Глава 1. Зачем мне универсальная янтра и что именно я из неё извлекаю (наглядный разбор)
Я специально начинаю статью не с «Вихря» и не с L2/L3/L4, а с янтры “любой полярности”, разработанной В. Ленским, по одной причине: без янтры разговор о симметриях и фазах неизбежно превращается в метафоры.
Ниже приведена универсальная янтра.
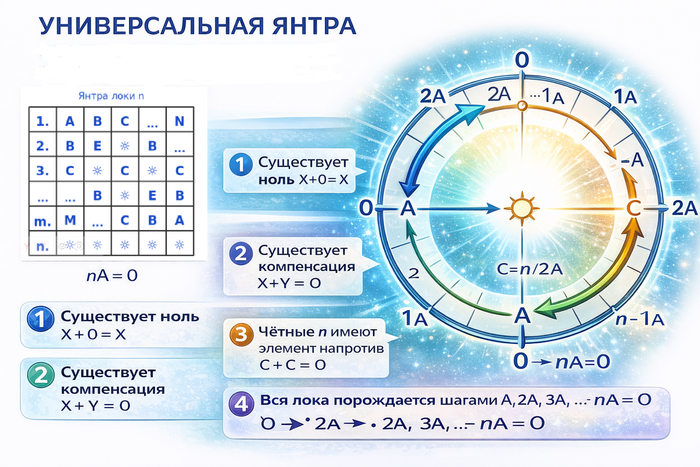
Рис. 1. Универсальная янтра (по: mudrec.us, «Пространство любого числа полярностей», электронный ресурс; дата обращения: 06.01.2026).
Чтение: строка X и столбец Y дают ячейку X*Y.
Выделение оси: найти на диагонали ячейку C*C = SUN (☼).
Замечание: в таблице янтры присутствует специальный маркер SUN (на схеме он обозначен знаком “солнца” ☼). В моей инженерной интерпретации ☼ играет роль маркера оси/замыкания чётной локи. В онтологическом чтении (в терминологии В. Ленского) данный маркер может быть соотнесён с идеей Абсолюта/единства. Далее я использую обозначения как эквивалентные: SUN и [SUN_MARKER]. Знак ☼ — графическое представление маркера на схеме.
Выберите «шаг» A (в терминах янтры — выбранная полярность). Тогда:
берём стартовую метку (условно X0);
считаем X1 = X0 * A — это ровно одна операция чтения по строке X0 и столбцу A;
затем X2 = X1 * A;
далее X3 = X2 * A;
и так далее, пока значения не начнут повторяться.
В таблице это выглядит как движение по строкам при фиксированном столбце A: мы каждый раз остаёмся в одном и том же столбце A, но «спускаемся» в новую строку, равную полученному результату.
Если лока конечна (а янтра именно это фиксирует), то этот процесс неизбежно замкнётся: на некотором шаге мы вернёмся в исходную метку. Это и есть визуальный смысл «замыкания» — он вообще не требует внешней математики, достаточно конечности таблицы.
Маркер SUN (☼) в чётных локах удобнее всего трактовать как визуальную фиксацию оси (или «середины»), потому что он указывает на особый элемент C (наш «средний объект»), для которого выполняется:
C * C = SUN.
В таблице это читается так:
найдите диагональ «элемент на элемент» (ячейки вида X * X);
на этой диагонали ищите ячейку с ☼;
заголовок строки/столбца, в которой стоит ☼ на диагонали, и есть кандидат на C.
Эта процедура важна тем, что она делает «ось чётной локи» не интерпретацией, а операциональным фактом чтения таблицы: я могу указать пальцем на конкретную диагональную ячейку.
Моя задача в этой главе — сделать две вещи:
Показать, что янтра — это не рисунок и не поэтический образ, а конструктивное описание локи (пространства с конечным числом полярностей n).
Перевести её в понятную модель “циферблата”, где каждая полярность — это позиция на круге, а взаимодействие — это шаги по этому кругу.
Зачем это нужно дальше (и почему без этого не обойтись):
Во второй главе я хочу доказательно показать, что янтра “предсказывает” симметрии каждой локи. Но симметрии можно предсказывать только тогда, когда у нас есть ясная структура, относительно которой симметрия определяется. Такой структурой и становится “круг фаз” Z_n.
Для моей архитектуры ИИ это фундаментально: если лока сводится к малому фазовому кругу, то становится возможным то, что я называю компиляцией фаз (дешёвый эпизодический расчёт вместо тяжёлого “языкового перебора”).
Итак, первая глава нужна для того, чтобы зафиксировать базовую “геометрию локи” в простом, проверяемом и вычислимом виде.
Ниже — отображение янтры в читабельном ASCII-виде:
Я записываю каркас так, чтобы было видно три вещи: (а) A как единичный якорь, (б) появление E на диагонали, (в) появление ☼ внутри таблицы и сплошную строку ☼.
ЯНТРА ЛОКИ n (каркас; n — чётное)
| A B C ... N
------+-------------------------
A | A B C ... N
B | B E ☼ B ...
C | C ☼ C ☼ C
... | ... ... B ☼ E B (фрагмент правой части узора)
M | M ... C B A
☼ | ☼ ☼ ☼ ... ☼
Как читать этот ASCII-шаблон
Верхняя строка (A B C ... N) — столбцы, то есть правый аргумент отношения.
Левая метка строки (A, B, C, …, M, ☼) — строки, то есть левый аргумент отношения.
