Flash представляет собой не просто "урезанную Pro", а самостоятельную архитектуру, спроектированную под принцип "efficiency without compromise" — максимальная эффективность без компромиссов в качестве. Именно поэтому модель способна обгонять более тяжёлые системы в реальных задачах, сочетая интеллект флагманов с производительностью специализированных fast-моделей.
Gemini 3 Flash заметно выделяется на фоне предыдущих моделей и конкурентов именно по части сложного рассуждения и академического уровня знаний. Важно не просто перечислить цифры, а понять, что они означают для реальных задач.
GPQA Diamond — один из самых жёстких тестов, который моделирует вопросы уровня аспирантуры и PhD с дополнительной защитой от «гугления» ответов.
Gemini 3 Flash показывает на этом бенчмарке около 90%+ точности, что ставит её на уровень флагманских фронтир‑моделей и значительно выше предыдущих поколений, вроде Gemini 2.5 Flash. Такой результат означает, что модель уверенно справляется с задачами, где требуется не просто помнить факты, а сочетать глубокие знания из разных областей: математики, физики, биологии, экономики, философии. Это критично для приложений, связанных с научной работой, сложной аналитикой и экспертными консультациями.
Humanity’s Last Exam — это стресс‑тест для ИИ, построенный как набор максимально сложных, неоднозначных и многослойных задач, которые должны выявить реальные пределы модели.
Gemini 3 Flash показывает на этом тесте показатель, кратно превосходящий предыдущее поколение (порядка трёхкратного роста по сравнению с серией 2.5). Это демонстрирует не просто повышение «средней» точности, а качественный скачок в умении работать с задачами, где нет очевидного ответа, нужно строить цепочки аргументов, рассматривать альтернативы и делать взвешенные выводы. Для пользователя это выражается в том, что модель гораздо реже «ломается» на нестандартных вопросах и лучше выдерживает нагрузку в экспертных сценариях.
MMMU Pro (Massive Multi-discipline Multimodal Understanding) тестирует способность модели решать задачи из множества дисциплин, причём в мультимодальном формате: текст + схемы, изображения, формулы, графики.
На этом бенчмарке Gemini 3 Flash показывает результат в районе 80%+, что означает уверенный state‑of‑the‑art уровень. Модель не просто читает текст задачи, а понимает диаграммы, чертежи, слайды, визуальные элементы и связывает их с текстовым контекстом. На практике это важно для:
анализа презентаций, отчётов и научных статей с графиками и формулами
работы с учебными материалами, где текст и иллюстрации тесно переплетены
технической документации, включающей схемы, интерфейсы, архитектурные диаграммы
Кроме флагманских бенчмарков, Gemini 3 Flash демонстрирует сильные результаты на классических наборах задач по логике, математике и кросс‑дисциплинарным вопросам:
на логических тестах модель уверенно удерживает высокий процент точности, что отражается в её способности разбирать сложные аргументы, находить логические ошибки и строить корректные выводы
на математических задачах среднего и продвинутого уровня Flash решает не только стандартные школьные примеры, но и задачи с несколькими шагами, абстрактными определениями и неочевидными преобразованиями
в комбинированных наборах вопросов (где встречаются история, экономика, естественные науки, гуманитарные дисциплины) модель демонстрирует ровное качество без сильных провалов по отдельным областям
Чистые проценты на бенчмарках важны, но ещё важнее их практическое значение:
модель гораздо лучше справляется с многошаговыми задачами: «разбери проблему», «предложи подход», «обоснуй решение»
снижается количество грубых логических ошибок в длинных рассуждениях
повышается надёжность в экспертных сценариях: аналитические отчёты, технические разборы, научные и около‑научные тексты
становится возможным делегировать модели более «ответственные» задачи — например, первичный анализ сложных документов, подготовку черновиков исследовательских обзоров, оценку аргументов в спорных вопросах
Именно сочетание высоких результатов на GPQA Diamond, Humanity’s Last Exam и MMMU Pro делает Gemini 3 Flash моделью, которая не просто «генерирует связный текст», а действительно умеет рассуждать, опираясь на широкий спектр знаний и сложные взаимосвязи.
Полезные посты по нейронкам:
👉 Как сделать фото в кокошнике
👉 Фото в стиле "Портрет поколений" через нейросеть
👉 17 промтов для фотографий на Новый Год
👉 Семейная фотосессия на новогодние праздники
👉 Фото в стиле "Гринч - похититель Рождества"
👉 Фото в стиле "Мужская фотосессия" через Nano Banana
👉 Фото в стиле "Очень странные дела" с Нано Банана ПРО
👉 Фотосессия на Новый Год через нейросеть (Nano Banana | + PRO)
👉 Модный ИИ тренд: ёлочные игрушки из фото
👉 Зимняя фотосессия с помощью нейросети
👉 Фотосессия в стиле "Голливуд" через ИИ
👉 Как сделать фото в любом стиле через нейросеть
👉 Трендовое видео: как сделать вязаный город
👉 Как примерить одежду через нейросеть
👉 Трендовое фото с персонажем в лифте
👉 Как сделать фигурку по фото через нейросеть
👉 Реставрация фотографий через нейросеть
👉 Большой набор промтов для фото в стиле Хэллоуин
👉 Как сделать фото с Криком через ИИ
👉 Нейросеть Veo 3 для генерации видео: официальный сайт на русском
Gemini 3 Flash особенно сильна в прикладном программировании: не только в генерации кода, но и в решении реальных инженерных задач. На бенчмарке SWE-bench Verified, который использует реальные issue и pull request из GitHub‑репозиториев, модель достигает около 78% успешных решений, обгоняя не только линейку Gemini 2.5, но и более тяжёлую Gemini 3 Pro на этом конкретном тесте. Это означает, что Flash уверенно справляется с задачами уровня «настоящего проекта»: поиск и исправление багов в незнакомом коде, корректная интеграция изменений, учёт контекста репозитория и тестов.
На задачах логического программирования и структурного анализа кода Gemini 3 Flash демонстрирует высокий уровень понимания логики программ. В расширенных тестах, подобных Extended NYT Connections (оценка способности находить нетривиальные связи), модель показывает более 90% точности, тогда как Gemini 2.5 Flash остаётся на уровне порядка 25%. Такой разрыв говорит о качественном скачке в умении модели удерживать сложные структуры, сопоставлять фрагменты кода, комментариев и документации и делать правильные выводы о том, как система работает целиком.
В агентных сценариях Gemini 3 Flash проявляет себя как модель, способная не просто отвечать на точечные вопросы, а вести многошаговую работу с использованием инструментов. Например, в типичном pipeline для разработчика модель может: проанализировать issue, предложить план исправления, сгенерировать патч, написать тесты, объяснить изменения и подготовить текст к pull request. На каждом шаге она опирается на результаты предыдущего, корректирует курс по обратной связи пользователя и при необходимости пересобирает решение. Это приближает её к роли «сопилота», который способен брать на себя значительную часть рутины в разработке, а не просто выдавать разрозненные фрагменты кода.
Важно, что высокие бенчмарки по программированию сочетаются со скоростью: благодаря ~218 токенам в секунду и малому времени до первого токена модель позволяет делать гораздо больше итераций за единицу времени, чем предыдущие версии. В реальных условиях это означает, что разработчик может несколько раз подряд уточнять задачу, просить альтернативные решения, сравнивать варианты реализации — и всё это в рамках одного рабочего сеанса без ощутимых задержек.
Gemini 3 Flash спроектирована как модель, в которой скорость работы — не побочный эффект оптимизаций, а главный продуктовый приоритет. При этом она сохраняет фронтир‑уровень интеллекта, что делает её пригодной не только для «быстрых черновиков», но и для серьёзных рабочих задач.
По данным независимого тестирования, средняя скорость генерации Gemini 3 Flash составляет около 200–220 токенов в секунду, тогда как у Gemini 2.5 Pro этот показатель находится в районе 70–80 токенов в секунду. Это даёт примерно трёхкратное преимущество по скорости при сопоставимом качестве текста. В сценариях, где пользователь активно уточняет запросы и ведёт диалог с моделью, такое ускорение превращается в возможность сделать в разы больше итераций за то же время.
Важный параметр — время до первого токена (Time-to-First-Token). У Gemini 3 Flash оно укладывается в доли секунды даже на сложных запросах, тогда как у более тяжёлых моделей задержка может быть заметной. Для живых интерфейсов — чат‑ассистентов, IDE‑помощников, голосовых интерфейсов — это критично: пользователь ощущает, что модель «отвечает сразу», без пауз и «подвисаний». Такое поведение особенно важно для задач реального времени: подсказки во время набора текста, динамическая генерация кода, комментарии к происходящему на экране.
Производительность в длинных сессиях также стала сильной стороной модели. За счёт оптимизированной архитектуры Flash потребляет в среднем на 30% меньше токенов на типичных задачах, чем Gemini 2.5 Pro, при этом сохраняет или улучшает качество ответов. Это достигается за счёт динамической глубины обработки: модель не тратит ресурсы на избыточные вычисления там, где это не нужно, и углубляется только в действительно сложные запросы. В результате одна и та же инфраструктура (серверы, лимиты запросов) способна обслужить в разы больше пользователей или задач без потери качества.