Значение в клетке на пересечении строки X и столбца Y — это результат операции X*Y (именно операции *, а не сложения по модулю).
Минимальные ориентиры, чтобы не “поплыть” по узору:
Строка (и столбец) A в этом представлении играет роль якоря: она воспроизводит подписи (условно: A*X = X и X*A = X в рамках каркаса).
На диагонали видны “самодействия”: например, по рисунку B*B = E (а не ☼).
Маркер ☼ проявляется внутри таблицы как особый результат отношений (например, в каркасе видны клетки типа B*C = ☼ и C*B = ☼).
Нижняя строка ☼ показывает поглощающий характер маркера: при левом аргументе ☼ результат остаётся ☼ (в каркасе это записано как ряд из ☼).
Важно: это не полная таблица n×n, а структурный каркас (узор). Его задача — зафиксировать опорные клетки (якорь A, диагональные самодействия, проявление ☼ и поведение строки ☼), чтобы дальнейшие рассуждения о чётности, “среднем” объекте и симметриях можно было привязывать к конкретным местам таблицы.
Рис. 2. “Циферблат” как индексная схема локи (схематизация автора).
1. Как я представляю локу: “циферблат” из n отметок
Я рассматриваю (чтобы Вам было понятнее) локу размера n как круг из n отметок, где:
одна отметка — это ноль 0 (точка отсчёта);
одна выбранная полярность A — это один шаг по кругу;
дальше я получаю все элементы локи повторением этого шага.
На практике это означает:
0, A, 2A, 3A, ..., (n-1)A
и затем цикл замыкается в индексной модели: nA = 0
Важный момент: я не добавляю ‘внешнюю математику’ к самой янтре; я фиксирую дисциплину конечности и повторения как перевод в Z_n, не отождествляя её с операцией *.
Замечание
Я специально развожу два уровня. (1) Янтра (в изложении В. Ленского) задаёт внутреннее “отношение” полярностей, которое я буду обозначать как *. (2) “Циферблат” Z_n — это индексная модель: способ нумеровать позиции полярностей на круге для вычислимости и контроля фаз. Я не утверждаю, что * тождественно обычному сложению по модулю; “циферблат” нужен как дисциплина фаз и симметрий, а не как подмена самой янтры.
В рамках индексной модели “циферблата” я различаю два класса преобразований.
(i) Симметрии (автоморфизмы) индексной модели. Под симметриями я понимаю автоморфизмы структуры (Z_n, +, 0), то есть биективные отображения f: Z_n -> Z_n, удовлетворяющие условиям f(0) = 0 и f(X + Y) = f(X) + f(Y) для всех X, Y из Z_n. Тем самым фиксируется не только “круг” как множество фаз, но и выделенная нулевая отметка как элемент структуры. Важно подчеркнуть: здесь символ + обозначает индексное сложение по модулю n и не является операцией янтры *.
(ii) Калибровочные переобозначения (аффинные эквивалентности циферблата). Отдельно я рассматриваю калибровочные переобозначения как допустимые перенастройки “координат” циферблата — выбора начала отсчёта и масштаба шага — при которых сохраняется сама циклическая дисциплина фаз. Операционально такие переобозначения задаются аффинными отображениями вида
g(x) = (u*x + t) по модулю n, где НОД(u, n) = 1.
При этом для любых x, y сохраняются фазовые приращения:
g(x) - g(y) = u (x - y) по модулю n для любых x, y из Z_n. Параметр t задаёт перенос начала отсчёта (переназначение нулевой отметки), а параметр u — обратимую перенормировку шага.
Замечание о статусе отображения. При t != 0 такое переобозначение, строго говоря, не является автоморфизмом структуры (Z_n, +, 0), поскольку оно не сохраняет ноль и не является гомоморфизмом сложения в фиксированной точке отсчёта:
g(x + y) = u(x + y) + t по модулю n, тогда как g(x) + g(y) = (ux + t) + (uy + t) = u(x + y) + 2t по модулю n. Именно поэтому в инженерном чтении корректнее трактовать t != 0 как калибровку: она сохраняет не “нулевую отметку как элемент”, а инвариантную структуру фазовых приращений, то есть разности фаз (эквивалентно: сохранение структуры фазовых приращений с точностью до обратимой перенормировки шага).
2. Четыре базовых утверждения
В моём инженерном переводе янтры в индексную модель мне нужны четыре опорных правила:
Правило 1. Ноль обязан существовать
Для любого X:
X + 0 = X.
Смысл: у круга обязана быть точка отсчёта. Без неё нельзя говорить о симметриях, фазах и “центре”.
Правило 2. Должна существовать компенсация (хотя бы одна пара)
Существует хотя бы одна пара X, Y, что:
X + Y = 0.
Смысл: в локе появляется обратимость (минимально). Это зерно симметрий: “вернуться” в ноль можно не только тривиально.
Правило 3. Чётные локи: маркер SUN и “точка напротив” (два уровня).
(а) В терминах янтры (В. Ленский): при чётном n существует “средний” объект C, для которого выполняется C*C = SUN (на картинке обозначено символом ☼). (б) В индексной модели Z_n (циферблат): чётность означает существование позиции на расстоянии n/2 шагов от выбранной нулевой отметки; в аддитивной нумерации фаз это можно записывать как C + C = 0 (здесь + — сложение индексов по модулю n, а не операция янтры *).
Правило 4. Законы отношений зависят от n, но переходы закономерны
Это принципиально: смена n меняет структуру, но не произвольно.
Далее теоремы В. Ленского я пересказываю в индексной записи. Операцию повторения шага в Z_n я обозначаю знаком + как сложение индексов по модулю n.
3. Две теоремы В. Ленского как “алгоритм сборки локи”
Теперь я беру центральную часть — Теорему 5 и Теорему 6, автор которых В. Ленский, — и переписываю их так, как я реально применяю: как конструктивный алгоритм.
3.1. Теорема 5 В. Ленского: одна полярность порождает все остальные
Формулировка по смыслу:
Если в моей индексной записи допускается построение 2A = A + A, то любая полярность получается некоторым числом повторений A.
Я читаю это буквально как процедуру:
берём A;
строим 2A = A + A;
строим 3A = A + 2A;
строим 4A = A + 3A;
и так далее.
То есть все элементы оказываются точками на одной шкале шагов A. Это превращает локу в “циферблат”: не в список разрозненных объектов, а в единый цикл.
3.2. Теорема 6 В. Ленского: длина цикла равна n
Формулировка:
В локе размера n ноль получается как nA = 0.
Я читаю это так:
если элементов ровно n, то шагом A я обойду круг ровно за n шагов;
после n шагов я обязан вернуться в 0, иначе у меня либо больше элементов, либо структура не замкнута.
Именно это делает локу вычислимой: состояние — это не “сложный объект”, а номер отметки на круге.
4. Мини-примеры (чтобы структура стала очевидной)
4.1. n = 2 (двухполярность)
Последовательность: 0 -> A -> 0 (так как 2A = 0).
Здесь сразу видно: A + A = 0. Это максимальная жёсткость: два состояния и мгновенное замыкание.
4.2. n = 3 (трехполярность)
Последовательность: 0 -> A -> 2A -> 0 (так как 3A = 0).
Важно: нет элемента C, такого что C + C = 0. На круге из 3 точек нет “напротив”.
4.3. n = 4 (четырёхполярность)
Последовательность: 0 -> A -> 2A -> 3A -> 0 (так как 4A = 0).
Здесь появляется “средний” элемент:
C = 2A, и действительно C + C = 4A = 0.
На круге это точка ровно напротив нуля.
5. Итог первой главы: что я фиксирую как основу для симметрий
Я подвожу итог в виде трёх тезисов, потому что они напрямую понадобятся во второй главе.
1. Янтра задаёт конечную локу через таблицу отношений *; в моём переводе в индексную модель Z_n это читается как цикл фаз с нулевой отметкой и шагом A, где замыкание индексов выражается как nA = 0
2. По теоремам В. Ленского лока становится порождаемой: каждый элемент — это “некоторое число шагов A”.
3. Чётность n даёт структурный маркер: при чётном n существует точка “напротив” (C + C = 0), при нечётном — нет.
И теперь становится ясно, зачем нужна глава 1: я получил строгую и наглядную модель локи как “циферблата”. Следующий шаг — показать, что симметрии локи — это не произвольные фантазии, а неизбежные преобразования этого циферблата, которые сохраняют ноль, шаг и структуру замыкания.
Глава 2. Что именно янтра предсказывает: симметрии локи как неизбежные преобразования “циферблата”
Введение: что я доказываю во второй главе
В первой главе я сделал одну вещь: я показал, как я перевожу янтру (в изложении В. Ленского) в индексную модель локи размера n — то есть в “циферблат” из n отметок, где есть 0, есть шаг A, и в рамках индексной дисциплины выполняется nA = 0.
Во второй главе я делаю следующий шаг: я показываю, что симметрии локи не придумываются, а следуют из этой конструкции автоматически. Иначе говоря, как только лока построена как цикл, появляется набор преобразований, которые:
сохраняют структуру “круга” (замыкание nA = 0);
переводят допустимые состояния в допустимые;
не разрушают ноль и понятие “шага”, а лишь переопределяют их в допустимых пределах.
Это и есть смысл фразы “янтра предсказывает симметрии”: она задаёт форму, а форма задаёт группу допустимых преобразований.
Далее я различаю автоморфизмы индексной модели (строгие симметрии, f(0)=0) и изоморфизмы-переобозначения (калибровки, допускающие t != 0).
2.1. Что я называю симметрией локи (без философии)
Я определяю симметрию локи так:
Симметрия локи (в смысле индексной модели) — это преобразование, которое переобозначает полярности, не меняя структуры “циферблата”.
На “циферблате” это означает: я могу переобозначить отметки так, что круг останется кругом, а операция “прибавить шаг” сохранит смысл.
Если писать в максимально операциональном виде, то симметрия должна сохранять структуру сложения:
f(X + Y) = f(X) + f(Y),
и, в частности, сохранять ноль:
f(0) = 0.
Здесь знак + обозначает индексную операцию в Z_n (сложение индексов по модулю n) и не является операцией янтры *. Речь идёт о сохранении структуры циферблата как индексной модели.
При этом я разделяю:
Строгие симметрии: f(0)=0 и сохранение индексной операции.
Калибровочные переобозначения: t != 0, g(x) = (u*x + t) по модулю n.
2.2. Первое неизбежное калибровочное переобозначение: циклический сдвиг (вращение круга)
Как только у меня есть круг из n отметок, у меня появляется калибровочное переобозначение (вращение циферблата):
R_k(X) = X + kA,
где k — любое число от 0 до n-1.
Замечание: R_k является калибровкой, а не “строгой симметрией”.