В практических тестах Artificial Analysis и других бенчмаркинговых проектов Gemini 3 Flash показывает впечатляющее сочетание скорости и эффективности: полный ответ на запрос длиной 500–700 токенов формируется заметно быстрее, чем у соперников, причём разница особенно велика при последовательной работе (когда один запрос следует за другим). Для команд разработки это означает больше экспериментов с архитектурой и кодом за смену, для контент‑отделов — больше вариантов текстов и правок, для аналитиков — больше прогонов моделей и сценариев.
Наконец, высокая скорость напрямую влияет на экономику использования: чем быстрее модель, тем меньше времени и вычислительных ресурсов уходит на каждую задачу. В сочетании с низкой стоимостью токенов это делает Gemini 3 Flash одной из самых выгодных моделей в своём классе, особенно при массовом применении — в продуктах, обслуживающих тысячи и миллионы пользователей одновременно.
Gemini 3 Flash изначально проектировалась как модель, которая должна заменить собой предыдущую «рабочую лошадку» — Gemini 2.5 Pro, причём без компромиссов по качеству. По уже описанным в статье данным Flash обгоняет 2.5 Pro в большинстве ключевых тестов (включая сложный reasoning, мультимодальность и программирование), показывая при этом кратно лучшую скорость и меньший расход токенов. Если 2.5 Pro была моделью «на все случаи», но с ощутимой латентностью и высокой ценой, то 3 Flash фактически забирает её роль, оставляя Pro для нишевых сценариев, где важен каждый процент качества.
По сути, там, где раньше логика выбора звучала как «Pro — для максимального качества, Flash — для скорости», теперь уравнение меняется. В подавляющем большинстве задач именно 3 Flash становится разумным дефолтом: она даёт сопоставимый или лучший результат в сложных бенчмарках, при этом в разы быстрее и дешевле в эксплуатации. 2.5 Pro остаётся оправданным выбором только в тех случаях, когда инфраструктура уже жёстко заточена под неё или когда нужно точечно использовать её специфическое поведение в отдельных пайплайнах.
Интересна и другая часть картины: Gemini 3 Flash часто сравнивают не только с 2.5 Pro, но и с более крупными моделями, которые традиционно считаются флагманами для сложных задач. Здесь ключевой момент в том, что Flash по ряду бенчмарков reasoning и программирования приближается к результатам тяжёлых моделей, а иногда и догоняет их, но при этом выигрывает по латентности и экономике. В практических сценариях это даёт ощутимую разницу: там, где большая модель будет «думать» заметное время и требовать больше ресурсов, Flash выдаёт ответ быстрее и дешевле, сохраняя понятное, логичное и структурированное решение задачи.
В итоге, когда речь идёт не о демонстрации максимально возможного IQ модели, а о реальных продуктовых нагрузках — чат‑ботах, ассистентах для разработчиков, контент‑системах, сервисах аналитики, — именно Gemini 3 Flash оказывается привлекательным балансом. Она даёт уровень качества, близкий к флагманам, но позволяет горизонтально масштабировать сервисы без взрывного роста затрат. Это и является причиной, по которой Google выдвигает именно Flash на роль основной рабочей модели в своей экосистеме.
На фоне других крупных языковых моделей Gemini 3 Flash занимает позицию «фронтир‑качество по цене и скорости fast‑моделей». Классический выбор между «самой умной» и «самой быстрой» моделью здесь во многом снимается: Flash приближается к флагманам по сложному reasoning и кодингу, но работает заметно быстрее и обходится дешевле в эксплуатации. В задачах, где нужно много итераций (разработка, аналитика, контент), это даёт реальное преимущество — можно перепробовать больше вариантов, глубже уточнять запросы и чаще переделывать результат без страха «сжечь» бюджет или потерять время.
По мультимодальности Gemini 3 Flash опирается на единый архитектурный стек: текст, изображения, аудио и видео обрабатываются в общем пространстве представлений, а не через отдельные «надстроечные» модули. Это особенно заметно в задачах с видео и сложной визуальной логикой — модель уверенно отслеживает объекты во времени, понимает интерфейсы, планирует действия на основе происходящего в кадре. Многие конкуренты пока ограничиваются более простым сценарием «картинка → текстовое описание → языковая модель», что ведёт к потере деталей и снижению точности на действительно сложных мультимодальных задачах.
С точки зрения экономики использования Flash выигрывает за счёт двух факторов: низкой цены токена на уровне API и оптимизированного расхода токенов на типичных задачах (в среднем до 30% экономии относительно 2.5 Pro). В совокупности с высокой скоростью это делает модель особенно привлекательной для массовых сценариев: клиентские чаты, образовательные платформы, автоматизация поддержки, большие контент‑потоки. Там, где использование тяжёлых моделей быстро становится слишком дорогим, Gemini 3 Flash позволяет сохранить качество на высоком уровне и при этом удержать расходы под контролем.
Мультимодальность Gemini 3 Flash — фундаментальная особенность архитектуры: единые энкодеры проецируют текст, изображения, видео и аудио в общее пространство представлений без промежуточных потерь.
С изображениями модель демонстрирует spatial reasoning: считает объекты, анализирует композицию и UX, предлагая конкретные улучшения («переместить кнопку на 20% левее, увеличить контраст на 15%»).
Видеообработка в реальном времени — ключевой прорыв: отслеживает объекты между кадрами, предсказывает траектории (демо bubble shooter), анализирует спортивную технику, создаёт субтитры с контекстом.
Комбинированные задачи: диаграмму → React-код с логикой связей; скриншот Excel → анализ трендов + SQL-запросы.
Аудио: транскрипция с speaker ID, эмоциональным анализом, action items («решения на 5:30»). Идеально для подкастов и встреч.
Кейсы: UX-анализ баннеров, формулы → конспект, wireframes → код, сканы договоров → ключевые пункты.
Flash работает с реальными данными пользователей, делая её универсальной рабочей моделью.
➡️➡️➡️
Попробовать Джемини 3 ФлешGemini 3 Flash предлагает гибкие режимы работы, адаптирующиеся под специфику задачи, что делает её особенно эффективной в разных сценариях. Основное разделение происходит по глубине обработки: базовый режим для быстрых ответов и extended thinking для сложного анализа.
Базовый режим активируется автоматически на простых запросах — фактическая информация, генерация текста, базовый код, анализ изображений. Здесь модель использует минимальное количество итераций внимания и оптимизированные пути инференса, что даёт sub-second латентность даже на длинных промптах. Такой подход идеален для чат-ботов, автозаполнения, live-комментариев к коду или изображениям — пользователь получает ответ практически мгновенно, без ощущения задержки.
Extended thinking режим включается на сложных задачах, где требуется многошаговое рассуждение. Модель разбивает запрос на подзадачи, проверяет гипотезы, рассматривает альтернативы и строит логическую цепочку. Это заметно на примерах: решение математических задач с доказательствами, архитектурный анализ кода, многоуровневый бизнес-анализ или интерпретация научных данных. В отличие от фиксированной глубины у предыдущих моделей, Flash сама определяет, когда «думать дольше», экономя ресурсы на простых запросах.
Оптимизация промптов критически важна для максимальной отдачи от модели. Короткие, конкретные инструкции работают лучше всего: вместо «напиши что-нибудь про маркетинг» лучше «составь план email-рассылки для B2B SaaS с 5 шагами и примерами тем писем». Указание роли усиливает точность: «ты опытный React-разработчик, найди баги в этом компоненте» даёт более профессиональные ответы, чем общий запрос. Для мультимодальных задач полезно комбинировать модальности в одном промпте: «на скриншоте интерфейса найди проблемы UX и предложи CSS-фиксы».
Управление контекстом — сильная сторона Flash благодаря большому окну (сотни тысяч токенов) и механизмам sparse attention. Модель эффективно удерживает информацию из длинных диалогов, кодовых баз или документов, фокусируясь на релевантных частях без потери качества. В production-сценариях это позволяет строить сессии с накоплением контекста: первая итерация анализирует задачу, вторая предлагает решение, третья — оптимизирует код, четвёртая — пишет тесты.
Streaming-режим подходит для интерактивных приложений: модель выдаёт токены по мере генерации, что создаёт эффект «живого» ответа. Пользователь видит первые слова через 200–300 мс и может прервать или уточнить запрос на лету. Batch-режим эффективнее для массовой обработки: генерация сотен вариантов контента, анализ большого числа изображений или параллельный рефакторинг модулей.
Rate limits в API спроектированы под высокую нагрузку: сотни запросов в минуту при разумных тарифах, что делает Flash подходящей для enterprise-приложений. Best practices включают: кэширование частых запросов, батчинг похожих задач, мониторинг расхода токенов и постепенное нарастание сложности промптов в диалоге.
Правильная настройка режимов и промптов позволяет выжать из Gemini 3 Flash максимум: базовые задачи решаются мгновенно, сложные — с качеством флагманов, а общий расход ресурсов остаётся минимальным.
Что ждать от следующих версий? Логичное развитие — Gemini 4 Flash с улучшенным long-term reasoning, нативной поддержкой structured data (JSON, XML, databases), возможно, эксперименты с MoE-архитектурами для ещё большей эффективности. Google также может открыть больше деталей о тренировке — dataset composition, alignment techniques, что ускорит исследования в индустрии.
Gemini 3 Flash не просто модель, а сигнал о завершении эры компромиссов в ИИ: впереди время, когда любой сервис сможет работать на уровне лучших умов человечества, оставаясь при этом быстрым, дешёвым и масштабируемым.