Смысл: я могу “прокрутить” циферблат на k шагов — и структура останется той же. Ноль при этом не сохраняется как конкретная отметка, но сохраняется как роль (после переобозначения). Это важно: в примечании В. Ленского как раз сказано, что “на месте нуля может оказаться любая полярность” при переименовании — это и есть проявление вращательной симметрии как изоморфизма.
Что именно следует из перевода в Z_n: раз индексная модель локи является конечным циклом (nA = 0), она автоматически допускает циклические сдвиги как калибровочные переобозначения (аффинные эквивалентности циферблата).
При этом я допускаю переназначение “нулевой отметки” (калибровку), в связи с чем я рассматриваю аффинные преобразования вида g(x) = (u*x + t) по модулю n, где НОД(u, n) = 1, а условие f(0)=0 относится только к “строгим” симметриям без калибровки.
2.3. Вторая неизбежная симметрия: отражение (смена направления обхода)
На круге всегда возможна операция “идти в обратную сторону”. Это отражение:
S(X) = -X,
то есть элементу на k шагов вперёд соответствует элемент на k шагов назад.
В отличие от сдвига R_k, отражение S сохраняет нулевую отметку и является строгой симметрией индексной модели.
Замечание. В общем виде строгие симметрии индексной модели (Z_n, +, 0) задаются отображениями f_u(x) = u*x по модулю n при условии НОД(u, n) = 1. Отражение S(X) = -X является частным случаем этого семейства (u = -1).
На “циферблате” это выглядит так: отметка на расстоянии k по часовой стрелке переходит в отметку на расстоянии k против часовой.
Почему это не произвол: потому что в локе существует компенсация (хотя бы одна пара X + Y = 0), а после порождения (теорема 5 В. Ленского) это распространяется на всю шкалу: “обратное” становится внутренним понятием цикла.
И вот важная вещь: отражение — это та симметрия, которая соответствует “левому” и “правому” вихрю в моей формулировке. Если вращение — это “прокрутить шкалу”, то отражение — это “сменить ориентацию”.
2.4. Чётные и нечётные локи: что меняется по симметриям
Теперь я делаю ключевое различение, которое напрямую следует из главы 1.
2.4.1. Нечётные n: нет точки “напротив”
Если n нечётно, нет элемента C, такого что C + C = 0.
Значит, у круга нет диаметральной пары, которая фиксировалась бы как “середина”. Это влияет на то, какие преобразования могут иметь фиксированные точки и как устроены инварианты.
Практически:
отражение не имеет “особой” точки, которая была бы одновременно “напротив себя”;
структура симметрий сохраняется как “вращения + отражения”, но без дополнительного выделенного элемента.
2.4.2. Чётные n: появляется выделенный элемент C = n/2
Если n чётно, существует C, что C + C = 0. Это точка напротив нуля.
И вот что важно: появление такого элемента означает, что в локе возникает естественный “маркер середины”, который симметрии обязаны учитывать. В чётной локе некоторые преобразования:
сохраняют C,
или переводят его в себя при отражении (он остаётся напротив нуля при любом переобозначении, если сохраняется структура).
Это даёт мне то, что я в своих терминах называю “внутренним солнцем” как маркером чётной янтры: элемент, который играет роль оси.
Именно поэтому L4 (чётная 4-полярность) обладает теми “жёсткими” свойствами симметрии, которые не так очевидны в L3.
При этом выполнимо "Правило 3". Если n чётно, существует “средний” объект C (по числу полярностей в локе), для которого в янтре выполняется C*C = SUN. В индексной модели это соответствует существованию точки, стоящей “напротив” выбранной нулевой отметки (то есть на расстоянии n/2 шагов).
2.5. “Все симметрии каждой локи” в практическом смысле: два типа преобразований и их композиции
Чтобы не уходить в излишнюю математику, я фиксирую то, что мне нужно для инженерного применения.
Для локи, представленной как цикл из n точек, у меня есть два базовых семейства преобразований:
Вращения R_k: сдвиг на k.
Отражения S: смена ориентации, и затем при необходимости композиция с вращением R_k ∘ S.
Комбинируя эти операции, я получаю полный набор симметрий “циферблата” как геометрического объекта: любое преобразование либо “крутит” круг, либо “крутит и отражает”.
Замечание о смысле “всех симметрий”. В пункте 2.5 я говорю о симметриях циферблата как геометрического цикла (то есть о преобразованиях, сохраняющих структуру кругового обхода — вращениях и отражениях). Строгие же симметрии в смысле автоморфизмов (Z_n, +, 0) описываются семейством f_u(x) = u*x по модулю n при НОД(u, n) = 1 и, вообще говоря, не сводятся к диэдральным симметриям геометрического цикла.
Это и есть практический смысл фразы “янтра предсказывает симметрии”: как только я фиксирую локу в индексной модели Z_n как замкнутый цикл из n фаз, я заранее знаю, какие преобразования допустимы, не разрушая форму локи.
2.6. Почему это критично для Вихря: симметрии превращаются в “таблицу допустимых калибровок”
Теперь я связываю симметрии с тем, что я называю “компилятором калибровки и фаз”.
Если лока в индексном представлении задаётся фазовым кругом Z_n, а симметрии — это допустимые преобразования этого круга, то я могу заранее задать “калибровку” как выбор:
ориентации (правый/левый обход),
нулевой точки отсчёта (где я считаю 0),
шага A (что считаю единичным шагом).
И вот здесь моя инженерная формула:
Вихрь компилирует не “смыслы в слова”, а вход в выбор (ориентация + калибровка нуля + фазовая карта), после чего все проверки становятся проверками согласованности по симметриям.
То, что раньше выглядело как абстрактное “переключение режимов”, становится конкретным: я выбираю допустимое преобразование (из предсказанного янтрой набора) и тем самым фиксирую кадр.
2.7. Итог главы: что именно я получил
Я фиксирую результат в четырёх пунктах:
1. Индексная модель Z_n (как цикл nA = 0) автоматически задаёт вращательные симметрии (сдвиги).
2. Наличие компенсации и ориентации автоматически задаёт отражение (смена направления обхода).
3. Чётность n создаёт структурный маркер C = n/2, который меняет “геометрию инвариантов” локи.
4. Эти симметрии превращаются в таблицу допустимых калибровок для Вихря: выбор нуля, ориентации и шага — это выбор допустимой симметрии.
Глава 3. Как я превращаю янтру в вычислимое ядро: Вихрь как компилятор калибровки и фаз
Введение: зачем нужна третья глава
В главах 1–2 я сделал две вещи:
Показал, как я перевожу янтру (в изложении В. Ленского) в индексную модель “циферблата” Z_n, где: есть 0, есть шаг A, и в рамках индексной дисциплины выполняется nA = 0
Показал, что из этого автоматически следуют симметрии локи: вращения (сдвиги) и отражения (смена ориентации), а также различение чётных и нечётных лок через появление “точки напротив” C, когда n чётно.
Теперь мне нужно сделать третий шаг: показать как эта картина симметрий становится вычислением. То есть: где именно в архитектуре появляется “компилятор”, что он компилирует, и почему такой подход может быть дешевле, чем привычная генерация по типу токенов (единиц последовательностной выдачи текста).
3.1. Главная идея: я компилирую не слова, а эпизод
Я фиксирую принцип, который отличает мой подход от современных языковых моделей.
Современная языковая модель, грубо говоря, живёт в режиме: текст -> вероятности -> следующий токен.
Я строю другой контур: вход -> эпизод -> калибровка -> фазы -> проверки -> ремонт -> предъявимый вывод.
Здесь ключевое слово — эпизод. Эпизод для меня — это минимальный вычислимый фрагмент “мира”, который нужен именно для данного запроса. Он мал по размеру и строго типизирован.
В массовом режиме я не пытаюсь держать “всю Вселенную знаний”. Я строю маленький эпизод и стабилизирую его.
3.2. Что такое “эпизод” в моей архитектуре
Эпизод состоит из четырёх частей:
Узлы V: объекты смысла (термины, сущности, утверждения, роли).
Стыки E: связи между узлами (взаимодействия, переходы, проекции, причинные/функциональные указания — но только в допустимой форме).
Замыкания: гиперсвязи (например, Close3), которые нельзя редуцировать к трём парным рёбрам.
Профиль исполнения: какие локи активны (L2/L3/L4), какой модуль N, какие гейты обязательны, какие ремонты допустимы.
Самое важное: я не “рассуждаю” до тех пор, пока эпизод не собран. Сборка эпизода — это и есть первая стадия компиляции.
3.3. Где в этом месте находится граф, и почему он не должен быть “онлайн”
Чтобы архитектура была конкурентной по стоимости, я развожу два слоя:
Канон (граф-память): большая, версионируемая онтология, реестры гейтов, дефицитов, ремонтов, профилей. Это источник истины и воспроизводимости.
Микроядро (скомпилированный слепок): минимальный набор таблиц и автоматов, который нужен для массового исполнения эпизодов.
Ключевой продуктовый принцип:
Граф нужен для развития системы и доказательной базы, но массовый запрос исполняется на микроядре и малом эпизоде.
Именно поэтому в массовом режиме “граф не мешает”: он почти не участвует в вычислении.
3.4. Что именно компилирует Вихрь: калибровку и фазы
Вихрь как компилятор делает две операции:
выбирает калибровку (кадр согласования),
назначает фазы узлам эпизода.
3.4.1. Почему калибровка вообще нужна
Если я не зафиксировал калибровку, то у меня появляется слишком много “локальных систем координат”. Тогда любое согласование превращается в дорогой перебор интерпретаций.
Калибровка — это запрет произвола: я фиксирую, что считается “нулём”, что считается “шагом”, и какая ориентация считается базовой.
Именно янтра даёт мне законный язык калибровки: любой n задаёт “циферблат”, а симметрии этого циферблата задают допустимые переобозначения.
3.4.2. Назначение фаз как перевод смысла в Z_N
Как только я выбираю модуль N, я ввожу фазовую переменную для узла:
p(v) из Z_N.
Это означает: каждый узел получает позицию на “циферблате” N.
Дальше любая связь превращается в ограничение на разности фаз или в допустимое преобразование фаз.
3.5. Стыки как “разрешённые преобразования” (а не свободные слова)
Я специально фиксирую форму стыка в вычислимом виде. В массовой реализации стык должен быть простым и проверяемым.
Типовой стык я задаю как аффинное преобразование:
g(x) = (u*x + t) по модулю N,
при условии обратимости:
НОД(u, N) = 1.
Смысл условия простой: если множитель u обратим по модулю N, то преобразование не теряет информацию внутри выбранной фазовой шкалы.
Вот где возникает прямое инженерное следствие янтры:
вращения соответствуют сдвигам t,
отражения соответствуют смене ориентации (в простейшем виде — замене x на -x),
их композиции дают допустимое семейство калибровок.