Qwen 3 — это семейство больших языковых моделей третьего поколения от команды Alibaba Cloud, официально представленное в апреле 2025 года. Линейка стала серьёзным вызовом для лидеров рынка вроде GPT-5 и Claude, предлагая мощные возможности при полной открытости исходного кода. В отличие от проприетарных решений, все модели Qwen 3 доступны для скачивания, модификации и локального развёртывания под лицензией Qwen License.
В России лучший вариант познакомиться с основными возможностями этого ИИ от Алибабы — агрегатор нейросетей Study AI.
Почему Study AI?
1) Не нужен VPN
2) Есть бесплатные пробные токены
3) Можно платить любыми российскими картами
4) Быстрая генерация
5) 40+ лучших нейронок в одном окне6) Отличное предложение со скидкой на Чёрную Пятницу на тарифы PRO и Ultima!
➡️➡️➡️
Qwen 3 на русскомГлавное отличие от предшественника Qwen 2.5 — радикально увеличенный объём обучающих данных (36 триллионов токенов против 18T) и революционная функция гибридного режима рассуждений. Семейство включает восемь моделей от компактных 0.6B параметров для edge-устройств до флагманских 235B параметров с архитектурой Mixture of Experts. Qwen 3 позиционируется как универсальное решение для разработчиков, исследователей и компаний, которым нужна производительность уровня передовых проприетарных моделей без ограничений закрытых систем.
Линейка Qwen 3 включает восемь моделей с параметрами от 0.6B до 235B, охватывая весь спектр задач — от работы на смартфонах до обработки сложнейших запросов на серверах. Семейство делится на две архитектуры: плотные модели (Dense) и гибридные с экспертами (MoE — Mixture of Experts).
Плотные модели (Dense) представлены шестью версиями: Qwen3-0.6B, 1.7B, 3B, 7B, 14B и 32B. Это классические трансформеры, где все параметры активны при каждом запросе. Они обеспечивают стабильную производительность, предсказуемое потребление ресурсов и простоту развёртывания. Младшие модели (0.6B–3B) оптимизированы для edge-устройств и мобильных приложений, требуя минимум оперативной памяти. Старшие версии (7B–32B) подходят для серверного использования, где нужен баланс между качеством и скоростью.
MoE-модели — это Qwen3-30B-A3B и флагманская Qwen3-235B-A22B. В названии первое число обозначает общее количество параметров, второе (после "A") — активируемых при обработке каждого токена. Например, 235B-A22B содержит 235 миллиардов параметров, но использует только 22 миллиарда на запрос, что даёт производительность топовой модели при затратах средней. Флагман использует 128 экспертов, активируя по 8 на каждый токен, что позволяет специализировать части модели на разных типах задач.
Все модели поддерживают контекст от 128K до 262K токенов нативно, с возможностью расширения до 1 миллиона токенов через технику YaRN. Лицензия Qwen позволяет коммерческое использование, модификацию весов и создание производных моделей.
Уникальная особенность Qwen 3 — встроенная способность переключаться между двумя режимами работы внутри одной модели. Это делает семейство первым открытым решением с нативной поддержкой адаптивного мышления, которая раньше была доступна только в проприетарных системах вроде o1 от OpenAI.
Режим мышления (Thinking Mode) активирует пошаговую цепочку рассуждений для сложных задач. Модель явно проговаривает логику решения, проверяет промежуточные шаги и корректирует ошибки до финального ответа. Этот режим критичен для математических доказательств, отладки кода, логических головоломок и научного анализа — везде, где важна точность и прозрачность процесса. На бенчмарке AIME25 (олимпиадные задачи по математике) Qwen3-235B в режиме мышления набирает 70.3 балла против 49.5 у ближайшего конкурента.
Быстрый режим (Non-Thinking Mode) оптимизирован для мгновенных ответов на простые запросы — генерация текста, перевод, суммаризация, базовые вопросы. Модель пропускает развёрнутые рассуждения и выдаёт результат напрямую, экономя до 70% токенов и работая в 3–5 раз быстрее. Это идеально для чат-ботов, контент-платформ и массовой обработки документов, где скорость важнее глубины анализа.
Переключение между режимами управляется одним параметром при вызове API или через системный промпт при локальном развёртывании. Разработчики могут динамически выбирать режим в зависимости от типа запроса, создавая гибридные приложения: быстрые ответы для 90% рутинных задач и глубокий анализ для критичных 10%.
Qwen 3 обучался на массиве из 36 триллионов токенов — вдвое больше, чем у предыдущего поколения. Расширенный датасет включает научные статьи, программный код, мультиязычные тексты и специализированные данные для рассуждений, что заметно улучшило качество работы модели в сложных доменах.
Мультиязычность — одно из ключевых преимуществ семейства. Qwen 3 поддерживает 119 языков и диалектов, превосходя большинство конкурентов, включая DeepSeek-R1, который фокусируется на английском и китайском. Модель демонстрирует сильную производительность в задачах перевода, мультиязычного поиска информации и генерации контента на редких языках. Это делает Qwen 3 оптимальным выбором для глобальных продуктов, международной поддержки клиентов и приложений с аудиторией из разных регионов.
Агентные возможности выводят Qwen 3 за рамки обычной генерации текста. Модель нативно поддерживает протокол MCP (Model Context Protocol) и продвинутый function calling, позволяя взаимодействовать с внешними инструментами, API и базами данных. В отличие от более ранних решений, где вызовы функций происходили отдельно, Qwen 3 встраивает их прямо в цепочку рассуждений. Модель может последовательно использовать калькулятор для вычислений, обращаться к поисковику для проверки фактов, запрашивать данные из API и комбинировать результаты в финальном ответе — всё в рамках одного запроса.
Флагманская архитектура Qwen3-235B-A22B использует 94 трансформерных слоя с grouped query attention: 64 головы внимания для запросов и 4 для ключей-значений. Такая конфигурация оптимизирует память при сохранении качества долгосрочных зависимостей в тексте. Контекстное окно до 262,144 токенов позволяет обрабатывать целые книги, большие кодовые базы и объёмные документы без разбиения на фрагменты.
Qwen3-235B занимает лидирующие позиции среди открытых моделей по большинству академических тестов. На математическом бенчмарке AIME25 (олимпиадные задачи американской школы) модель показывает 70.3 балла, опережая Kimi K2 с 49.5 и другие опен-сорс решения. По абстрактному рассуждению ARC-AGI результат составляет 41.8 против 13.3 у ближайшего конкурента — разрыв более чем втрое.
В задачах программирования Qwen 3 демонстрирует сильные результаты: 65.8% на SWE-bench Verified (реальные GitHub-задачи), 53.7% на LiveCodeBench v6 (актуальные coding-челленджи) и 89.5% на MMLU (общие знания и reasoning). Специализированная версия Qwen3-Coder оптимизирована для генерации кода и показывает ещё более высокую точность в мультишаговой отладке. Модель успешно справляется с рефакторингом legacy-кода, исправлением багов и написанием тестов — задачами, где требуется понимание контекста всего проекта.
Сравнение с проприетарными моделями показывает смешанную картину. По качеству рассуждений Qwen3-Max-Thinking сопоставим с GPT-o1 и Claude Sonnet 4.5 на математических задачах и логических головоломках. Однако открытая модель существенно медленнее: генерирует в 3–4 раза больше токенов для достижения того же результата и работает до 10 раз дольше Claude на некоторых типах запросов. Это компромисс между глубиной рассуждений и скоростью — Qwen 3 проговаривает каждый шаг явно, что увеличивает latency, но повышает прозрачность и надёжность.