Именно поэтому я говорю, что Вихрь стал компилятором калибровки: он выбирает допустимое g не “по вкусу”, а из структуры симметрий локи.
3.6. Почему L3 не “только про замыкание”, и почему замыкание есть и в L4
Замыкание не является монополией L3. В моём индексном представлении локи как конечного цикла Z_n замыкание выражается формулой nA = 0. Это — дисциплина перевода в индексы, а не отождествление операции янтры * с индексным сложением.
Моя позиция такая:
L3 важно не тем, что “там есть замыкание”, а тем, что там появляется обязательная дисциплина триады: Close3 как объект, который нельзя редуцировать к трём парам. Это точка, где многополярность становится машинно-типизируемой.
L4 добавляет к этому более жёсткий аппарат симметрий (в частности, благодаря чётности и наличию “точки напротив”), и поэтому L4 удобно использовать для строгих проверок стыков и эквивариантности.
Но замыкание как принцип “сборки целого” присутствует в каждом Lk; разница в том, какой минимальный объект замыкания является базовым кирпичом (в L3 — триада, в L4 — четырёхполярная дисциплина и её ограничения симметрий).
3.7. Контур исполнения: как Вихрь реально работает на запросе
Теперь я задаю “жизненный цикл” одного запроса.
Шаг 1. Разметка входа -> сборка эпизода
Я превращаю вход (текст или структуру) в:
узлы V,
стыки E,
замыкания (например, Close3),
профиль (массовый/строгий/исследовательский).
Шаг 2. Выбор N и калибровки
Профиль фиксирует N. В простом конкурентном варианте L2/L3/L4 удобно брать:
N = НОК(2, 3, 4) = 12.
Далее выбирается калибровка (ориентация, ноль, шаг), то есть допустимое преобразование симметрии.
Шаг 3. Компиляция фаз
Я назначаю фазовые переменные p(v) из Z_N и записываю ограничения от стыков и замыканий.
Шаг 4. Прогон гейтов (быстро)
Я прогоняю эпизод через таблицу гейтов микроядра. Гейты проверяют форму и симметрийную корректность:
указан ли режим/проекция там, где это обязательно;
не редуцировано ли замыкание к парам;
нет ли скрытого склеивания (join);
обратимы ли стыки в рамках выбранного N;
согласуются ли стыки с калибровкой.
Шаг 5. Если FAIL — конфликтный цикл и ремонт
Если возникает конфликт, система:
извлекает минимальный конфликтный цикл (на уровне стыков/замыканий),
выдаёт нормированный ремонт (операцию),
и запускает повторную проверку.
Шаг 6. Выход как L2-артефакт + протокол
На выходе пользователь получает:
краткий ответ (артефакт),
статус (PASS, PASS_CORE_ONLY, BLOCK, FAIL),
причину (дефицит),
и, при необходимости, ремонт.
3.8. Минимальные форматы данных (чтобы это было специфицируемо)
Чтобы это превратить в реальный продукт, я фиксирую минимальные JSON-скелеты.
Эти скелеты важны тем, что превращают “разум” в исполнимую дисциплину: есть объект, есть проверка, есть ремонт.
3.9. Почему это может быть дешевле, чем современные ИИ (и где граница)
Я формулирую это без лозунгов.
Мой подход дешевле не всегда, а в определённом классе задач:
когда смысл можно свести к малому эпизоду,
когда достаточно L1–L4 логики,
когда проверка сводится к стыкам/замыканиям/гейтам,
и когда калибровка действительно “сжимает” пространство симметрий.
Тогда стоимость вычисления определяется не “миллиардами параметров”, а размером эпизода:
число узлов,
число стыков,
число замыканий,
число гейтов.
И это как раз то, что позволяет выпустить массовый продукт: я не обязан "прогонять" огромную модель на каждый рутинный запрос, если ядро запроса типизируется и проверяется на малом эпизоде.
3.10. Как я отвечаю на неизбежный вопрос: “а где язык?”
Я не отказываюсь от языкового модуля. Я отказываюсь от идеи, что язык является вычислительным ядром.
В массовом продукте язык остаётся интерфейсом:
лёгкий языковой модуль размечает вход в эпизод,
а вихревое микроядро принимает решение о корректности, конфликте и ремонте.
То есть язык — “ввод/вывод”, а Вихрь — “мышление”.
Итог третьей главы: что изменилось в моём определении Вихря
Я фиксирую итог одной формулой.
Раньше я мог обыденно отмечать: “Вихрь — это идея переключения L2/L3/L4.” Это условно верно в физическом смысле.
Теперь я говорю строго: “Вихрь — это компилятор, который строит эпизод, выбирает калибровку из симметрий янтры, назначает фазы в Z_N и запускает гейты/конфликтный цикл/ремонт до предъявимого результата.”
И именно это превращает “общую идею” в архитектуру готового продукта.
(В продолжение цикла: Фасмер - убийца славянской лингвистики)
Если в первых частях моего цикла, я спорил с Фасмеровскими теориями, то теперь перехожу к спорам с последователями Фасмера от более-менее официальной лингвистики.
Так уж исторически сложилось, что цель всех их умственных усилий - подтвердить теорию позднего происхождение, вторичности и заёмности славянских языков. Вокруг этой идеи и пляшет их мыслительный процесс. (Фасмер тем временем довольно ухмыляется в Вальхалле.)
Как это показать?