В противостоянии с DeepSeek-R1, другим китайским флагманом, Qwen 3 выигрывает по мультиязычности и универсальности, но уступает в эффективности. DeepSeek быстрее генерирует корректный код с первой попытки и требует меньше вычислительных ресурсов (FLOPs) на аналогичные задачи. Qwen 3 лучше подходит для международных проектов и задач с глубоким анализом, DeepSeek — для высокоскоростной кодогенерации на английском и китайском.
Qwen 3 решает широкий спектр задач благодаря гибкости архитектуры и режимам работы. Основные области применения охватывают как корпоративные решения, так и индивидуальные проекты разработчиков.
Генерация и отладка кода — одна из сильнейших сторон семейства. Qwen3-Coder специализируется на написании функций, рефакторинге legacy-систем и автоматическом исправлении багов в контексте всего проекта. Модель анализирует зависимости между модулями, предлагает оптимизации и генерирует unit-тесты с учётом edge cases. В режиме мышления она пошагово объясняет логику решения, что особенно полезно для обучения джуниоров и code review.
Мультиязычные приложения и глобальная поддержка используют поддержку 119 языков. Компании развёртывают Qwen 3 для чат-ботов техподдержки, автоматического перевода документации и локализации контента. Модель сохраняет высокое качество даже на редких языках, где конкуренты часто дают некорректные результаты.
AI-агенты с доступом к инструментам — растущий сегмент применения. Qwen 3 встраивается в системы с function calling для автоматизации сложных workflows: обработка заказов с проверкой наличия через API, финансовый анализ с подтягиванием real-time данных, исследовательские задачи с последовательным поиском и синтезом информации. Протокол MCP позволяет модели работать с внешними базами знаний и корпоративными системами без костылей.
Научные исследования и аналитика требуют режима глубоких рассуждений. Qwen 3 применяется для проверки математических доказательств, анализа больших датасетов, генерации гипотез и literature review с обработкой сотен статей в длинном контексте. Модель помогает исследователям находить паттерны в данных и формулировать выводы, явно показывая цепочку логики.
Edge-устройства и мобильные приложения используют младшие модели 0.6B–4B. Они работают на смартфонах, IoT-девайсах и встроенных системах без подключения к облаку. Сценарии включают офлайн-переводчики, голосовые ассистенты и интеллектуальную обработку данных на устройстве с минимальным энергопотреблением.
Все модели семейства Qwen 3 доступны для свободного скачивания и использования под лицензией Qwen License. Основной хаб для загрузки весов — Hugging Face, где представлены все версии от 0.6B до 235B с подробной документацией и примерами кода.
Локальное развёртывание поддерживается через популярные фреймворки: llama.cpp, vLLM, Ollama и Transformers. Для младших моделей (0.6B–7B) достаточно потребительских видеокарт с 8–16 GB VRAM. Qwen3-14B требует около 28 GB в FP16 или 14 GB с квантизацией до 4-bit. Флагманская 235B-модель в полной точности нуждается в серверных конфигурациях, но квантизованные версии работают на setup с 48–80 GB VRAM. Официальная документация включает инструкции по оптимизации инференса и настройке под конкретное железо.
API-доступ доступен через несколько платформ. Alibaba Cloud предоставляет официальный API с моделями Qwen3-Max и Qwen3-235B через сервис DashScope. OpenRouter агрегирует доступ к разным версиям, включая Qwen3-30B-A3B и флагманскую 235B, с унифицированным интерфейсом. Qwen Chat — веб-интерфейс для интерактивного тестирования моделей без необходимости развёртывания.
Квантизация и оптимизация критичны для работы больших моделей на ограниченном железе. Доступны версии в форматах GGUF (для llama.cpp), AWQ и GPTQ с разной степенью сжатия от 8-bit до 2-bit. Квантизация до 4-bit даёт минимальную потерю качества при сокращении требований к памяти вдвое. Для продакшн-сценариев рекомендуется тестировать несколько вариантов квантизации на реальных задачах, так как влияние на точность зависит от домена.
Миграция с других моделей упрощается совместимостью с OpenAI API — достаточно изменить endpoint и ключ, оставив остальной код без изменений. Это позволяет быстро интегрировать Qwen 3 в существующие приложения для тестирования или полной замены проприетарных решений.
Qwen3-VL расширяет возможности семейства за пределы текста, добавляя нативную обработку изображений, видео и визуальных данных. Модель совмещает vision-encoder с языковой основой Qwen 3, позволяя анализировать визуальный контекст и рассуждать о нём на том же уровне, что и о текстовой информации.
Возможности обработки изображений включают детальное описание сцен, распознавание объектов и их взаимосвязей, чтение текста с фотографий и документов, анализ графиков и диаграмм. Qwen3-VL справляется с задачами visual question answering — отвечает на вопросы по содержимому изображения, используя режим рассуждений для сложных запросов. Например, модель может проанализировать схему электроники, объяснить принцип работы и предложить улучшения, явно проговаривая логику выводов.
Видео-понимание позволяет обрабатывать временные последовательности кадров, отслеживать изменения объектов и генерировать описания действий. Модель применяется для автоматической генерации субтитров, анализа спортивных событий, мониторинга видеопотоков с камер наблюдения и создания саммари длинных роликов. Длинный контекст позволяет анализировать видео продолжительностью в десятки минут без потери деталей.
Практические сценарии охватывают автоматизацию document processing (извлечение данных из накладных, чеков, форм), медицинскую диагностику по снимкам с объяснением находок, обучающие приложения с анализом фотографий для образовательного контента, e-commerce с визуальным поиском и описанием товаров. Мультимодальность особенно ценна для AI-агентов, которые взаимодействуют с графическими интерфейсами — модель может "видеть" экран, понимать UI-элементы и выполнять действия на основе визуального контекста.
Qwen3-VL сохраняет все текстовые возможности базовой модели, включая мультиязычность, длинный контекст и гибридный режим рассуждений, делая её универсальным решением для задач, где требуется понимание и текста, и изображений одновременно.
Qwen 3 — оптимальный выбор для проектов, где критична открытость, мультиязычность и глубина рассуждений. Семейство превосходит конкурентов в задачах, требующих работы с десятками языков, прозрачной логики решений и интеграции с внешними инструментами. Гибридный режим позволяет балансировать между скоростью и качеством в рамках одной модели, избегая необходимости держать несколько систем для разных сценариев.
Главные преимущества включают полную открытость весов для модификации и локального развёртывания, поддержку 119 языков против узкой специализации конкурентов, встроенный режим рассуждений без внешних надстроек, нативный function calling и MCP для агентных систем, гибкую линейку от 0.6B для edge до 235B для серверов. Лицензия позволяет коммерческое использование без ограничений, что делает Qwen 3 привлекательным для продуктов с требованиями к конфиденциальности данных.
Рекомендации по выбору модели: для мобильных приложений и IoT подойдут Qwen3-0.6B или 1.7B; для общих задач с балансом качества и ресурсов — Qwen3-7B или 14B; для кодогенерации — специализированный Qwen3-Coder любого размера; для максимальной производительности при разумных затратах — MoE-версия Qwen3-30B-A3B; для передовых результатов в reasoning и сложных задачах — флагманская Qwen3-235B-A22B. Визуальные задачи требуют Qwen3-VL с соответствующим размером базовой модели.
Перспективы развития семейства связаны с дальнейшей оптимизацией скорости inference, расширением агентных возможностей и улучшением мультимодальности. Qwen 3 уже сегодня представляет серьёзную альтернативу проприетарным решениям для команд, которым нужен контроль над инфраструктурой без компромиссов по качеству.

18 ноября 2025 года Google анонсировала Gemini 3 — третье поколение своей флагманской AI-модели, которая обещает изменить представление о том, как искусственный интеллект взаимодействует с людьми. Если предыдущие версии учили нейросети понимать текст, картинки и видео одновременно, то Gemini 3 идет дальше: модель не просто выполняет команды, а понимает контекст ваших намерений с первого раза.
Представьте себе ассистента, который не задает уточняющих вопросов типа "А что именно вы имели в виду?" каждый раз, когда вы формулируете запрос не идеально. Gemini 3 воплощает философию "от слов к делу": вы говорите, что хотите сделать, а модель сама разбирается в деталях и создает не просто текст или картинку, а целые интерактивные приложения — калькуляторы, симуляции, даже рабочие прототипы игр. Это эволюция от простых чат-ботов к настоящим агентам, способным самостоятельно планировать и выполнять сложные задачи.
В этой статье мы разберем все, что нужно знать о Gemini 3: от технических характеристик и бенчмарков до реальных сценариев использования и сравнения с конкурентами вроде GPT-5.1 и Claude.
В России доступ к новой мощной нейросети от Google ограничен, но уже сейчас есть возможность попробовать основные возможности Gemini 3 через сервис Study AI.
Почему Study AI?
1) Не нужен VPN
2) Есть бесплатный пробный тариф
3) Можно платить любыми российскими картами
4) Быстрая генерация
5) 30+ лучших нейронок в одном окне
Gemini 3 — это третье поколение AI-моделей от Google DeepMind, которое стало логичным продолжением эволюции, начавшейся в декабре 2023 года. Если объяснять простыми словами, каждая версия Gemini решала конкретную задачу: первая научила AI одновременно понимать текст, картинки и звук, вторая сделала контекстное окно огромным (представьте, что модель может "прочитать" тысячу страниц за раз), а третья объединила все это и добавила способность действовать как настоящий агент.
Главное отличие Gemini 3 от предшественников — это понимание намерений. Раньше вы могли написать "помоги мне с презентацией про AI", и модель спрашивала: для какой аудитории, сколько слайдов, какой стиль? Gemini 3 анализирует контекст вашего запроса глубже и сразу предлагает структуру, которая, скорее всего, вам подойдет. Это как разница между новичком, который задает миллион уточняющих вопросов, и опытным специалистом, который сразу понимает суть задачи.
Философия развития Gemini строится на трех китах: мультимодальность (работа с любыми форматами данных), агентность (способность планировать и выполнять задачи автономно) и контекстное понимание (улавливание смысла, а не только слов). Если Gemini 1.0 был про "я вижу и слышу все форматы", Gemini 1.5 — про "я могу обработать огромный объем информации", Gemini 2.0 — про "я могу действовать сам", то Gemini 3 говорит: "я понимаю, чего ты хочешь, и сделаю это лучше, чем ты ожидаешь".
➡️➡️➡️ Попробовать Gemini 3 ИИ
Чтобы понять масштаб прорыва Gemini 3, давайте посмотрим, как развивалась эта семья моделей от первого запуска до сегодняшнего дня. Каждое поколение решало конкретную проблему, которую не могли закрыть предшественники.
Gemini 1.0 (декабрь 2023) стал первой попыткой Google создать по-настоящему мультимодальную модель, которая изначально обучалась на всех типах данных одновременно. До этого большинство AI-моделей были "текстоцентричными" — сначала они понимали слова, а потом к ним "прикручивали" возможность работать с картинками. Gemini 1.0 же с самого начала видел мир так, как его видим мы: текст, изображения, звуки — все сразу.
Gemini 1.5 (февраль 2024) совершил прорыв в области контекста, увеличив окно с 32K до невероятного 1 миллиона токенов — это примерно 1500 страниц текста. Представьте, что вы можете загрузить в AI целую книгу или двухчасовой фильм, и модель "запомнит" каждую деталь. Это открыло возможности для анализа огромных документов, длинных видео и сложных исследований.
Gemini 2.0 (декабрь 2024) ознаменовал начало "агентной эры" — модель научилась не просто отвечать, а действовать. Она могла самостоятельно искать информацию в интернете, планировать многошаговые задачи и даже генерировать изображения и аудио нативно, без сторонних инструментов. Это уже был не помощник, а скорее коллега, который берет задачу и доводит ее до конца.
Gemini 2.5 (весна 2025) добавил режим рассуждений (Thinking Mode), позволив модели "думать вслух" перед ответом на сложные вопросы. Это особенно помогало в программировании, математике и научных задачах, где важна не скорость, а точность логики. Модель стала лидером в генерации кода и работе с абстрактными концепциями.
Gemini 3.0 (ноябрь 2025) объединил все достижения предшественников и добавил два революционных элемента: генеративный UI (создание интерактивных интерфейсов на лету) и Deep Think (расширенный режим рассуждений для экстремально сложных задач). Теперь модель не просто выдает информацию — она создает целые мини-приложения прямо в ответе: калькуляторы, симуляции, интерактивные графики. Deep Think позволяет решать задачи, которые раньше считались недоступными для AI.
Под капотом Gemini 3 — это мощная мультимодальная архитектура, способная одновременно обрабатывать текст, изображения, видео, аудио и код. Но что это значит на практике? Вы можете загрузить рукописный рецепт на итальянском, видео с лекцией по квантовой физике и таблицу с экспериментальными данными — и модель свяжет все это в единый анализ, не теряя контекста.
Контекстное окно в 1 миллион токенов сохранилось с версии 1.5, но теперь оно работает умнее. Gemini 3 использует динамическое распределение токенов: например, из 256K токенов 180K может пойти на ввод (ваш вопрос и файлы), а 76K — на детальный ответ. Когда лимит близок к исчерпанию, модель применяет прогрессивное сжатие — сжимает старую часть диалога, сохраняя логическую нить последних обменов. Это как умение человека помнить суть разговора, даже если он длится несколько часов.
Мультимодальность достигла нового уровня: модель не просто "видит" видео как набор кадров, а понимает движение, время и контекст. Загрузите видео с баскетбольного матча — Gemini 3 проанализирует технику игроков, предложит план тренировок и даже создаст интерактивную диаграмму слабых мест команды. Или покажите ей старый семейный рецепт, написанный от руки на немецком — модель расшифрует почерк, переведет текст и предложит современную адаптацию с пошаговыми фото.
Производительность выросла не только в бенчмарках, но и в реальной скорости работы. Для мультимодальных задач Gemini 3 работает на 40% быстрее, чем связка из нескольких инструментов у конкурентов. Это значит, что вместо "загрузить картинку → описать → передать в другой инструмент → получить результат" модель делает все в один заход, экономя время и снижая вероятность ошибок.
Gemini 3 Pro занял первое место в рейтинге LMArena с результатом 1501 балл, обойдя предыдущую версию Gemini 2.5 Pro (1451 балл) и всех конкурентов. Это не просто цифры — LMArena представляет собой арену, где пользователи в слепом тестировании сравнивают ответы разных моделей и выбирают лучшие. Победа в таком рейтинге означает, что реальные люди предпочитают Gemini 3, даже не зная, какая модель им отвечает.
В академических тестах результаты впечатляют еще сильнее. Humanity's Last Exam (тест на задачи уровня PhD в разных дисциплинах) модель прошла на 37.5% без использования внешних инструментов — это значит, что больше трети экспертных вопросов, которые ставят в тупик даже докторов наук, Gemini 3 решает самостоятельно. GPQA Diamond (тест на вопросы по физике, биологии и химии для аспирантов) покорился на 91.9% — это практически идеальный результат для задач такой сложности.
MathArena Apex показал рекордные 23.4%, что может звучать скромно, но этот бенчмарк содержит задачи, которые большинство моделей вообще не могут решить. Для сравнения: предыдущее поколение набирало около 15%, так что прирост составил более 50%. В мультимодальных тестах MMMU-Pro (требующих рассуждений на основе изображений и текста) модель достигла 81%, а в Video-MMMU (понимание видео с вопросами) — 87.6%.
Особенно важен результат 72.1% на SimpleQA Verified — это тест фактической точности, где модель должна давать проверяемые ответы, а не красиво звучащую ерунду. Высокий показатель здесь означает, что Gemini 3 реже "галлюцинирует" — придумывает факты, которых нет в реальности.
Deep Think — это не просто "улучшенная версия" Gemini 3, а отдельный режим работы, который выводит производительность на уровень, недоступный обычным моделям. Если обычный Gemini 3 Pro отвечает за секунды, то Deep Think может "думать" несколько минут, тщательно анализируя задачу с разных углов перед финальным ответом.
Результаты говорят сами за себя: Deep Think показал 41.0% на Humanity's Last Exam (без инструментов), 93.8% на GPQA Diamond и беспрецедентные 45.1% на ARC-AGI-2 — тесте, который проверяет способность решать абстрактные задачи, требующие "общего интеллекта". Эти 45.1% — это не просто цифра, это демонстрация того, что модель может находить закономерности в данных, которые не были в ее обучающем наборе.
Как это работает? Deep Think использует архитектуру расширенных рассуждений, где модель внутренне строит цепочки логических шагов, проверяет их на противоречия и корректирует подход перед тем, как дать финальный ответ. Это похоже на то, как математик решает сложную задачу: сначала набрасывает несколько подходов на черновике, оценивает, какой перспективнее, и только потом пишет чистовое решение.