Для примера берём готский язык. Поскольку во времена былые готы находились ближе к светочам цивилизации чем славяне, то их язык записан был раньше. А если записан был раньше, то и... Правильно! Решено, что он древнее славянских языков. Далее в работу включаются археологи и СУЖАЮТ ареал распространения славянских племён на тот момент, а спорные моменты опять же решаются в пользу господствующей западнической теории.
Но этого мало. Следующий шаг связан с тем, что у славян и у готов довольно много общих слов и для обоснования "поздноты" славян, часть этих слов надо объявить заёмными у готов.
Как это делается? Элементарно. Ведь у нас ещё и латынь есть под рукой! Берём на рассмотрение самые простые слова такие как: хлеб (hlaifs); котёл (katils); осёл (asinus - гот., asilus - лат.) и подгоняем под существующую теорию. Согласно ей хлеб и хлев славяне переняли у "высокоразвитых" готов, но вот добавлять в конце каждого слова -с или -ус им было лень! Поэтому, переняв хлайфс, катилс у готов и асилус у латинян, они, без всякого пиетета, отбрасывали прочь флексии и пользовались "нормальными" словами хлеб, котёл и осёл.
Подобных примеров ещё много. В связи с этим возникает вопрос: а был ли мальчик? Может изначально были хлеб, котёл и осёл, (пусть даже неславянского происхождения) а потом они уже были переняты славянами, а также латинянами готами и, соответственно со вкусом каждого племени, жаргонизированы и обросли флексиями? Ведь изначально, будем откровенны, предки готов и латинян не были настолько высокоразвитыми племенами от которых стоило бы перенимать слова. (В пользу этого вопроса говорит также и наличие в славянских языках слов хлебать, похлёбка, хлюпать, хлопать которые выводятся из ПИЕ слова).
-Нет, - твёрдо ответят нам лингвисты. - Флексии (эти самые -с, -ус, -ас) свойственны были праиндоевропейскому языку изначально, а поэтому именно славяне переняли эти слова у готов и латинян, которые пользовались близким к ПИЕ произношением.
С подобными труднодоказуемыми утверждениями, "принятыми голосами большинства" спорить трудно, тем более, что данные флексии действительно использовались древнеиндоевропейскими племенами, которые вторгались на Ближний Восток. Но подчеркнем! Не ПИЕ племенами, а древнеиндоевропейскими. То есть, наличие этих флексий именно у ПИЕ не является доказанным.
Поэтому, для начала, мы не будем утверждать первичность именно славянского варианта произнесения спорных слов, а подвергнём сомнению общую гипотезу развития ПИЕ языка на которую опирается официальная лингвистика.
Итак сомнения:
1. Хвалынский нюанс. Так вышло, что единая-неделимая и якобы ПИЕ хвалынская культура, имея в составе гаплогруппы R1a и R1b, распалась точно по этим самым гаплогруппам на ямную и прочие (R1b) и шнуровую (R1a) культуры. Как это получилось без единовременной сдачи генетического анализа? Объяснение может быть только одно: уже в период хвалынской культуры будущие ямники и шнуровики пользовались разными языками и по языкам они и распались. Следовательно Хвалынка была не ПИЕ единством, а союзом нескольких племён.
Вопрос, кто из них использовал флексии?)
2. Хеттский нюанс. Хеттская гаплогруппа не индоевропейская. Однако, почему-то именно хетты объявлены носителями 75% лексики праиндоевропейского языка, что, конечно же, должны учитывать в своих расчётах лингвисты. Кроме генетических, есть и другие свидетельства о крайне сомнительности хеттов, как носителей значительной доли ПИЕ лексики. Рядом исследователей поднимается вопрос о том, что они были носителями жаргонизированной лексики нескольких индоевропейских племен кочевавших на юге Причерноморья.
3. В лингвистике принято место возникновения народов считать местом, где находятся первые наречия языка. Именно поэтому, когда местом возникновения индоевропейцев считалась Анатолия, то анатолийские языки мнились наиболее близкими к ПИЕ.
Сейчас же родина индоевропейцев смещена ближе к славянским языкам, но (вот досада!) славянские языки не считаются близкими к ПИЕ, хотя большой пласт этой лексики в них признаётся всеми.
Латынь и балтские языки, которые являются носителями якобы ПИЕ флексий, возникли наоборот далековато от места рождения предков индоевропейцев. Увы, но это повод усомниться!
4. Балто-славянский нюанс. С огромным удовольствием лингвисты объявили бы о более древнем происхождении балтских языков и значительной близости их к ПИЕ, если бы не сильное родство их со славянскими.
На данный момент, говоря проф. терминологией: временные точки расхождения балт. и слав. языков не выявлены. А то вообще-то важно для сравнения с готскими языками... Сомнения снедают мой разум! Ведь балтский - носитель флексий...
Уже четырёх перечисленных пунктов должно хватить, чтобы поставить рассуждения лингвистов о взаимодействии готских и славянских языков на паузу. Если этого недостаточно проходим дальше.
Аргументик. На данный момент славянская лингвистика ущербна и недоразвита, целиком погрузившись в идею заёмности славянских слов. Она фактически игнорирует некоторые реконструируемые славянские слова такие как "кресь", "мудра", "жига" и т.п. (про отсутствие энтих словес в письм. источниках знаем-с!). Налицо вульгарная непроработка всех вариантов развития славян. языков в угоду одной гипотезы.