Доступность Deep Think пока ограничена: режим проходит дополнительное тестирование на безопасность и будет доступен подписчикам Google AI Ultra в ближайшие недели после завершения проверок. Это экспериментальная функция, которая может быть приостановлена без предупреждения, поэтому Google просит пользователей активно оставлять фидбэк для улучшения. Чтобы использовать Deep Think, нужна подписка AI Ultra, возраст 18+ и вход в приложение Gemini — после этого под текстовым полем появится иконка Deep Think.
Интересная деталь: пока Deep Think генерирует ответ (это может занять несколько минут), вы можете выйти из чата и заняться другими делами — приложение отправит уведомление, когда ответ будет готов. Это делает режим идеальным для исследовательских задач, где важнее качество, чем скорость: научные расчеты, анализ больших данных, поиск нетривиальных решений в программировании.
➡️➡️➡️ Начать работать с Джемини 3
Здесь начинается по-настоящему футуристичная часть. Gemini 3 не просто отвечает текстом или картинкой — он создает интерфейсы под ваш запрос в реальном времени. Это как если бы вместо ответа "вот формула расчета ипотеки" модель говорила: "вот рабочий калькулятор, введите свои данные и посмотрите результат".
Концепция генеративного UI означает, что интерфейс не существует заранее в виде готового шаблона — он создается на лету на основе контекста вашего вопроса. Спросите про задачу трех тел в физике — получите интерактивную симуляцию, где можно менять параметры и наблюдать траектории. Спросите про сравнение ноутбуков — вместо списка получите визуально насыщенную таблицу с диаграммами, фильтрами и кликабельными элементами.
Примеры в действии: при запросе о планировании отпуска Gemini 3 может создать маршрут в стиле журнала с визуальными эффектами, картами, таймлайном и встроенными подсказками. Вопрос о кредитах породит калькулятор, который учитывает введенные вами данные и показывает графики выплат. Разработчики отмечали случаи, когда пользователи просили создать игру — и модель за один промпт генерировала полностью функциональную 3D-игру с танками.
Интеграция в Google Search (режим AI Mode) делает эту функцию особенно мощной. Когда вы задаете сложный вопрос в поиске, Gemini 3 строит макет с визуальными элементами: изображениями, таблицами, сетками и специально закодированными симуляциями. Это превращает поиск из "списка ссылок" в интерактивный опыт, где ответ — это уже готовое мини-приложение. Пока эта возможность доступна подписчикам Google AI Pro и Ultra, но планируется расширение доступа.
Вместе с Gemini 3 Google запустила Antigravity — агентную среду разработки, которая позволяет AI не просто писать код, а самостоятельно его тестировать, исправлять и доводить до продакшена. Если традиционные AI-ассистенты для кода работают по схеме "вы просите → они пишут → вы тестируете", то Antigravity переворачивает этот процесс: агенты получают прямой доступ к редактору, терминалу и браузеру, и работают как полноценные разработчики.
Агентная среда означает, что AI может планировать многошаговые задачи и выполнять их автономно. Например, вы говорите: "Создай веб-приложение для учета расходов с базой данных и авторизацией" — и агент самостоятельно разбивает задачу на этапы: инициализирует проект, настраивает базу данных, пишет бэкенд, создает фронтенд, тестирует API, исправляет ошибки и даже валидирует код в реальном браузере. Вы видите прогресс в реальном времени, можете вмешаться на любом этапе или дать агенту закончить самостоятельно.
Интеграция с Gemini 3 Pro делает Antigravity особенно мощным: платформа использует модель для понимания контекста задачи, а специализированную модель Gemini 2.5 Computer Use — для управления браузером и симуляции действий пользователя. Это значит, что агент может не просто написать код формы регистрации, но и открыть браузер, зайти на страницу, заполнить поля и проверить, что все работает корректно. Для работы с изображениями платформа использует Nano Banana (модель редактирования изображений от Google).
Практическое применение уже впечатляет: разработчики создают RAG-системы (Retrieval-Augmented Generation), агентные приложения для автоматизации бизнес-процессов и мультимодальные сервисы через Google AI Studio и Vertex AI. Малые команды экономят до 2 часов рабочего времени в день, используя агентов для рутинных задач вроде создания тестов, документации или рефакторинга кода. Enterprise-клиенты применяют Antigravity для сложных исследовательских задач с гарантией надежности 24/7.
Gemini 3 выходит далеко за рамки чат-бота, который просто отвечает на вопросы. Вот реальные сценарии использования, которые демонстрируют его универсальность.
Расшифровка рукописных заметок на разных языках работает даже с плохим почерком и выцветшими чернилами. Загрузите фото старого рецепта вашей бабушки, написанного от руки на французском в 1960-х — Gemini 3 расшифрует текст, переведет его, адаптирует под современные ингредиенты и предложит пошаговую инструкцию с визуализацией. Модель понимает контекст эпохи: если в рецепте упоминается "1 фунт масла", она автоматически переведет в граммы и учтет, что раньше масло было другой жирности.
Анализ академических статей и видеолекций — это область, где контекстное окно в 1 миллион токенов раскрывается полностью. Загрузите двухчасовую лекцию по квантовой механике, три научные статьи и учебник — Gemini 3 свяжет концепции из всех источников, объяснит противоречия между подходами разных авторов и создаст конспект с таймкодами ключевых моментов видео. Студенты сообщают, что это экономит десятки часов при подготовке к экзаменам.
Создание учебных материалов стало интерактивным. Попросите модель объяснить теорему Пифагора — вместо текста получите интерактивную диаграмму, где можно двигать точки треугольника и видеть, как меняются расчеты в реальном времени. Для изучения истории модель создаст таймлайн с картами, датами и связями между событиями.
Анализ спортивных видео — неожиданно популярный кейс. Баскетбольные тренеры загружают записи матчей, и Gemini 3 анализирует технику броска каждого игрока, предлагает упражнения для исправления ошибок и даже создает визуализацию "тепловых карт" — зон, откуда игрок чаще всего промахивается. Для бегунов модель может проанализировать видео с тренировки и указать на проблемы с техникой, которые приводят к травмам.
Создание 3D-игр и приложений за один промпт — это то, что выделяет Gemini 3 среди конкурентов. Пользователи сообщают, что модель создала полностью функциональную 3D-игру с танками, физикой столкновений и управлением — задачу, которую не решила ни одна другая модель. Это работает благодаря комбинации генеративного UI, понимания кода и мультимодальных возможностей.
Gemini 3 глубоко интегрирован с экосистемой Google, что делает его особенно полезным для тех, кто уже использует Gmail, Docs, Sheets и Drive. Это не просто "доступ к файлам" — модель понимает структуру ваших документов, связи между ними и контекст работы.
Работа с Gmail, Docs, Sheets, Drive активируется через настройки приложения Gemini. После включения интеграции модель может читать ваши письма (с вашего разрешения), анализировать документы и предлагать действия на их основе. Например, вы можете написать: "Найди все письма от поставщиков за последний месяц и создай сводную таблицу с ценами" — и Gemini 3 самостоятельно выполнит всю работу, создав таблицу в Sheets со ссылками на исходные письма.
Создание формул и анализ данных в Google Sheets стало проще. Вместо поиска по форумам "как посчитать среднее без выбросов" просто опишите задачу на естественном языке — модель создаст нужную формулу и объяснит, как она работает. Для сложной аналитики Gemini может построить сводные таблицы, графики и даже написать Apps Script для автоматизации.
Обработка больших документов использует контекстное окно на полную: модель может одновременно анализировать до 1,500 страниц текста или 30,000 строк кода. Юристы используют это для анализа контрактов, исследователи — для обзора научной литературы, а разработчики — для рефакторинга легаси-кода.
Управление доступом к файлам остается под вашим контролем. В настройках можно точно указать, к каким папкам и файлам модель имеет доступ, а какие остаются приватными. Для корпоративных клиентов есть возможность полностью отключить функции памяти и интеграцию с файлами для соответствия требованиям compliance.
Google предлагает три уровня доступа к Gemini 3, каждый рассчитан на разные потребности.
Бесплатный план дает возможность попробовать Gemini 3 Pro, но с существенными ограничениями: 5 промптов в день, до 100 изображений в месяц и 5 отчетов Deep Research. Этого достаточно для знакомства с моделью и простых задач, но недостаточно для профессионального использования.
В России доступ к Gemini 3 затруднён, но можно воспользоваться услугами агрегатора нейросетей Study AI.
AI Pro ($19.99-21.99/месяц) — оптимальный вариант для индивидуальных пользователей и малых команд. В подписку входит доступ к Gemini 2.5 Pro (не Deep Think), повышенные дневные лимиты (100,000 токенов в месяц), функция Deep Research, 2 TB хранилища Google One и 1,000 AI-кредитов для генерации изображений и видео. Это примерно 50-70 развернутых диалогов в день или 20-30 часов работы с большими документами в месяц.
AI Ultra ($249.99-274.99/месяц) — премиум-уровень для профессионалов и исследователей. Включает доступ к Deep Think режиму с Gemini 2.5, модель Veo 3 для генерации видео, 25,000 AI-кредитов, YouTube Premium и 30 TB хранилища. Европейским пользователям доступна промо-цена €139.99 на первые три месяца. Этот план подходит для тех, кто регулярно работает со сложными аналитическими задачами, исследованиями или создает большие объемы контента.
API для разработчиков имеет щедрый бесплатный tier через Google AI Studio. По состоянию на ноябрь 2025 года доступ к превью-моделям Gemini 3 Pro предоставляется бесплатно с ограничениями по частоте запросов, которые подходят для прототипирования и тестирования. Платные тарифы API стоят $2 за миллион токенов на входе и $12 на выходе для стандартного уровня — это примерно в 3-5 раз дешевле, чем у конкурентов для задач с большим контекстом.
Google позиционирует Gemini 3 как самую безопасную модель в истории компании. Это не маркетинговое заявление — модель прошла наиболее комплексный набор оценок безопасности среди всех AI-моделей Google.
Комплексное тестирование безопасности включало не только внутренние проверки, но и привлечение независимых экспертов из UK AISI (британское агентство по безопасности AI) и специализированных компаний Apollo, Vaultis и Dreadnode. Каждая из этих организаций проводила стресс-тесты на устойчивость модели к злоупотреблениям.
Устойчивость к prompt injection значительно улучшена по сравнению с предыдущими версиями. Модель распознает попытки манипуляции через скрытые команды в загруженных документах или изображениях и игнорирует их. Также снижена склонность к "угодничеству" (sycophancy) — когда модель соглашается с неверными утверждениями пользователя, чтобы не конфликтовать.
Независимые аудиты проводятся каждые три месяца с публикацией результатов на официальном сайте. Это часть Frontier Safety Framework — программы Google, которая устанавливает строгие критерии безопасности для всех новых моделей. Если модель не проходит какой-то из критических тестов, ее выпуск откладывается до устранения проблем.
Контроль памяти и данных пользователя остается приоритетом. Все предпочтения и данные, которые модель запоминает о вас, можно просмотреть, отредактировать или полностью удалить через настройки. Корпоративные клиенты могут полностью отключить функции памяти и интеграцию с Google Workspace для соответствия GDPR, HIPAA и другим стандартам. Google гарантирует, что данные корпоративных пользователей не используются для обучения моделей.
Gemini 3 вышел в условиях жесткой конкуренции: меньше чем за две недели до этого OpenAI представила GPT-5.1, а за два месяца до того Anthropic анонсировала Claude Sonnet 4.5. Давайте разберем, как модели соотносятся в реальных задачах.
Gemini 3 vs GPT-5.1: В математике и программировании Gemini 3 показывает явное превосходство. На бенчмарке MathArena Apex Gemini набрал 23.4%, когда другие модели (включая GPT-5.1) не выходят за 1.6%. В тесте ScreenSpot-Pro (понимание UI и веб-интерфейсов) Gemini показал 72.7%, что в разы выше конкурентов. GPT-5.1 сохраняет преимущество в чисто креативном письме благодаря динамической адаптации времени на обдумывание и режиму "no reasoning" для быстрых ответов. В бенчмарке SWE-bench (кодирование) GPT-5.1 набрал 76.3% против 72.8% у GPT-5, но Gemini 3 превосходит обе версии в создании сложных SVG-графиков и мультимодальных проектах.
Gemini 3 vs Claude Sonnet 4.5: Claude традиционно силен в анализе кода и длинных текстов, но Gemini 3 обгоняет его в мультимодальных задачах на 15-20%. Claude 4 лучше подходит для задач, требующих следования сложным инструкциям и поддержания строгого формата ответа. Однако для работы с видео, изображениями и интерактивным контентом Gemini 3 не имеет конкурентов.
Скорость: Gemini 3 работает на 40% быстрее в мультимодальных задачах, чем использование нескольких инструментов с GPT-5.1. Для простых задач (например, написание 50-строчного Python-скрипта для очистки данных) Gemini 3 занимает 12 секунд против 25 у Gemini 2.5 — это двукратное улучшение.
Области применения: GPT-5.1 остается лучшим выбором для общих задач и креативного письма, особенно когда нужна естественная, "человечная" интонация. Claude 4 идеален для анализа кода, документации и задач с жесткими форматами. Grok 3 лидирует в задачах, требующих доступа к реальному времени и социальным сетям. Gemini 3 доминирует там, где нужна мультимодальность, длинный контекст, интеграция с Google Workspace и создание интерактивных инструментов.
Разработка RAG-систем и агентных приложений стала основным применением Gemini 3 среди технических специалистов. RAG (Retrieval-Augmented Generation) позволяет модели обращаться к внешним базам знаний для точных ответов, а платформа Apidog стала популярным выбором для работы с Gemini API благодаря эффективной обработке больших загрузок файлов и потоковых ответов.
Создание контента для соцсетей экономит малым командам до 2 часов рабочего времени в день. Маркетологи загружают бриф, референсы и требования бренда — Gemini 3 создает серию постов с визуальными концепциями, адаптированными под каждую платформу (Instagram требует одного стиля, LinkedIn — другого).
Исследовательские задачи для Enterprise используют Deep Think и контекстное окно на полную. Исследовательские команды анализируют климатические данные за 50 лет — работа, которая заняла бы месяцы вручную, выполняется за часы с Gemini 3. Контент-агентства используют модель для конкурентного анализа: загружают блоги, whitepapers и социальный контент конкурентов — Gemini находит пробелы в контенте и возможности.
Генерация мультимодального контента включает создание презентаций с автоматически подобранными изображениями, интерактивных отчетов с встроенными симуляциями и учебных материалов с адаптивными примерами. E-commerce проект решил проблему описаний для 10,000 товаров: вместо $50,000 и шести месяцев работы копирайтеров они использовали мультимодельный подход (Gemini для анализа паттернов, Claude для шаблонов, ChatGPT для генерации, Grok для трендов) и завершили проект за две недели за $500.
Google официально не раскрывает долгосрочных планов, но несколько направлений очевидны из текущих трендов. Интеграция квантовых вычислений упоминается как потенциальная фича Gemini 3.0 или 4.0 для продвинутого научного моделирования. Нативная интеграция с Android и iOS может превратить Gemini в системного ассистента на уровне операционной системы.
Расширение агентных возможностей через платформу Antigravity будет продолжаться: агенты получат доступ к большему количеству инструментов, научатся работать с физическими устройствами через IoT и смогут координировать действия нескольких специализированных агентов одновременно. Улучшение Deep Think режима с сокращением времени обработки и расширением типов задач, которые он может решать.
Voice API и голосовое взаимодействие в реальном времени — область, где Google пока отстает от OpenAI. Добавление суб-секундной голосовой латентности может стать прорывом для Gemini 4.0. Workspace AI Suite может объединить все инструменты Google под единым AI-интерфейсом, превратив Drive, Docs, Sheets и Gmail в полностью интегрированную среду, где агенты автоматизируют рутину.
Gemini 3 — это не просто еще одна AI-модель в бесконечной гонке бенчмарков. Это система, которая реально меняет подход к работе с искусственным интеллектом: от "помощника, который отвечает на вопросы" к "агенту, который понимает задачу и решает ее самостоятельно".
Для кого подходит модель: Если вы работаете в Google Workspace, исследуете большие объемы данных, создаете мультимодальный контент или разрабатываете агентные приложения — Gemini 3 станет вашим основным инструментом. Для чисто творческих задач (написание романов, сценариев) GPT-5.1 может быть лучшим выбором, а для анализа кода с жесткими требованиями — Claude 4. Но для универсальности, скорости и мультимодальности Gemini 3 сейчас лидер рынка.
➡️➡️➡️ Попробовать Google Gemini 3
Чем Gemini 3 отличается от Gemini 2.5?
Gemini 3 добавил генеративный UI (создание интерактивных интерфейсов), улучшенное понимание контекста и намерений пользователя, режим Deep Think для экстремально сложных задач и интеграцию с платформой Antigravity для агентной разработки. Производительность выросла в 2 раза для простых задач и на 15-40% для сложных бенчмарков.
Сколько стоит доступ к Gemini 3?
Бесплатный план — 5 промптов в день, AI Pro — $19.99-21.99/мес (повышенные лимиты, Deep Research, 2TB хранилища), AI Ultra — $249.99-274.99/мес (Deep Think, Veo 3, 25,000 AI-кредитов, 30TB хранилища).
Что такое режим Deep Think?
Deep Think — это расширенный режим рассуждений, где модель "думает" несколько минут перед ответом, анализируя задачу с разных углов. Результаты на 10-20% выше базового Gemini 3 Pro на самых сложных тестах. Доступен только подписчикам AI Ultra.
Можно ли использовать Gemini 3 бесплатно?
Да, бесплатный план дает 5 промптов в день, до 100 изображений в месяц и 5 отчетов Deep Research. API для разработчиков также имеет бесплатный tier с ограничениями по частоте запросов.
Безопасен ли Gemini 3 для корпоративного использования?
Да, модель прошла независимые аудиты от UK AISI, Apollo, Vaultis и Dreadnode, соответствует Frontier Safety Framework и проходит проверки каждые 3 месяца. Корпоративные клиенты могут отключить память и интеграцию с файлами для compliance.
Как получить доступ к API Gemini 3?
Создайте бесплатный API-ключ на aistudio.google.com за 2 минуты. Бесплатный tier подходит для прототипирования, платные тарифы — $2 за миллион входных токенов и $12 за выходные.
Какое контекстное окно у Gemini 3?
1 миллион токенов (около 1,500 страниц текста или 30,000 строк кода) с динамическим распределением между входом и выходом. При превышении лимита применяется прогрессивное сжатие старого контекста.
Мне кажется, что следующим шагом должна быть реализована версия Буревестника с возвращаемым модулем. Очень удобная штука получится.
Взлетела, полетала над нейтральными водами неподалёку от Британии несколько дней (например)... Если там юмор поняли и перестали выёживаться, то вернулась на базу. А если не поняли, то не вернулась 😁