Аргументец. Есть такое слово как dentes - зубы по-латински. По-литовски - dantas. Славяне - это слово действительно взяли себе, но только обозначили им не зубы а дёсны (у языковедьмы есть об этом статья). Тут мы видим, что они не избавлялись от ПИЕ (якобы) флексий, а попросту жаргонизировали для более удобного звучания, отчего слово стало похожим на десницу (правую руку). Это должно сказать о том, что к флексиям славяне не испытывали отвращения. И, если бы флексии действительно были в словах: хлеб, котёл, осёл и прочих, то они, скорее всего, вылезли бы в заёмных конструкциях.
Следующий аргументище. Прииск Паннийский в "Истории готов" пишет, что гунны пили на пирах "медас и кейвас". Однако слово "мёд" считается праиндоевропейским, выводится из madhu и флексий отродясь не имело. Это слово дошло аж до Китая и считается свидетельством воздействия индоевропейцев на пракитайские племена. То есть тут мы видим что готы, (устами Приска Паннийского?) взяли славянское слово и снабдили его своей любимой флексией, превратив в медас. Естественно с ещё большей силой возникает вопрос что возможно котёл, осёл и хлеб тоже обзавелись флексиями которые изначально им были не свойственны. А вы как думаете?)
Это ещё не всё: смотрим на географию - завоевания готов весьма значительны, но земли, которые они контролировали, заселяли всё-таки предки славян, поскольку именно там резко и быстро возникают славянские племена. Мы должны учитывать тот момент, что готы возможно были субэтносом (смесью балто-славяно-германцев) и только правящей верхушкой, которая взимала с ещё не организованных славян дань и рабов. А значит именно готы заимствовали слова у более хозяйственных, хоть и подчинённых славян.
Не проработав эту гипотезу до конца, судить с уверенностью, что славяне брали слова у готов, будет крайне опрометчиво, а по сути ненаучно.
На основании всего написанного, мы должны... Должны? Да просто обязаны! вывести следующие гипотезы:
1. Распад ПИЕ произошёл раньше Хвалынской культуры.
2.Предки языков европейских языковых семей образовались на просторах сев. Причерноморья и уже оттуда их носители мигрировали в Европу.
3. Жаргонизация, и взаимообмен словами, сыграли не меньшую роль в формировании европейских языков чем гипотетический "распад ПИЕ".
4. Славянские языки находятся ближе к "прародине" индоевропейцев, а посему волей-неволей мы должны рассмотреть гипотезу их большей близости к "ПИЕ"
5. Готский, вандальский языки не являются продуктом распада "балтогерманославянского" наречия. Возможно ли их образование в результате взаимной жаргонизации балт., герм., слав., лат. языков?
Ах, да!
Статья эта была навеяна спором с девушкой, которая ведёт тг канал по лингвистике, после которого меня с этого самого канала и вышвырнули. К счастью остались ещё каналы на Пикабу и в дзене на которых я, по её выражению, продолжаю пастись)). Тут я выложил некоторые вопросы, которые возникли после прочтения статей по готскому языку именно у НЕПРОФЕССИОНАЛА интересующегося историей. И которые я хотел бы задать если не ей, то почтенной публике в "Лиге историков". С позволения строгой модерации естественно.
А если не судьба, то не судьба 💁♂️
Напоследок. К самой деятельности " Языковедьмы" отношусь положительно. Статьи, особенно про древний Восток, читаю с удовольствием.
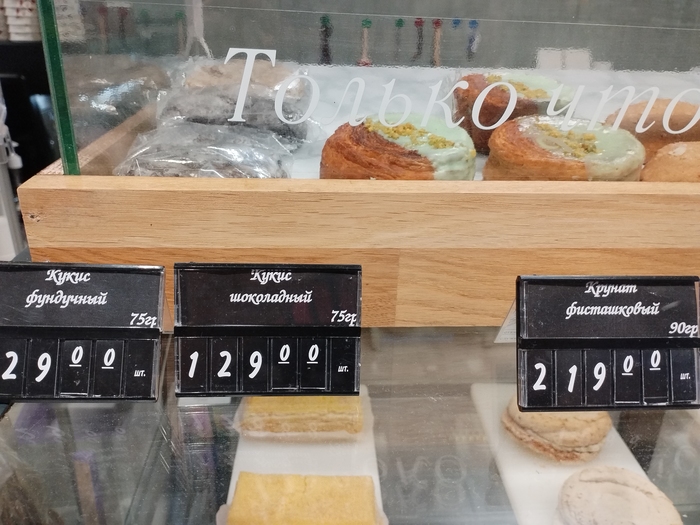
Я не большой любитель выпивать кофе по утрам в кафе, вприкуску с булочками. Но порой судьба подталкивает. Или лень. Или деньги ляжку жгут, думаешь, могу ж себе позволить. в итоге за свои же рубли свой же пердак подпалил.
Вот стою перед витриной, выбирая чем завтракать: кукис или крунит? Сука, это че ваще за названия? Из какой жопы они выскочили то? Чтоб несведущий читатель понимал, под кукисом подразумевалось обычная печенюха типа овсяной. А крунитом обозвали слоеную булочку типа улитки.
Неужели с маркетинговой точки зрения введение этих непонятных терминов хоть как то повышает продажи? Мне было лень выговаривать эти ку-ку, попросил вафлю со сгущёнкой. Она, кстати, оказалась, весьма посредственной. Лучше б повара нормального наняли, чем маркетолога дебильного. Вот так люди гробят пол жизни на посещение репетитора по-английскому, а потом полученный (крохотный) багаж знаний пихают в каждую не сильно предназначенную для этого щель.