iPhone Air

Очень тонкий телефон
Решила я в марте выйти на подработку. Для этого нужно было сделать медкнижку, но с сентября 2024 начался переход на элМК и купить бумажный бланк уже нельзя. Нигде. О чём в СЭС прям на входе кричали и отвечать на другие вопросы отказывались. На госуслугах есть инструкция, в которой написано: 1) подать заявление 2) пройти осмотр в аккредитованных местах 3) пойти с номером заявления в СЭС. Всё понятно. Потом я начала обзванивать медицинские центры, в городе с населением больше миллиона, выяснилось что элМК делают только в одной компании. Даже в государственной поликлинике не могут отправит данные в госреестр.
Так было в марте. Сейчас август и знакомая столкнулась с той же ситуацией, хотя уже с сентября переход на элМК должен закончиться и я надеюсь станет не так нервно.
Австрийские федеральные железные дороги Österreichische Bundesbahnen (ÖBB) вывели на линию свой новый фирменный поезд NightJet из Вены в Амстердам. В составе поезда помимо обычных купейных вагонов есть вагоны с капсульными купе (Mini Cabins).

Помимо капсул в вагоне есть полноценные купе на 1, 2 и 4 человека.

Есть в Nightjet и большие купе с широкой двуспальной кроватью, своим душем и туалетом.

Личное пространство с запираемой дверью (доступ по NFC-карте).

Багаж и обувь можно спрятать в ящик снаружи под замок.

Внутри капсулы есть всё что нужно: розетки, свет, столик, кондиционер и окно со шторкой. В соседнюю капсулу есть дверца, если вдруг вы едете не один.

ÖBB NightJet - Кровать длиной 188 см с подушкой, простыней и одеялом, которые пассажир раскладывает самостоятельно.

Регулируемый столик для работы или завтрака, лампа для чтения, крючки для одежды, зеркало.

Розетка (европейская, 230 В), USB-порт и беспроводная зарядка для устройств. Регулируемое освещение, включая разноцветную подсветку и кнопку вызова проводника.

Небольшое окно с затемняющей шторой. Есть бесплатный Wi-Fi через портал ÖBB Railnet night с доступом к цифровым газетам и журналам. Окна с улучшенным пропусканием сигнала для стабильной мобильной связи.

В нижних капсулах — есть дополнительное багажное место для багажа под матрасом

Утром стюард приносит завтрак: чай/кофе и булочки с джемом

Стоимость мини-капсулы начинается от €34.90, но может достигать €114.9

В вагоне 40 мест. Для сравнения, в российском купейном вагоне всего 36 мест. Капсулы занимают столько же места, как и обычное купе в этом же вагоне.
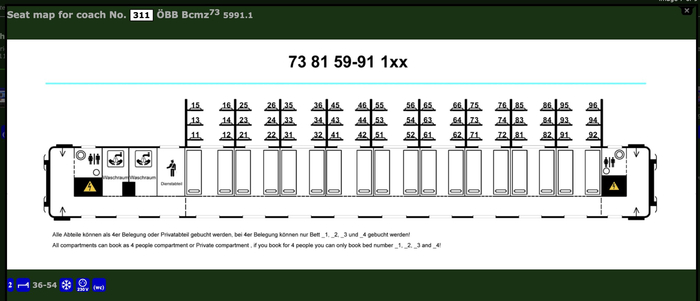
Европейские купе на 6 человек имеют максимальную вместимость 54 человека. Как в российском плацкартном вагоне.
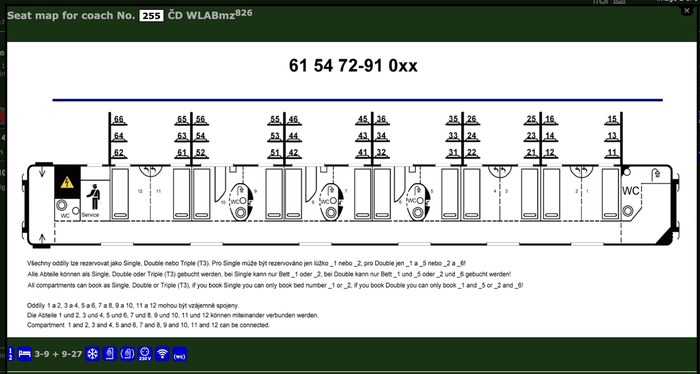
Комбо-Вагоны люкс с душем вмещают максимально 36 человек
Новый NightJet ходит на маршрутах:
Вена — Гамбург
Вена — Амстердам
Инсбрук(Мюнхен) — Амстердам





